計算機視覺(六)
影象檢索與相關應用
一。基於內容的影象檢索

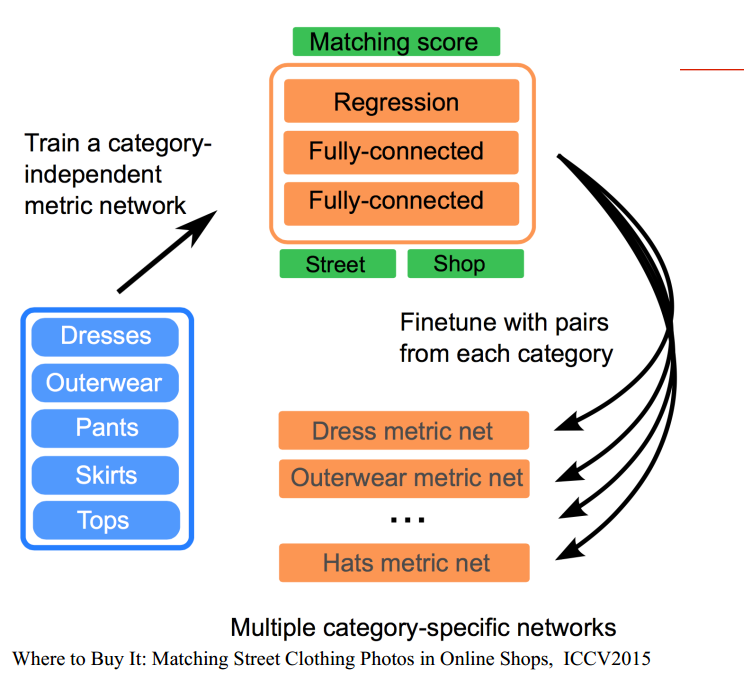
分開展開:
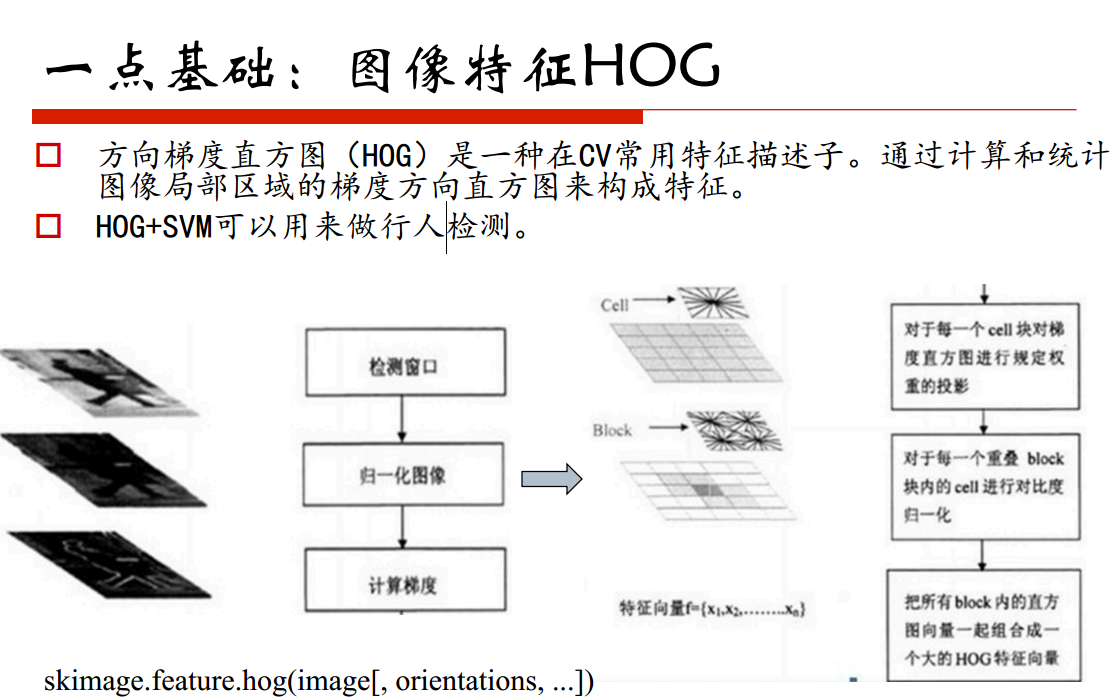
HOG
SIFT:

