
TensorFlow的序列模型程式碼解釋(RNN、LSTM)
1、學習單步的RNN:RNNCell、BasicRNNCell、BasicLSTMCell、LSTMCell、GRUCell
(1)RNNCell
如果要學習TensorFlow中的RNN,第一站應該就是去了解“RNNCell”,它是TensorFlow中實現RNN的基本單元,每個RNNCell都有一個call方法,使用方式是:(output, next_state) = call(input, state)。
藉助圖片來說可能更容易理解。假設我們有一個初始狀態h0,還有輸入x1,呼叫call(x1, h0)後就可以得到(output1, h1):
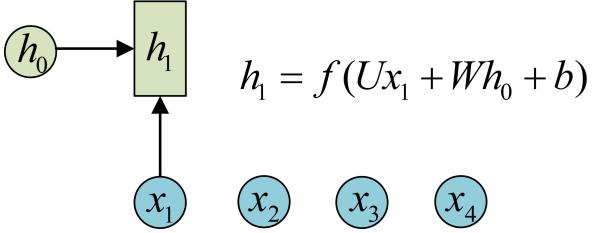
再呼叫一次call(x2, h1)就可以得到(output2, h2):
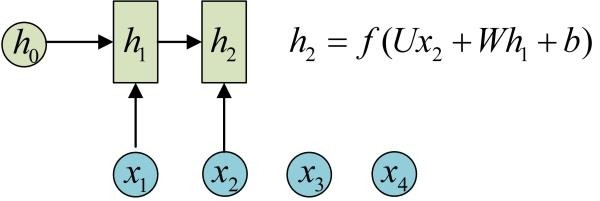
也就是說,每呼叫一次RNNCell的call方法,就相當於在時間上“推進了一步”,這就是RNNCell的基本功能。
(2)BasicRNNCell和BasicLSTMCell
在程式碼實現上,RNNCell只是一個抽象類,我們用的時候都是用的它的兩個子類BasicRNNCell和BasicLSTMCell。顧名思義,前者是RNN的基礎類,後者是LSTM的基礎類。這裡推薦大家閱讀其原始碼實現(地址:http://t.cn/RNJrfMl),一開始並不需要全部看一遍,只需要看下RNNCell、BasicRNNCell、BasicLSTMCell這三個類的註釋部分,應該就可以理解它們的功能了。
除了call方法外,對於RNNCell,還有兩個類屬性比較重要:
-
-
-
state_size
-
output_size
-
-
前者是隱層的大小,後者是輸出的大小。比如我們通常是將一個batch送入模型計算,設輸入資料的形狀為(batch_size, input_size),那麼計算時得到的隱層狀態就是(batch_size, state_size),輸出就是(batch_size, output_size)。
(3)LSTMCell:
這個類有實現clipping,projection layer,peep-hole等一些lstm的高階變種,BasicLSTMCell僅作為一個基本的basicline結構存在,如果要使用這些高階variant要用LSTMCell這個類。
(4)例子:
tf.contrib.rnn.BasicLSTMCell:單步的LSTM【LSTMCell】就是下圖藍色框框中的一個。多次呼叫該函式實現RNNcell就可以實現了時間序列,以下函式dynamic_rnn可以實現迴圈呼叫。
BasicLSTMCell(num_units,forget_bias=1.0,state_is_tuple=True,activation=None,reuse=None)
-
-
- state_is_tuple 官方建議設定為True。每個lstm cell在t時刻都會產生兩個內部狀態ct和ht。如果state_is_tuple=True,那麼狀態ct和ht就是分開記錄,放在一個tuple中,如果這個引數沒有設定或設定成False,兩個狀態就按列連線起來,成為[batch, 2n](n是hidden units個數)返回。官方說這種形式馬上就要被deprecated了,所有我們在使用LSTM的時候要加上state_is_tuple=True,此時,輸入和輸出的states為c(cell狀態)和h(輸出)的二元組。
- forget_bias遺忘門的初始值設為 1,一開始不能遺忘
- num_units:num_units這個引數的大小就是LSTM輸出結果的維度。例如num_units=128, 那麼LSTM網路最後輸出就是一個128維的向量。
-

https://blog.csdn.net/notHeadache/article/details/81164264 對引數的解釋很清楚。
2、initial states初始狀態:初始時全部賦值為0狀態。
需要有一個self._initial_state來儲存我們生成的全0狀態,最後直接呼叫cell的zero_state()方法即可。
self._initial_state = cell.zero_state(batch_size, tf.float32)
state_size是我們在定義cell的時就設定好了的,只是我們的輸入input shape=[batch_size, num_steps],我們剛剛定義好的cell會依次接收num_steps個輸入然後產生最後的state(n-tuple,n表示堆疊的層數)但是一個batch內有batch_size這樣的seq,因此就需要[batch_size,s]來儲存整個batch每個seq的狀態。
3、DropoutWrapper:
對於rnn的部分不進行dropout,也就是說從t-1時候的狀態傳遞到t時刻進行計算時,這個中間不進行memory的dropout;僅在同一個t時刻中,多層cell之間傳遞資訊的時候進行dropout

上圖中,xt−2時刻的輸入首先傳入第一層cell,這個過程有dropout,但是從t−2時刻的第一層cell傳到t−1,t,t+1的第一層cell這個中間都不進行dropout。再從t+1時候的第一層cell向同一時刻內後續的cell傳遞時,這之間又有dropout了。因此,我們在程式碼中定義完cell之後,在cell外部包裹上dropout,這個類叫DropoutWrapper,這樣我們的cell就有了dropout功能!
