
從零開始搭建hadoop叢集
創作不易,請勿抄襲,轉載請註明出處。如有疑問,請加微信 wx15151889890,謝謝。
[本文連結:]https://blog.csdn.net/wx740851326/article/details/https://blog.csdn.net/wx740851326/article/details/83749163
本文主要記敘瞭如何在centos7.2上搭建cdh平臺,使用mysql為元資料管理庫(官方推薦),安裝了Spark2和Kafka元件。
一、軟體準備
- cdh5.13.3-centos7.tar.gz cm5.13.3-centos7.tar.gz
SPARK2_ON_YARN-2.3.0.cloudera3.jar
SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809-el7.parcel
CDH-5.13.3-1.cdh5.13.3.p0.2-el7.parcel
KAFKA-3.1.0-1.3.1.0.p0.35.parcel
SPARK2-2.3.0.cloudera3-1.cdh5.13.3.p0.458809-el7.parcel.sha
CDH-5.13.3-1.cdh5.13.3.p0.2-el7.parcel.sha
KAFKA-3.1.0-1.3.1.0.p0.35.parcel.sha JDK:jdk-8u181-linux-x64.tar.gz
二、修改作業系統配置
- 關閉selinux
vi /etc/selinux/configvi /etc/selinux/config
將SELINUX=enforcing改為SELINUX=disabled
-
關閉防火牆
systemctl stop firewalld
systemctl disable firewalld
service iptables stop
chkconfig iptables off -
安裝必須的yum包
yum -y install postgresql-server