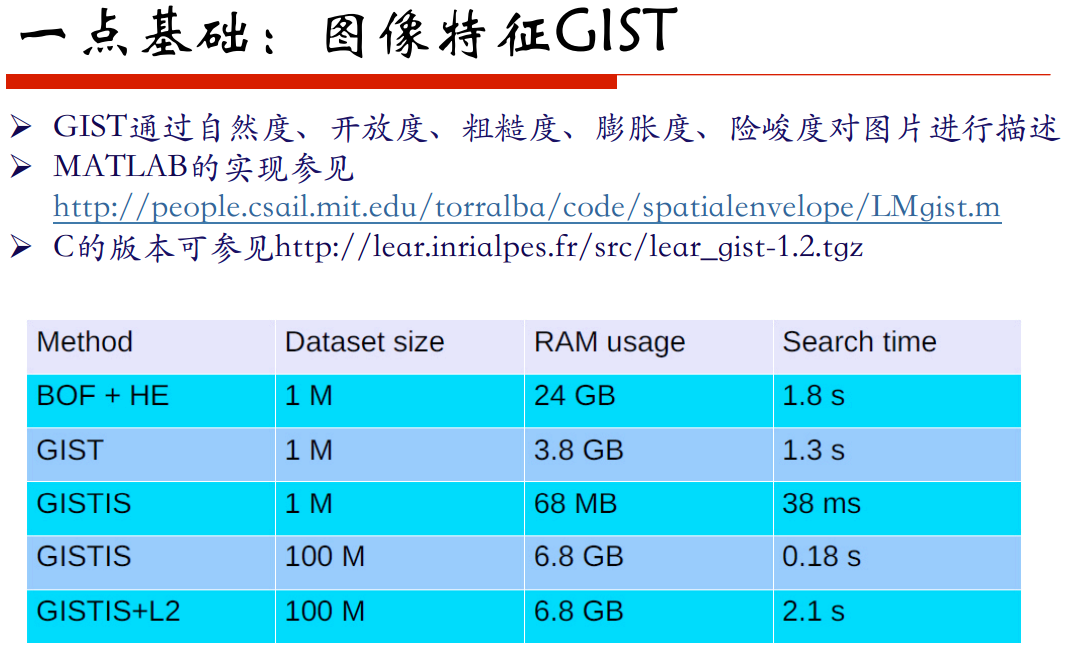
GIST:
CNN:

最近鄰問題:
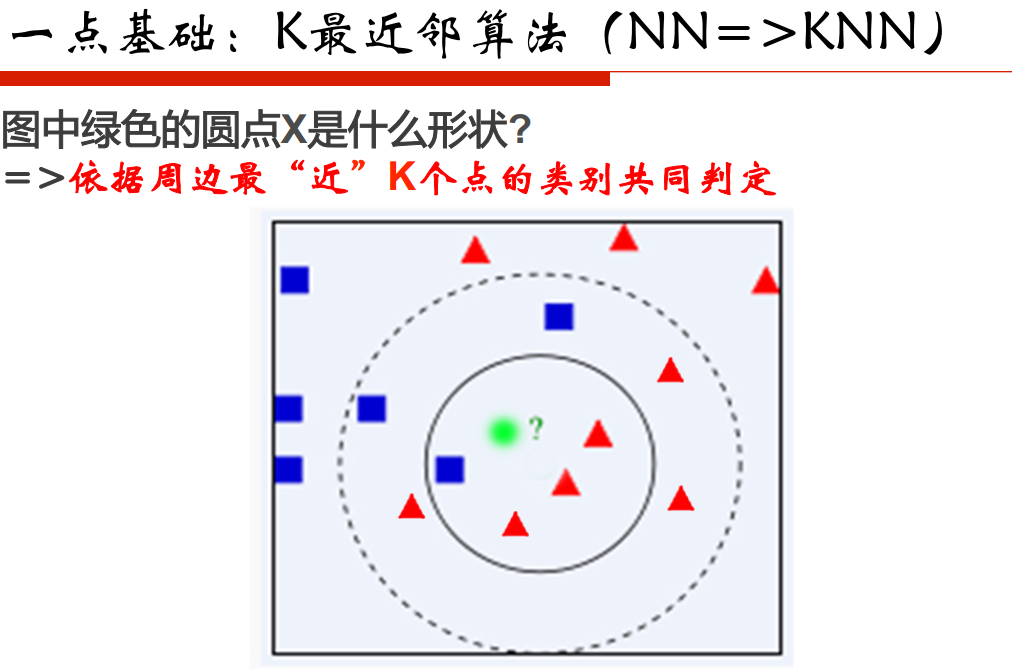


區域性敏感的雜湊:在高維空間和低維空間去保持距離

