
Spark Streaming知識總結
Spark Streaming原理
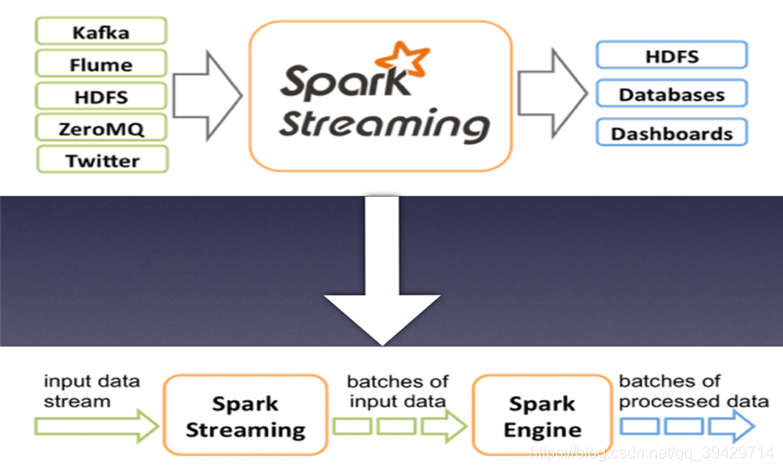
Spark Streaming 是基於spark的流式批處理引擎。其基本原理是:將實時輸入資料流以時間片為單位進行拆分,然後經Spark引擎以類似批處理的方式處理每個時間片資料。
Spark Streaming作業流程
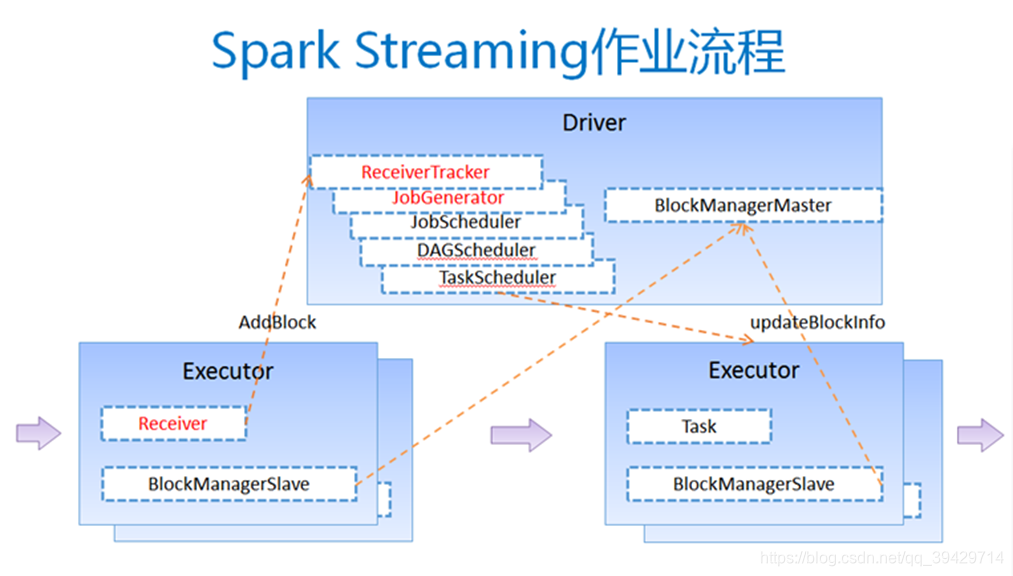
- 客戶端提交作業後啟動Driver(Driver是spark作業的Master);
- 每個作業包含多個Executor,每個Executor以執行緒的方式執行task,Spark Streaming至少包含一個receiver task(可選的);
- Receiver接收資料後生成Block,並把BlockId彙報給Driver,然後備份到另外一個Executor上;
- ReceiverTracker維護Reciver彙報的BlockId;
- Driver定時啟動JobGenerator,根據Dstream的關係生成邏輯RDD,然後建立Jobset,交給JobScheduler;
- JobScheduler負責排程Jobset,交給DAGScheduler,DAGScheduler根據邏輯RDD,生成相應的Stages,每個stage包含一到多個task;
- TaskScheduler負責把task排程到Executor上,並維護task的執行狀態;
- 當tasks、stages、jobset完成後,單個batch才算完成。
聯絡:
流式系統的特點:
低延遲。秒級或更短時間的響應
高效能
分散式
可擴充套件。伴隨著業務的發展,資料量、計算量可能會越來越大,所以要求系統是可擴充套件的
容錯。分散式系統中的通用問題,一個節點掛了不能影響應用
區別:
1、同一套系統,安裝spark之後就一切都有了
2、spark較強的容錯能力;strom使用較廣、更穩定
3、storm是用Clojure語言去寫的,它的很多擴充套件都是使用java完成的
4、任務執行方面和strom的區別是:
spark steaming資料進來是一小段時間的RDD,資料進來之後切成一小塊一小塊進行批處理
storm是基於record形式來的,進來的是一個tuple,一條進來就處理一下
5、中間過程實質上就是spark引擎,只不過sparkstreaming在spark之後引擎之上動了一點手腳:對進入spark引擎之前的資料進行了一個封裝,方便進行基於時間片的小批量作業,交給spark進行計算
離散資料流
Spark Streaming最主要的抽象是DStream(Discretized Stream,離散化資料流),表示連續不斷的資料流。
在內部實現上,Spark Streaming的輸入資料按照時間片(如1秒)分成一段一段,每一段資料轉換為Spark中的RDD,這些分段就是DStream,並且對DStream的操作都最終轉變為對相應的RDD的操作。
Spark Streaming提供了被稱為離散化流或者DStream的高層抽象,這個高層抽象用於表示資料的連續流;
建立DStream的方式:由檔案、Socket、Kafka、Flume等取得的資料作為輸入資料流;或其他DStream進行的高層操作;
在內部,DStream被表達為RDDs的一個序列。
1、Dstream叫做離散資料流,是一個數據抽象,代表一個數據流。這個資料流可以從對輸入流的轉換獲得
2、Dstream是RDD在時間序列上的一個封裝
3、DStream的內部是通過一組時間序列上連續的RDD表示,每個都包含了特定時間間隔的資料流,RDD代表按照規定時間收集到的資料集
4、DStream這種資料流抽象也可以整體轉換,一個操作結束後轉換另外一種DStream
5、DStream的預設儲存級別為<記憶體+磁碟>
6、sparkstreaming有一種特別的操作:windows操作,稱為視窗操作,實質是對固定的以時間片積累起來的幾個RDD作為一整體操作
7、可以使用persist()函式進行序列化(KryoSerializer)
輸入輸出資料來源