yum -y install postgresql
yum -y install httpd
yum -y install perl
yum -y install bind-utils
yum -y install libxslt
yum -y install cyrus-sasl-gssapi
yum -y install redhat-lsb
yum -y install cyrus-sasl-plain
yum -y install portmap
yum -y install fuse
yum -y install fuse-libs
yum -y install nc
yum -y install python-setuptools
yum -y install python-psycopg2
yum -y install MySQL-python
yum -y install mod_ssl
yum -y install ssh
yum -y install ntp
yum -y install wget -
移除自帶的openjdk
rpm -qa |grep jdk
yum -y remove 《》 #移除包 -
移除自帶的mariadb
rpm -qa |grep mariadb
yum -y remove 《》 #移除包 -
修改hosts檔案
vi /etc/hosts
配置主機名ip地址 -
設定交換空間為0
echo “vm.swappiness=0” >> /etc/sysctl.conf
提升hdfs的讀寫效率 -
配置ssh 免密通道
ssh-keygen -t rsa一鍵回車
ssh-copy-id -i hadoop01
ssh-copy-id -i hadoop02
ssh-copy-id -i hadoop03
ssh hadoop01
ssh hadoop02
ssh hadoop03 -
配置ntp伺服器
vi /etc/ntp.conf
master上 配置server 127.127.1.0
slaver上配置 server -