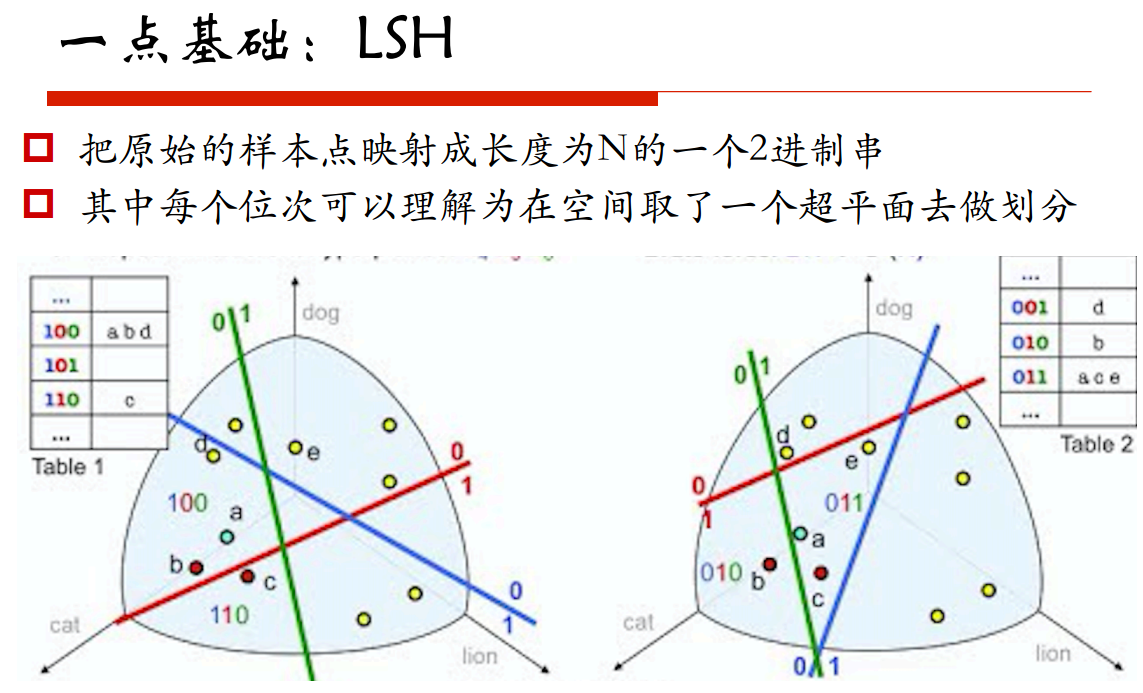

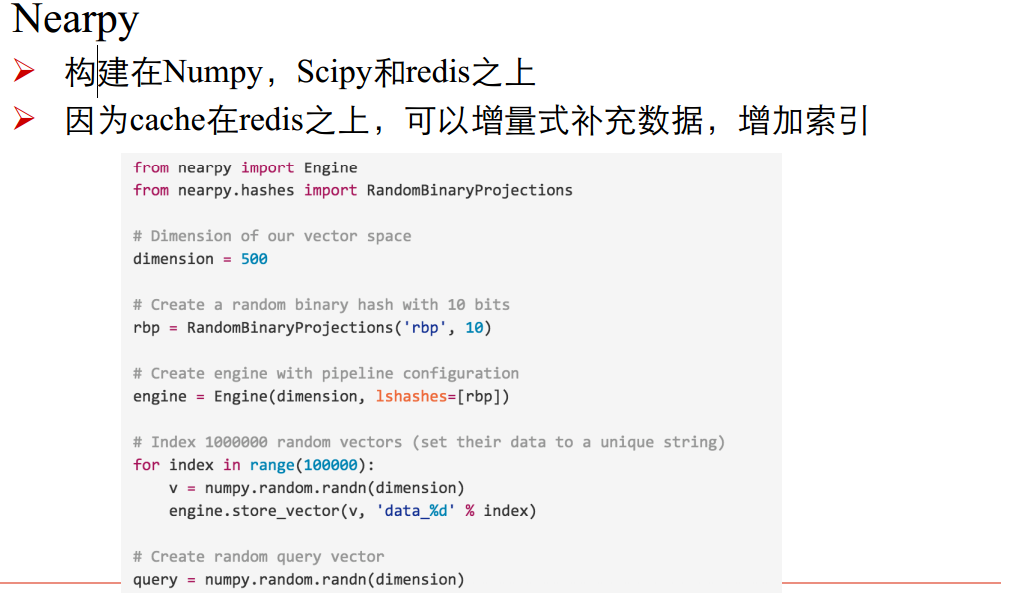
ANN庫:



串起來完成一個CBIR系統,進行分類。
二。 如何去讓我們的CBIR系統更快?
