Linux 搭建Hadoop叢集 成功
內容基於(自己的真是操作步驟編寫)
一:下載安裝 Hadoop
1.1:下載指定的Hadoop
hadoop-2.8.0.tar.gz

1.2:通過XFTP把檔案上傳到master電腦bigData目錄下
1.3:解壓hadoop壓縮檔案
tar -xvf hadoop-2.8.0.tar.gz
1.4:進入壓縮檔案之後 複製路徑
/bigData/hadoop-2.8.0
1.5:配置Hadoop的環境變數
vim /etc/profile

新增如下配置:

export HADOOP_HOME=/usr/bigdata/hadoop/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
讓檔案生效:
wq!儲存並退出
source /etc/profile讓檔案生效

二:Hadoop叢集的配置
2.1:進入hadoop的配置檔案位置
進入hadoop配置檔案目錄
cd hadoop2.8.0/etc/hadoop/

2.2:配置hadoop-env.sh檔案
vim hadoop-env.sh
加入如下配置:
export JAVA_HOME=/usr/bigdata/java/jdk1.8.0_121
2.3:配置yarn-env.sh檔案
vim yarn-env.sh
加入如下配置:
export JAVA_HOME=/usr/bigdata/java/jdk1.8.0_121
2.4:配置slaves檔案,增加slave主機名或者IP地址
01.vim slaves
刪除原有localhost,加入子機器名稱或者ip地址
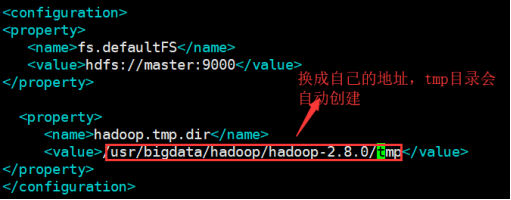
2.5:配置core-site.xml檔案
01.vim core-site.xml
02.在
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/bigdata/hadoop/hadoop-2.8.0/tmp</value>
</property>
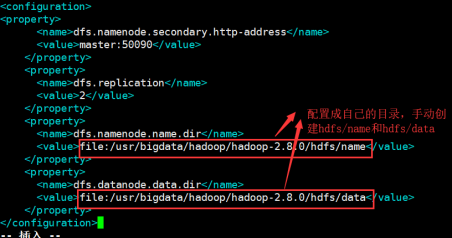
2.6:配置hdfs-site.xml檔案
vim hdfs-site.xml
在configuration節點下加入如下配置:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/bigdata/hadoop/hadoop-2.8.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/bigdata/hadoop/hadoop-2.8.0/hdfs/data</value>
</property>
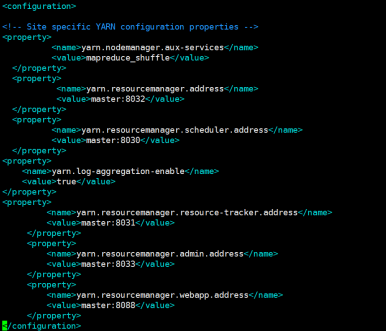
2.7:配置yarn-site.xml檔案
在configuration節點下加入如下配置:
vim yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
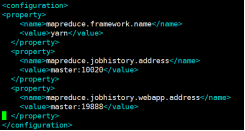
2.8:配置mapred-site.xml檔案
mapred-site.xml.template存在
mapred-site.xml不存在
先要copy一份
cp mapred-site.xml.template mapred-site.xml
然後編輯
vim mapred-site.xml
在configuration節點下加入如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
2.9:把配置好的hadoop檔案複製到其他的子機器中
scp -r /usr/bigdata/hadoop/hadoop-2.8.0 [email protected]:/usr/bigdata/hadoop
scp -r /usr/bigdata/hadoop/hadoop-2.8.0 [email protected]:/usr/bigdata/hadoop
3.0把配置好的/etc/profile複製到其他兩個子機器中
scp /etc/profile [email protected]:/etc/profile
scp /etc/profile [email protected]:/etc/profile
分別在兩個子機器中應用/etc/profile
source /etc/profile
3.1:在master 主機器中執行
hdfs namenode -format
3.2:在master 主機器中啟動hadoop環境
進入/usr/bigdata/hadoop/hadoop-2.8.0/sbin
./start-all.sh 啟動hadoop叢集
./stop-all.sh 關閉hadoop叢集
3.3:jps
vim jps

3.4:啟動JobHistoryServer
./mr-jobhistory-daemon.sh start historyserver

訪問頁面:
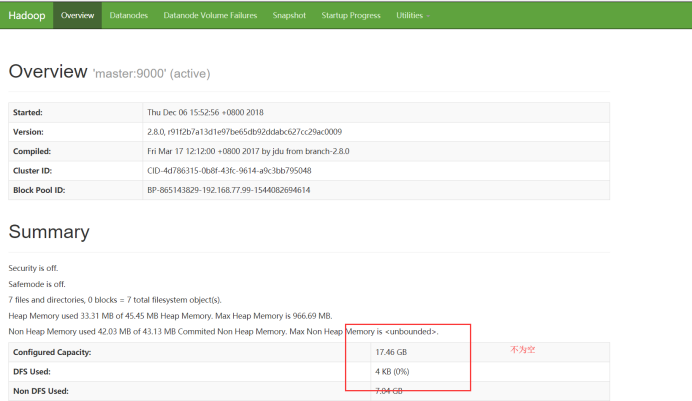


Hadoop叢集搭建成功
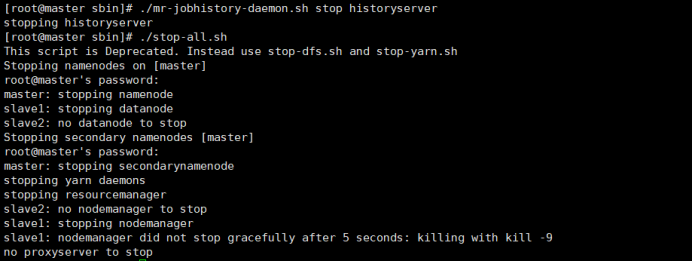
3.5關閉:
第一步:
關閉JobHistoryServer
./mr-jobhistory-daemon.sh stop historyserver
第二步:
關閉hadoop叢集
./stop-all.sh