安裝jdk
將jdk的壓縮包放置在/usr/java/jdk1.8
tar -zvxf jdk-8u181-linux-x64.tar.gz
mv jdk1.8.0_181 jdk1.8
vi /etc/profile 寫入以下指令碼
export JAVA_HOME=/usr/java/jdk1.8
export JAVA_HOME=/usr/java/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
完成後source /etc/profile
javac java –version檢驗安裝情況 -
解壓cdh檔案至/var/www/html/下(master)
tar -zvxf cdh5.13.3-centos7.tar.gz
tar -zvxf cm5.13.3-centos7.tar.gz
-
配置本地yum源
vi /etc/yum.repos.d/cm.repo
[cloudera-manager]
name=Cloudera Manager
baseurl= http://hadoop01:/cm/5.13.3/
gpgcheck = 0
enabled = 1
vi /etc/yum.repos.d/cdh.repo
[cloudera-cdh5]
name=CDH
baseurl= http://hadoop01:/cdh/5.13.3/
enable=1
gpgcheck = 0 -
配置服務開機自啟動
service ntpd start
chkonfig ntpd on
service iptables stop
chkconfig iptables off
service httpd start
chkconfig httpd on -
機器重啟
-
檢查ntp,http服務是否啟動成功
-
檢查ntp服務是否正常
ntpq -pntpq -p
三、資料及CDH服務安裝
-
安裝mysql,建立相應的資料庫並賦權(master)