卷積神經網路進行找到影象的去處?
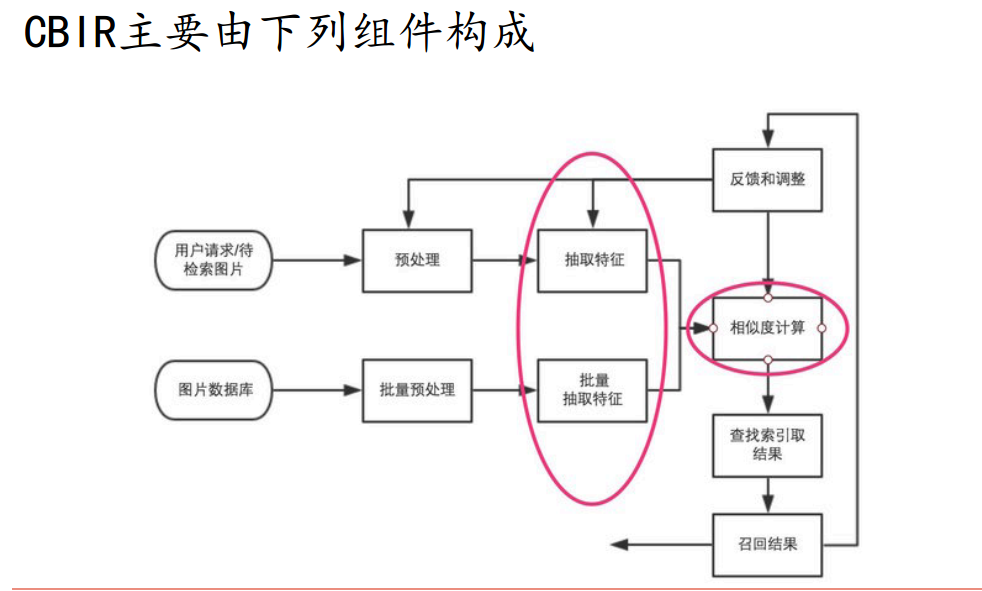
影象檢索過程簡單說來就是對圖片資料庫的每張圖片抽取特徵(一般形式為特徵向量),儲存於資料庫中,對於待檢索圖片,抽取同樣的特徵向量,然後並對該向量和資料庫中向量的距離,找出最接近的一些特徵向量,其對應的圖片即為檢索結果。
基於內容的影象檢索系統最大的難點在上節已經說過了,其一為大部分神經網路產出的中間層特徵維度非常高,比如Krizhevsky等的在2012的ImageNet比賽中用到的AlexNet神經網,第7層的輸出包含豐富的影象資訊,但是維度高達4096維。4096維的浮點數向量與4096維的浮點數向量之間求相似度,運算量較大,因此Babenko等人在論文Neural codes for image retrieval中提出用PCA對4096維的特徵進行PCA降維壓縮,然後用於基於內容的影象檢索,此場景中效果優於大部分傳統影象特徵。同時因為高維度的特徵之間相似度運算會消耗一定的時間,因此線性地逐個比對資料庫中特徵向量是顯然不可取的。大部分的ANN技術都是將高維特徵向量壓縮到低維度空間,並且以01二值的方式表達,因為在低維空間中計算兩個二值向量的漢明距離速度非常快,因此可以在一定程度上緩解時效問題。ANN的這部分hash對映是在拿到特徵之外做的,本系統框架試圖讓卷積神經網在訓練過程中學習出對應的『二值檢索向量』,或者我們可以理解成對全部圖先做了一個分桶操作,每次檢索的時候只取本桶和臨近桶的圖片作比對,而不是在全域做比對,以提高檢索速度。
論文是這樣實現『二值檢索向量』的:在Krizhevsky等2012年用於ImageNet中的卷積神經網路結構基礎上,在第7層(4096個神經元)和output層之間多加了一個隱層(全連線層)。