例子:
if is_training and config.keep_prob < 1:
lstm_cell = tf.nn.rnn_cell.DropoutWrapper ( cell, input_keep_prob = 1.0,output_keep_prob=config.keep_prob ,seed = None)
引數有input_keep_prob和output_keep_prob,也就是說裹上這個DropoutWrapper之後,如果我希望是input傳入這個cell時dropout掉一部分input資訊的話,就設定input_keep_prob,那麼傳入到cell的就是部分input;如果我希望這個cell的output只部分作為下一層cell的input的話,就定義output_keep_prob。不要太方便。
根據Zaremba在paper中的描述,這裡應該給cell設定output_keep_prob。
4、學習如何一次執行多步:有四個函式可以用來構建rnn.
(1)tf.nn.dynamic_rnn
dynamic_rnn:基礎的RNNCell有一個很明顯的問題:對於單個的RNNCell,我們使用它的call函式進行運算時,只是在序列時間上前進了一步。比如使用x1、h0得到h1,通過x2、h1得到h2等。這樣的h話,如果我們的序列長度為10,就要呼叫10次call函式,比較麻煩。對此,TensorFlow提供了一個tf.nn.dynamic_rnn函式,使用該函式就相當於呼叫了n次call函式。即通過{h0,x1, x2, …., xn}直接得{h1,h2…,hn}。
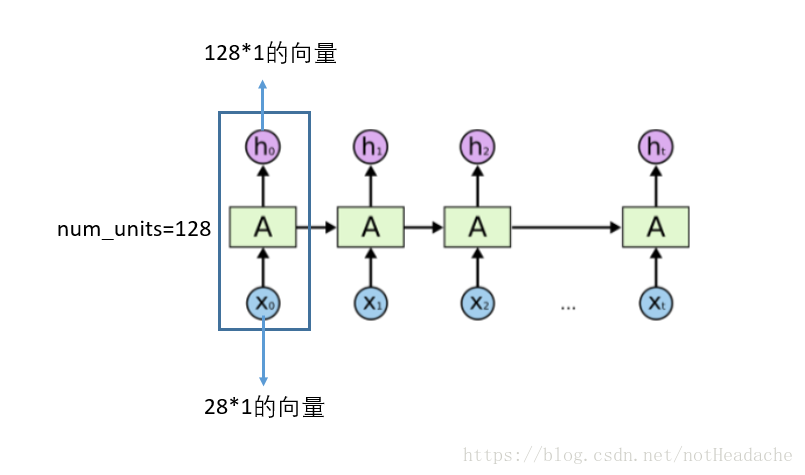
-
- cell: RNNCell 例項。
- inputs: RNN輸入。如果time_major==False(預設),必須要是形如[batch_size,max_time]的張量, 或者這些元素的巢狀元組。 如果
time_major == True,必須是形如[max_time, batch_size, ...]的張量, 或者這些元素的巢狀元組. 這也可能是一個滿足這個屬性的(可能巢狀的)張量元組. 前兩個維度必須匹配所有輸入,否則排名和其他形狀元件可能會有所不同. 在這種情況下,每個時間步的單元輸入將複製這些元組的結構,除了時間維(從中獲取時間)。 在每個時間步的單元格輸入將是張量或(可能巢狀的)張量元組,每個張量元素的尺寸為[batch_size,...]。 - initial_state: (可選)RNN的初始狀態。 如果cell.state_size是一個整數,則它必須是形如 [batch_size,cell.state_size]的張量。 如果cell.state_size是一個元組,它應該是一個在cell.state_size中具有形狀[batch_size,s]的張量元組。
- time_major: 輸入和輸出張量的形狀格式,如果time_major == True,則這些張量必須為[max_time,batch_size,depth]。 如果為false,則這些張量必須為[batch_size,max_time,depth]。 使用time_major = True可以提高效率,因為它避免了RNN計算開始和結束時的轉置。 但是,大多數TensorFlow資料都是批處理主資料,所以預設情況下,此功能接受輸入並以批處理主要形式發出輸出。
- 輸出:output:RNN輸出張量。如果time_major == False (default),輸出張量形如
[batch_size, max_time, cell.output_size]。如果time_major == True, 輸出張量形如:[max_time,batch_size,cell.output_size]。
注:如果如果cell.output_size是整數或TensorShape物件的一個(可能是巢狀的)元組,則輸出將是與cell.output_size具有相同結構的元組,其包含與具有與cell.output_size中的形狀資料相對應的形狀的張量。
-
輸出:state:最終狀態。 如果cell.state_size是一個int,這將被shaped [batch_size,cell.state_size]。 如果它是一個TensorShape,這將形成[batch_size] + cell.state_size。 如果它是一個(可能是巢狀的)int或TensorShape的元組,它將是一個具有相應形狀的元組。 如果單元是LSTMCells狀態將是包含每個單元的LSTMStateTuple的元組。
(2)tf.nn.rnn
這個函式和dynamic_rnn的區別就在於,這個需要的inputs是a list of tensor,這個list的長度是num_steps,也就是將每一個時刻的輸入切分出來了,tensor的shape=[batch_size, input_size]【這裡的input每一個都是word embedding,因此input_size=hidden_units_size】除了輸出inputs是list之外,輸出稍有差別。輸出也是一個長度為T(num_steps)的list,每一個output對應一個t時刻的input(batch_size, hidden_units_size),output shape=[batch_size, hidden_units_size]