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
rpm -ivh mysql-community-release-el7-5.noarch.rpm
yum install -y mysql-server
yum install -y mysql-devel
yum install -y mysql-connector-java
service mysqld start
/usr/bin/mysql_secure_installation
create database cm default character set utf8;
create user ‘cm’@’%’ identified by ‘123456’;
grant all privileges on cm.* to ‘cm’@’%’ with grant option; flush privileges;create database hive default character set utf8;
create user ‘hive’@’%’ identified by ‘123456’;
grant all privileges on hive.* to ‘hive’@’%’;flush privileges;create database rm default character set utf8;
create user ‘rm’@’%’ identified by ‘123456’;
grant all privileges on rm.* to ‘rm’@’%’;flush privileges;create database sentry default character set utf8;
create user ‘sentry’@’%’ identified by ‘123456’;
grant all privileges on sentry.* to ‘sentry’@’%’;flush privileges;create database oozie default character set utf8;
create user ‘oozie’@’%’ identified by ‘123456’;
grant all privileges on oozie.* to ‘oozie’@’%’;flush privileges;create database hue default character set utf8;
create user ‘hue’@’%’ identified by ‘123456’;
grant all privileges on hue.* to ‘hue’@’%’;flush privileges;create database nms default character set utf8;
create user ‘nms’@’%’ identified by ‘123456’;
grant all privileges on nms.* to ‘nms’@’%’;flush privileges; -
安裝cm例項和cm-server(master)
yum install -y cloudera-manager-daemons cloudera-manager-server
指定cm的資料庫
/usr/share/cmf/schema/scm_prepare_database.sh -h 192.168.1.67 mysql cm cm 123456
-
啟動server服務 訪問master主機的7180埠地址
service cloudera-scm-server start
service cloudera-scm-server status 檢視程序啟動的狀態
異常則去日誌目錄下檢視
tail -30f /var/log/cloudera-scm-server/cloudera-scm-server.log
成功則訪問 10.16.8.67:7180
四、CM安裝CDH
-
訪問10.16.8.67:7180
此時需要資料使用者名稱密碼,使用者名稱是admin,密碼輸入即會為初始密碼。 -