隱層的神經元激勵函式,可以選用sigmoid,這樣輸出值在0-1之間值,可以設定閾值(比如說0.5)之後,將這一層輸出變換為01二值向量作為『二值檢索向量』,這樣在使用卷積神經網做影象分類訓練的過程中,會『學到』和結果類別最接近的01二值串,也可以理解成,我們把第7層4096維的輸出特徵向量,通過神經元關聯壓縮成一個低維度的01向量,但不同於其他的降維和二值操作,這是在一個神經網路裡完成的,每對圖片做一次完整的前向運算拿到類別,就產出了表徵影象豐富資訊的第7層output(4096維)和代表圖片分桶的第8層output(神經元個數自己指定,一般都不會很多,因此維度不會很高)。
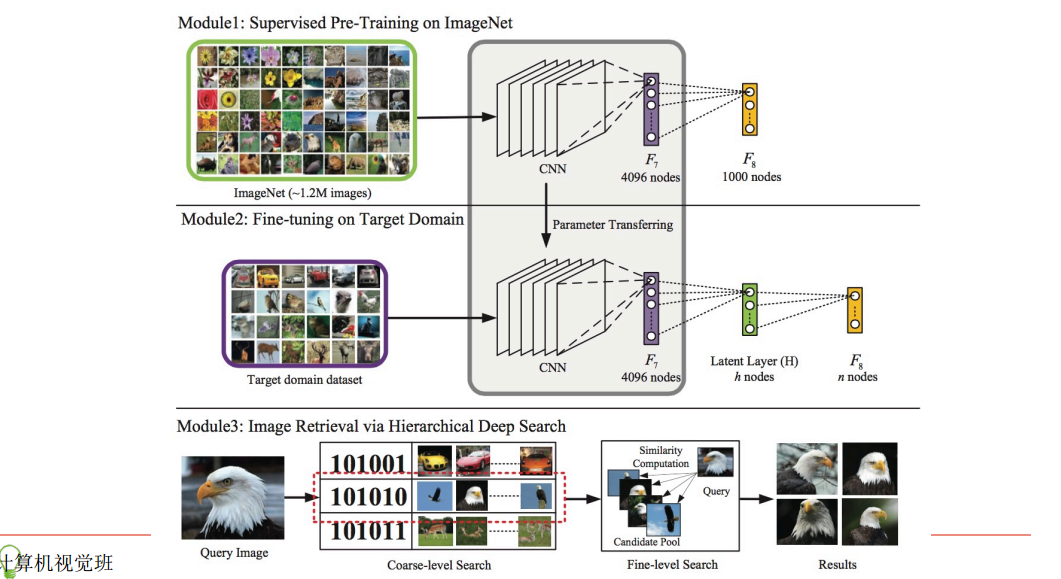
上方圖為ImageNet比賽中使用的卷積神經網路;中間圖為調整後,在第7層和output層之間新增隱層(假設為128個神經元)後的卷積神經網路,我們將複用ImageNet中得到最終模型的前7層權重做fine-tuning,得到第7層、8層和output層之間的權重。下方圖為實際檢索過程,對於所有的圖片做卷積神經網路前向運算得到第7層4096維特徵向量和第8層128維輸出(設定閾值0.5之後可以轉成01二值檢索向量),對於待檢索的圖片,同樣得到4096維特徵向量和128維01二值檢索向量,在資料庫中查詢二值檢索向量對應『桶』內圖片,比對4096維特徵向量之間距離,做重拍即得到最終結果。圖上的檢索例子比較直觀,對於待檢索的"鷹"影象,算得二值檢索向量為101010,取出桶內圖片(可以看到基本也都為鷹),比對4096維特徵向量之間距離,重新排序拿得到最後的檢索結果。
可參考去一下:
Ø 可參考《基於deep learning的快速影象檢索系統》
http://blog.csdn.net/han_xiaoyang/article/details/50856583
Ø https://github.com/HanXiaoyang/image_retrieval
三。專案:
怎樣針對電商做影象檢測?