(3)state_saving_rnn:
這個方法可以接收一個state saver物件,這是和以上兩個方法不同之處,另外其inputs和outputs也都是list of tensors。
(4)bidirectional_rnn:
研究bi-rnn網路的時候再說。
5、學習如何堆疊RNNCell:MultiRNNCell
很多時候,單層RNN的能力有限,我們需要多層的RNN。將x輸入第一層RNN的後得到隱層狀態h,這個隱層狀態就相當於第二層RNN的輸入,第二層RNN的隱層狀態又相當於第三層RNN的輸入,以此類推。在TensorFlow中,可以使用tf.nn.rnn_cell.MultiRNNCell函式對RNNCell進行堆疊,
cell = tf.nn.rnn_cell.MultiRNNCell([lstm_cell] * config.num_layers, state_is_tuple=True)
值得學習的地方:
(1) 設定is_training這個標誌
這個很有必要,因為training階段和valid/test階段引數設定上會有小小的區別,比如test時不進行dropout
(2) 將必要的各類引數都寫在config類中獨立管理
這個的好處就是各類引數的配置工作和model類解耦了,不需要將大量的引數設定寫在model中,那樣可讀性不僅差,還不容易看清究竟設定了哪些超引數
RNN 小結:
截至目前,TensorFlow的RNN APIs還處於Draft階段。不過據官方解釋,RNN的相關API已經出現在Tutorials裡了,大幅度的改動應該是不大可能,現在入手TF的RNN APIs風險應該是不大的。
目前TF的RNN APIs主要集中在tensorflow.models.rnn中的rnn和rnn_cell兩個模組。其中,後者定義了一些常用的RNN cells,包括RNN和優化的LSTM、GRU等等;前者則提供了一些helper方法。
建立一個基礎的RNN很簡單:
1 from tensorflow.models.rnn import rnn_cell 2 3 cell = rnn_cell.BasicRNNCell(inputs, state)
建立一個LSTM或者GRU的cell?
1 cell = rnn_cell.BasicLSTMCell(num_units) #最最基礎的,不帶peephole。 2 cell = rnn_cell.LSTMCell(num_units, input_size) #可以設定peephole等屬性。 3 cell = rnn_cell.GRUCell(num_units)
呼叫呢?
output, state = cell(input, state)
這樣自己按timestep呼叫需要設定variable_scope的reuse屬性為True,懶人怎麼做,TF也給想好了:
state = cell.zero_state(batch_size, dtype=tf.float32)
outputs, states = rnn.rnn(cell, inputs, initial_state=state)
再懶一點:
outputs, states = rnn.rnn(cell, inputs, dtype=tf.float32)
怕overfit,加個Dropout如何?
cell = rnn_cell.DropoutWrapper(cell, input_keep_prob=0.5, output_keep_prob=0.5)
做個三層的帶Dropout的網路?
cell = rnn_cell.DropoutWrapper(cell, output_keep_prob=0.5) cell = rnn_cell.MultiRNNCell([cell] * 3) inputs = tf.nn.dropout(inputs, 0.5) #給第一層單獨加個Dropout。
一個坑——用rnn.rnn要按照timestep來轉換一下輸入資料,比如像這樣:
inputs = [tf.reshape(t, (input_dim[0], 1)) for t in tf.split(1, input_dim[1], inputs)]
rnn.rnn()的輸出也是對應每一個timestep的,如果只關心最後一步的輸出,取outputs[-1]即可。
注意一下子返回值的dimension和對應關係,損失函式和其它情況沒有大的區別。
目前飽受詬病的是TF本身還不支援Theano中scan()那樣可以輕鬆實現的不定長輸入的RNN,不過有人反饋說Theano中不定長訓練起來還不如提前給inputs加個padding改成定長的訓練快。
摘自 https://www.leiphone.com/news/201709/QJAIUzp0LAgkF45J.html
摘自 https://www.cnblogs.com/mfryf/p/7874784.html
摘自 https://www.cnblogs.com/mfryf/p/7874742.html