頁面1勾選方框同意使用者協議
-
頁面2選擇free 點選繼續

-
配置主機地址 輸入主機名稱

-
全部勾選,繼續
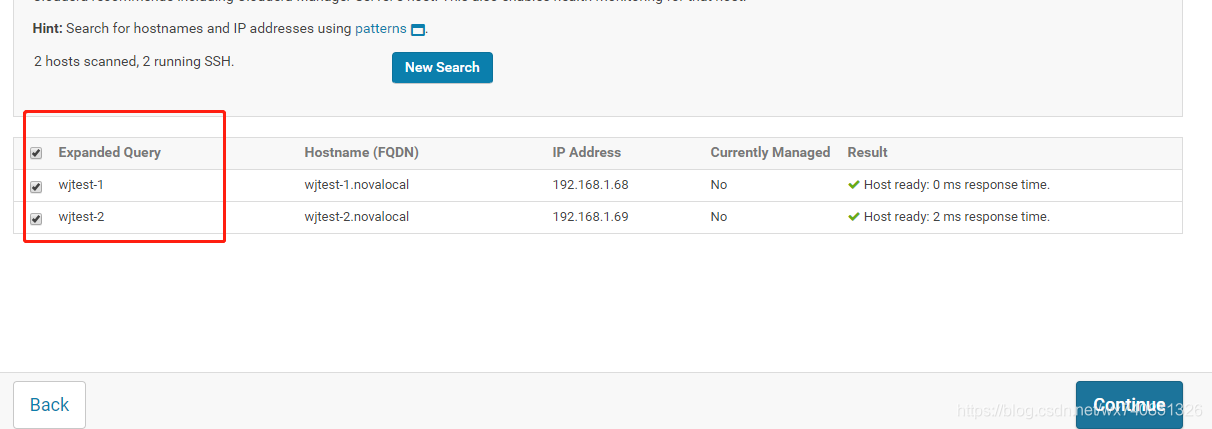
-
choose method 選擇 use packages
version of cdh選擇 cdh5
select 都選擇 custom repository
url輸入的是yum配置的地址 -
不勾選 install oracle java se… 繼續
此處為kerber安裝所必須的java安全包,沒有kerberos不需要安裝,有kerberos初次安裝也不要安裝,等環節裝好再啟用kerberos
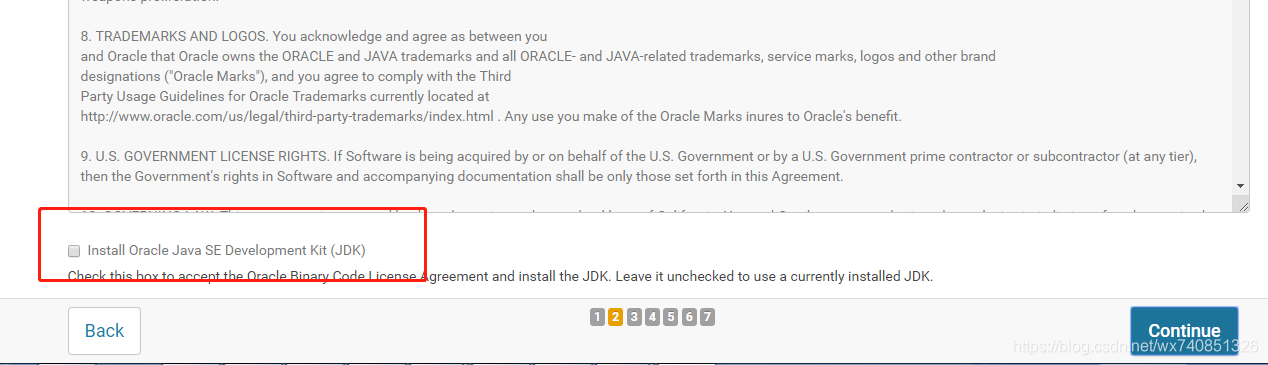
-
不勾選single… 直接繼續
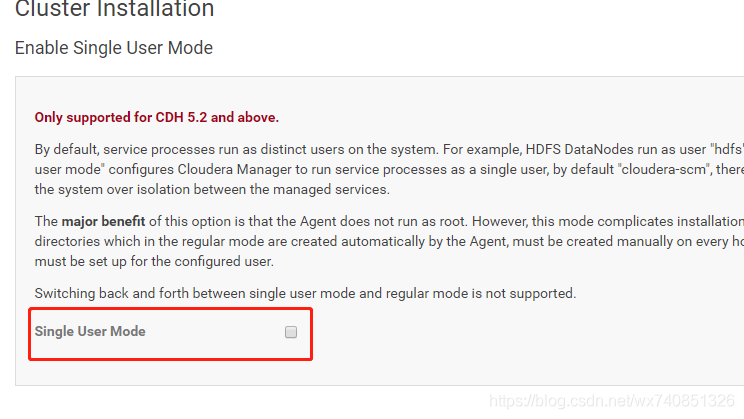
-
root安裝 所有主機接受相同的root密碼 輸入root的密碼 繼續
-
等待安裝完成,選擇core with spark
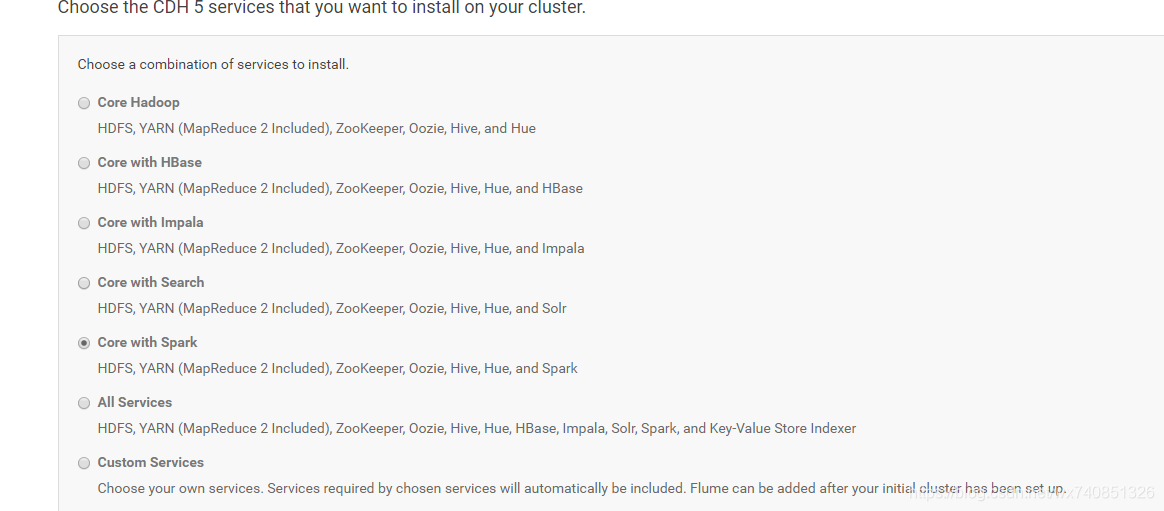
-
角色分配
分配角色 Hdfs角色分配如下:
Hive角色分配如下:
Hue角色分配入下:
Cloudera Managerment service角色分配如下:
Oozie spark yarn角色分配如下:
Zookeeper角色分配如下:




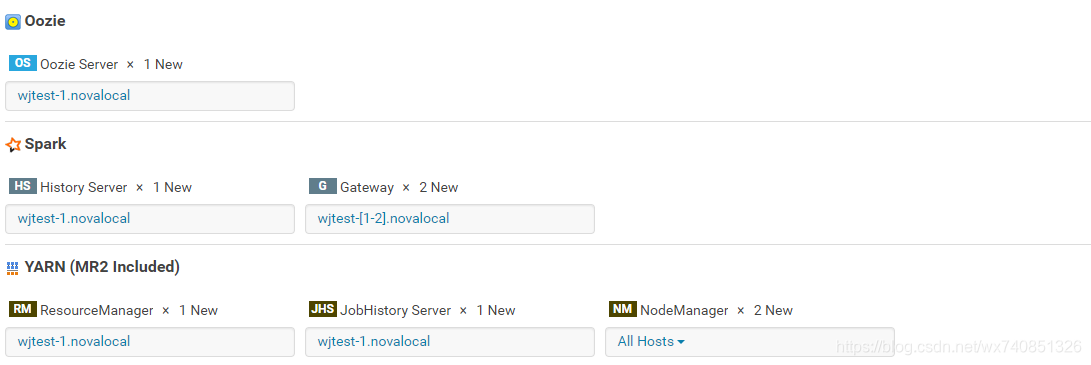
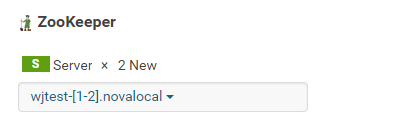
說明:
主角色由master承擔
所有機器都是datanode
Namenode首次分配在master上,ha之後分配到slave1上
所有機器都安裝zkserver
Gateway的角色在所有主機上都要有
Cdh的監控服務安裝到master
- 繼續
指定元資料管理庫

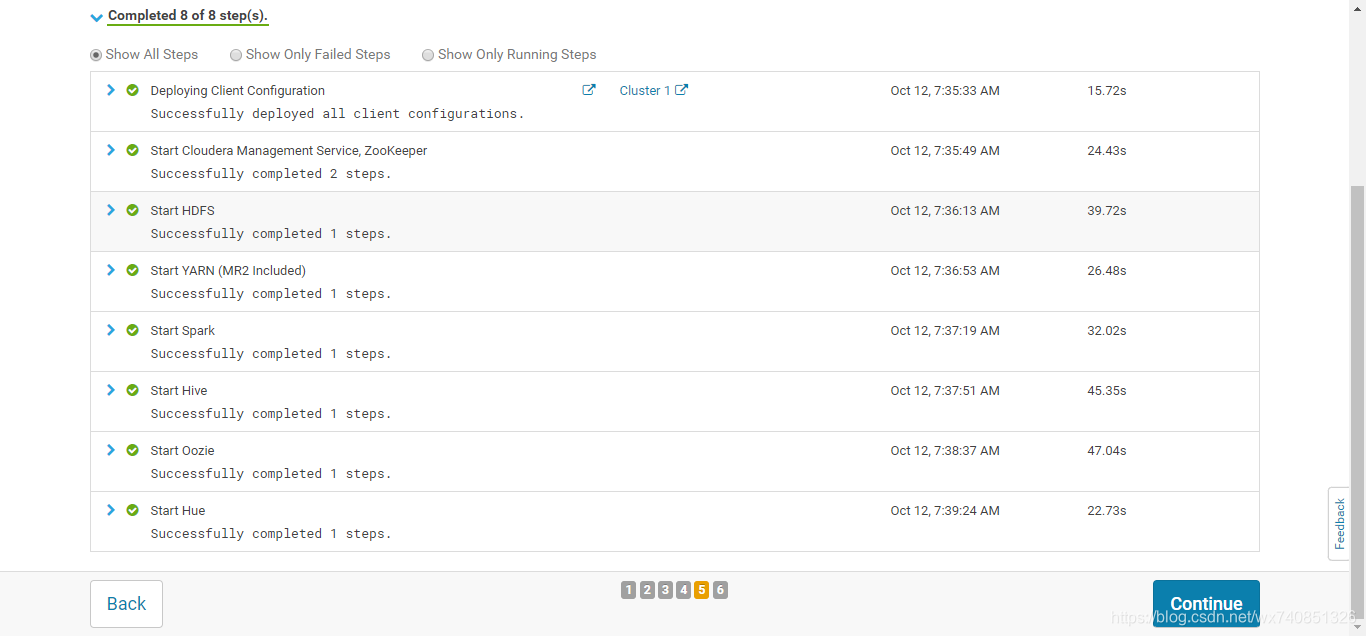
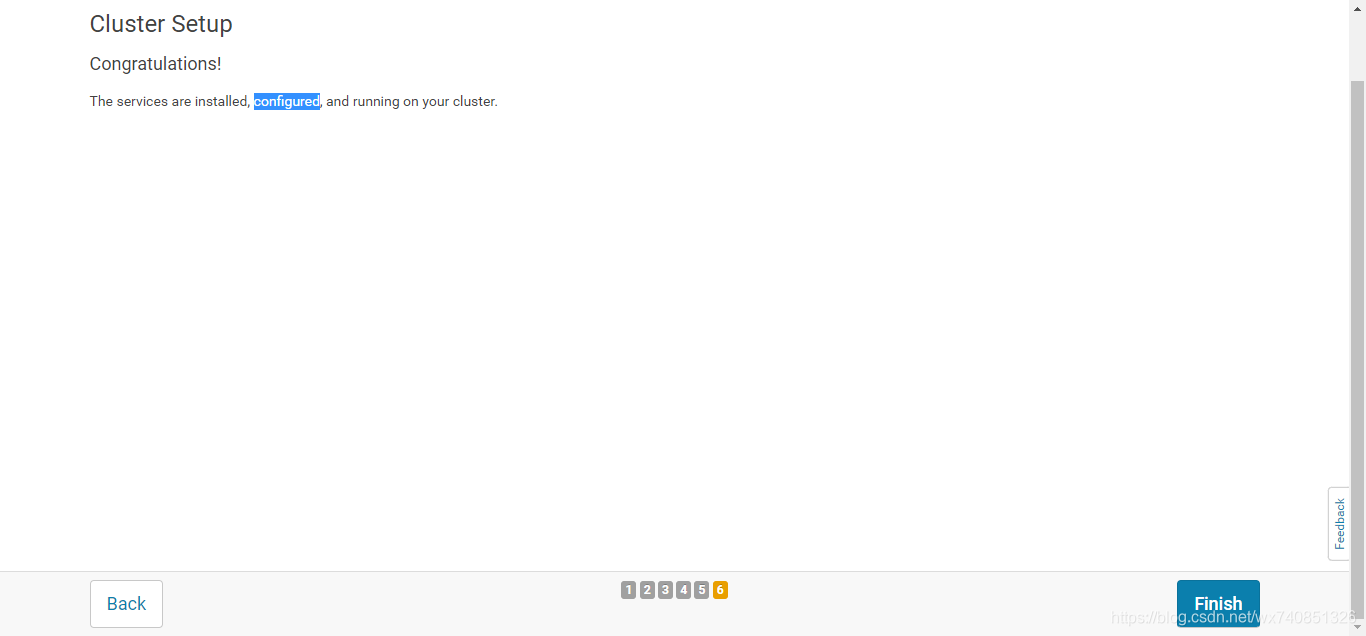
五、安裝spark,kafka
- 將parcel檔案都放在master主機的/opt/cloudera/parcel-repo下(.torrent檔案會自動生成,不用管)

- 將SPARK2_ON_YARN-2.3.0.cloudera3.jar檔案放在master主機的/opt/cloudera/csd下
- 在cdh的parcel包管理介面重新整理,依次分配和啟用CDH5,kafka,Spark2(必須先啟用CDH5)
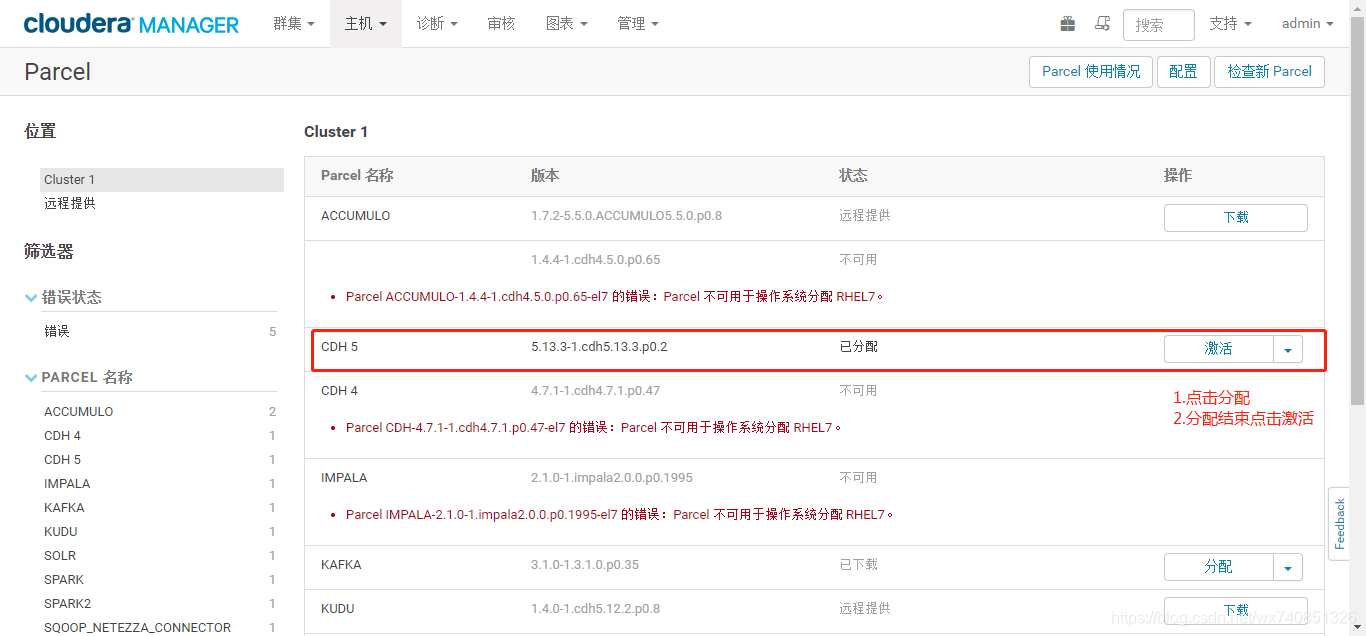
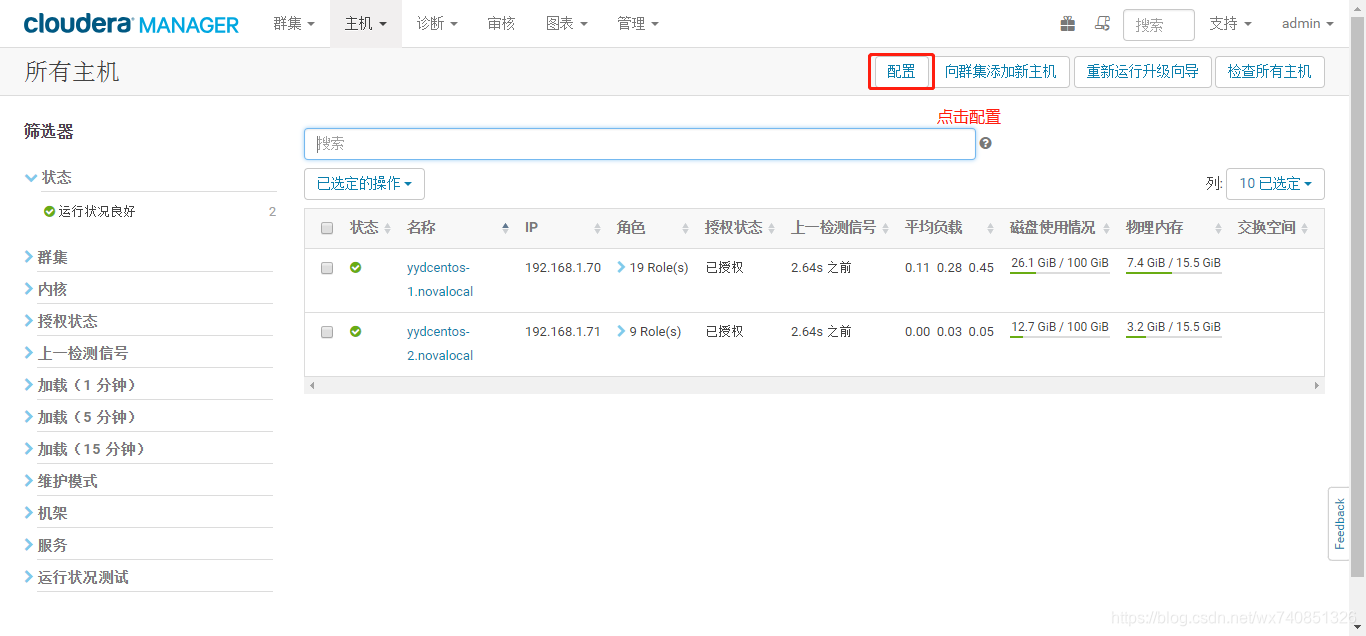
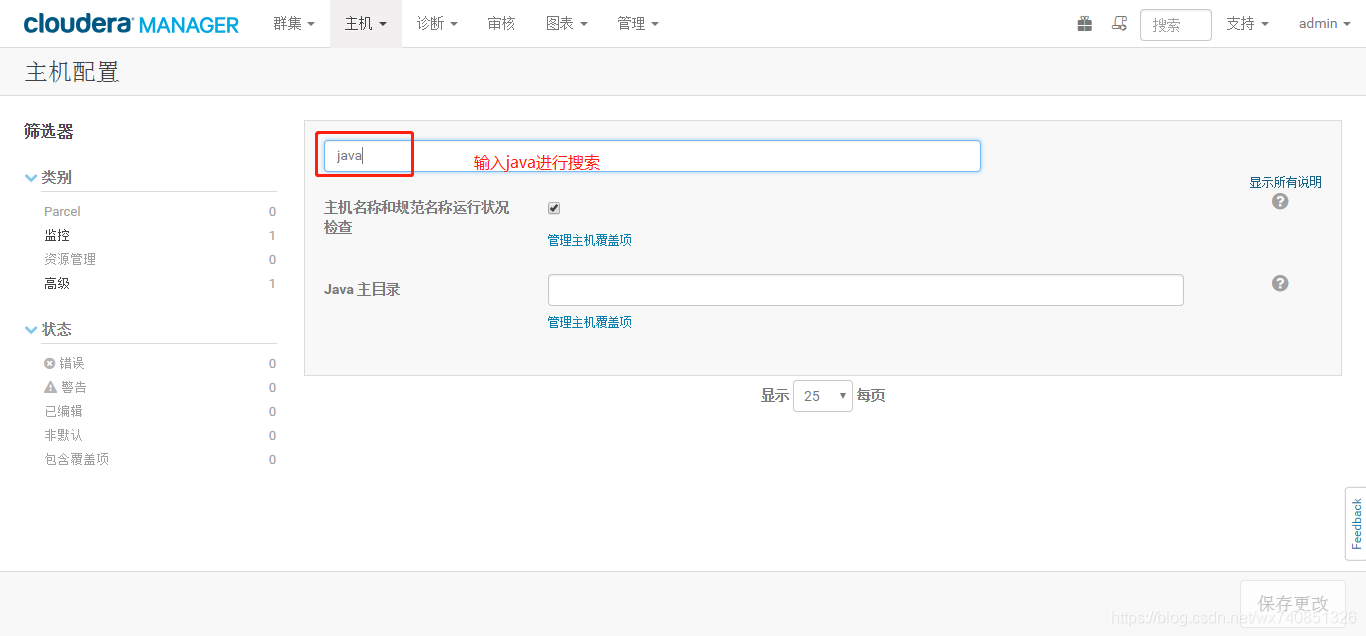
- 在各主機配置內修改java_home為/usr/java/jdk1.8(因為spark2需要jdk1.8支援,cdh自帶的為1.7)
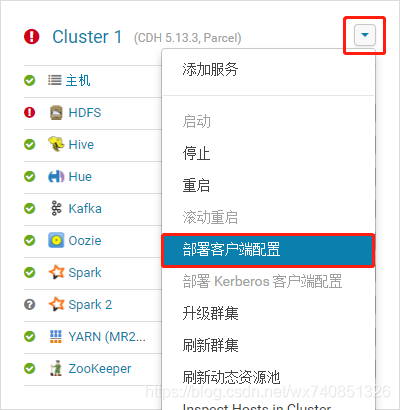
- 重新部署配置,然後重啟(啟用或者配置修改後都需如此操作)
- 重啟服務
重啟服務才能看到Spark2服務
service cloudera-scm-server restart
service cloudera-scm-agent restart
- 重啟完成後重新登入http://master:7180
- 新增kafka服務
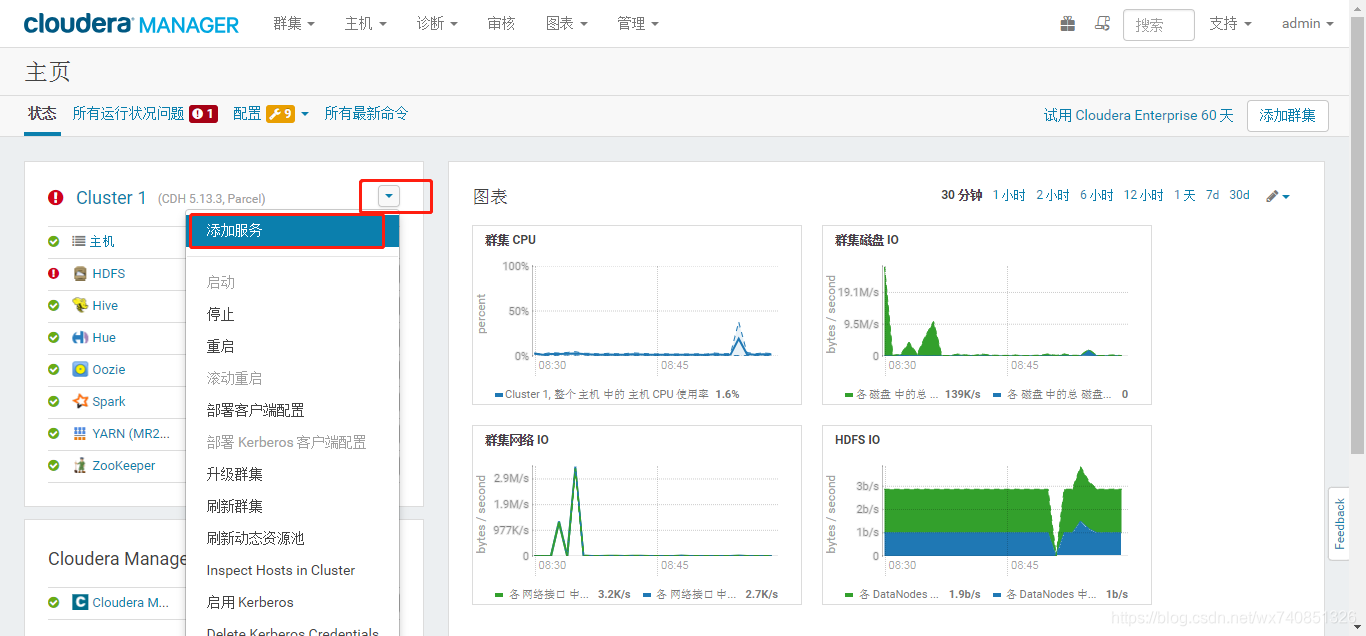

第一次可能會啟動失敗,失敗後直接在首頁點選kafka的小扳手檢視原因,點選配置修改配置,再次啟動kafka
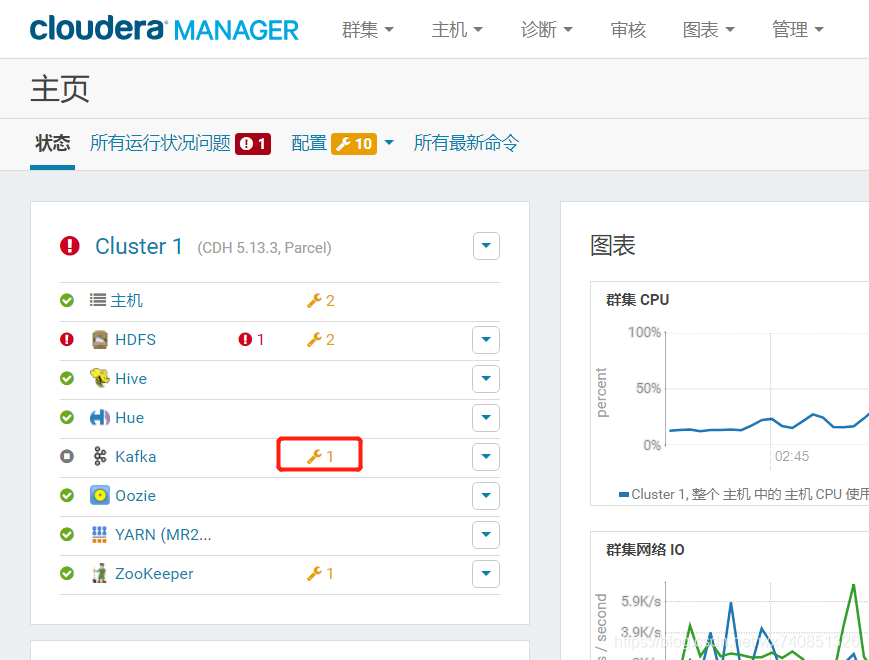

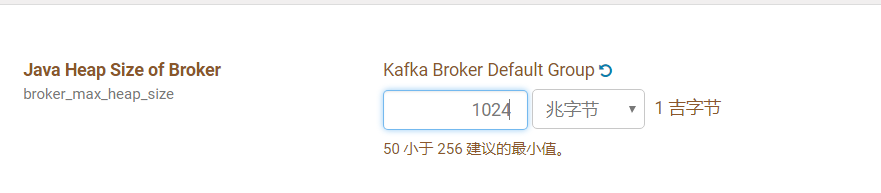
修改完成後,若啟動失敗,則去檢視日誌,很有可能是id問題:

檢視角色日誌報錯:kafka.common.InconsistentBrokerIdException: Configured broker.id 33 doesn’t match stored broker.id 59 in meta.properties
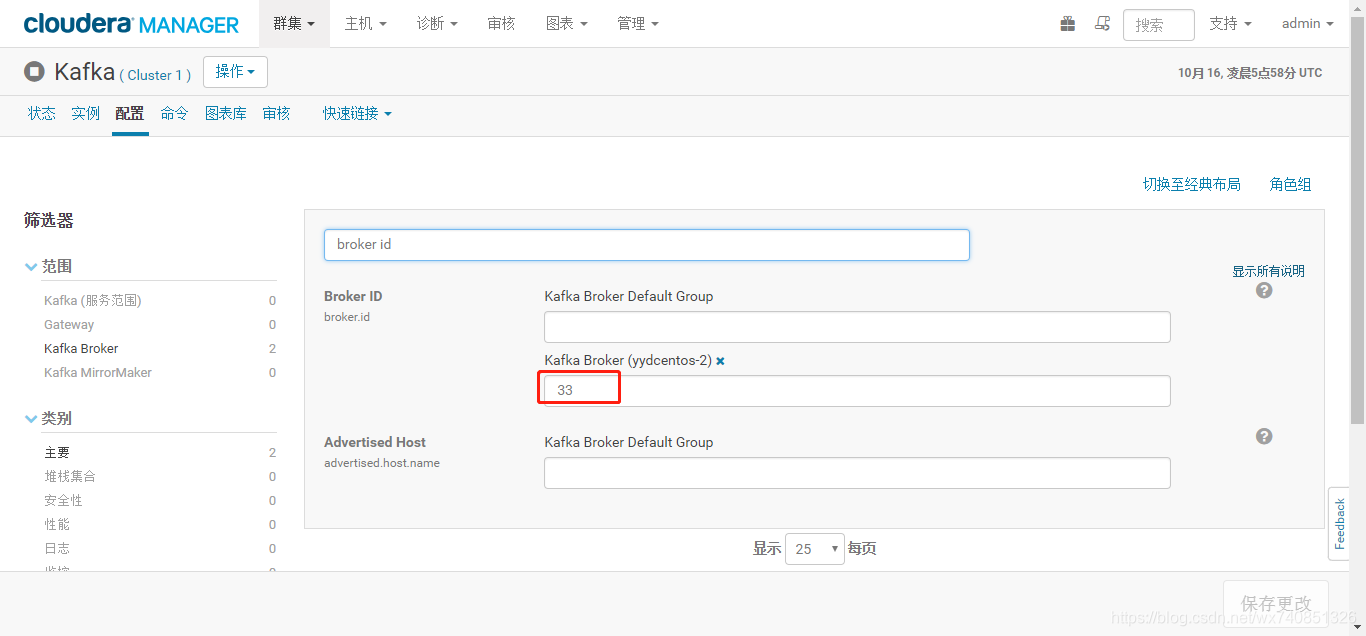
解決辦法:需把配置裡的引數改為59,再啟動
9.新增spark2服務
分配角色
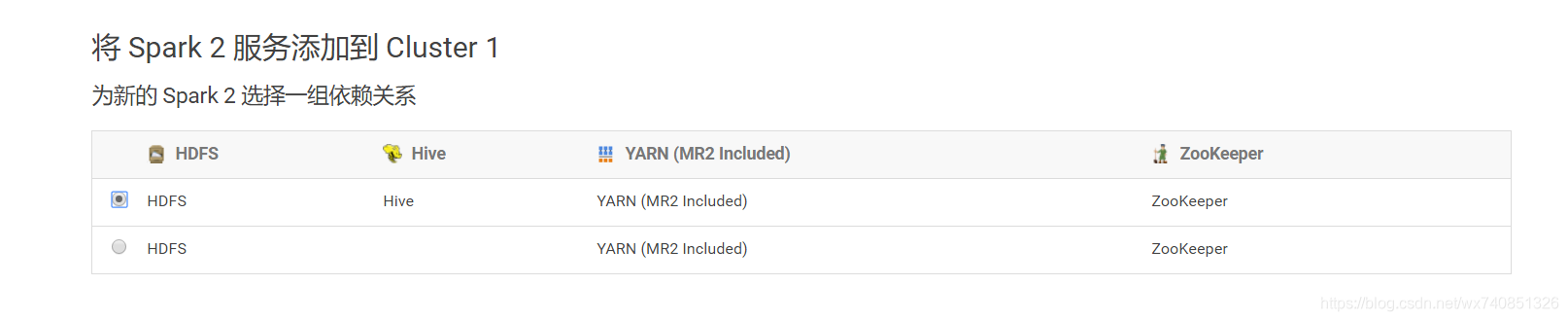

至此,我們的安裝就都已經完成啦。
六、安裝測試
-
測試spark服務
/var/lib/hadoop-hdfs下建立data檔案,內寫入’1\n2\n3’
檔案上傳至hdfs
cd /var/lib/hadoop-hdfs
hadoop fs -put data /user/spark/
啟動spark2-shell進入命令列
su hdfs
spark2-shell
val lines = sc.textFile("/user/spark/data")
lines.count
lines.first
能夠執行即可,若獲取不到資源,可修改下配置:修改yarn的配置
scheduler.maximum-allocation-mb、
nodemanager.resource.memory-mb
改為8GB -
測試kafka服務
使用命令建立topic
kafka-topics --create --zookeeper hadoop01,hadoop02 --replication-factor 1 --partitions 1 --topic test
檢視top是否建立成功
kafka-topics --list --zookeeper hadoop01,hadoop02 -
最後檢驗機器服務
執行jps,看是否和如下圖所示一致
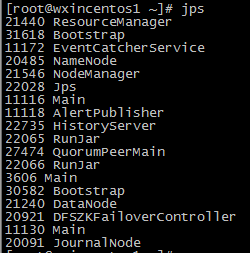
其中DFSZFailoverController是我在做了ha之後才有的服務,無需關注,至於如何配置HA,請參考我的其他文章,謝謝。