Spark Streaming可整合多種輸入資料來源,如:
檔案系統(本地檔案、HDFS檔案)
TCP套接字
Flume
Kafka
處理後的資料可儲存至檔案系統、資料庫等系統中
Spark Streaming 讀取外部資料
在Spark Streaming中,有一個元件Receiver,作為一個長期執行的task跑在一個Executor上;
每個Receiver都會負責一個input DStream(比如從檔案中讀取資料的檔案流,比如套接字流,或者從Kafka中讀取的一個輸入流等等);
Spark Streaming通過input DStream與外部資料來源進行連線,讀取相關資料。這項工作由Receiver完成。
Streaming 程式基本步驟
1、建立輸入DStream來定義輸入源
2、通過對DStream應用轉換操作和輸出操作來定義流計算
3、用streamingContext.start()來開始接收資料和處理流程;start之後不能再新增業務邏輯。
4、通過streamingContext.awaitTermination()方法來等待處理結束(手動結束或因為錯誤而結束)
5、可以通過streamingContext.stop()來手動結束流計算程序
StreamingContext 物件
StreamingContext 物件可以通過 SparkConf 物件建立;
不要硬編碼 master 引數在叢集中, 而是通過 spark-submit 接收引數;
對於本地測試和單元測試, 可以傳遞“local[*]” 來執行 Spark Streaming 在程序內執行(自動檢測本地系統的CPU核心數量);
分批間隔時間基於應用延遲需求和可用的叢集資源進行設定(設定間隔要大於應用資料的最小延遲需求,同時不能設定太小以至於系統無法在給定的週期內處理完畢)
其他問題
StreamingContext 物件也可以通過SparkContext物件建立。在context建立之後,可以接著開始如下的工作:
定義 input sources,通過建立 input Dstreams 完成
定義 streaming 計算,通過DStreams的 transformation 和 output 操作實現
啟動接收資料和處理,通過 streamingContext.start()
等待處理停止 (通常因為錯誤),通過streamingContext.awaitTermination()
處理過程可以手動停止,通過 streamingContext.stop()
備註:
一旦context啟動, 沒有新的 streaming 計算可以被設定和新增進來
一旦context被停止, 它不能被再次啟動
只有一個StreamingContext在JVM中在同一時間可以被啟用
StreamingContext.stop()執行時,同時停止了SparkContext
基本輸入源
檔案流
1、檔案必須是cp到指定的路徑中,不能是mv。新建檔案也可以。
hdfs、本地檔案系統都可以
2、檔案流不需要執行接收器,可以不分配核數,即可以使用local[1],這是特例
Socket(套接字)流
Spark Streaming可以通過Socket埠監聽並接收資料,然後進行相應處理
編寫基於套接字的WordCount程式
新開一個命令視窗,啟動nc程式:
nc -lk 9999
(nc 需要安裝 yum install nc)
隨後可以在nc視窗中隨意輸入一些單詞,監聽視窗會自動獲得單詞資料流資訊,在監聽視窗每隔x秒就會打印出詞頻統計資訊,可以在螢幕上出現結果。
備註:使用local[],可能存在問題。
如果給虛擬機器配置的cpu數為1,使用local[]也只會啟動一個執行緒,該執行緒用於receiver task,此時沒有資源處理接收達到的資料。
【現象:程式正常執行,不會列印時間戳,螢幕上也不會有其他有效資訊】
有幾個問題:
日誌資訊太多,不爽,能改善嗎?
加入 setLogLevel
可以從別的機器傳送字串嗎,可以監聽別的機器的埠嗎?
nc –lk 9999
ssc.socketTextStream(“node1”, 9999)
nc命令只能將字串傳送到本地的埠;
streaming程式可以監聽其他機器的埠
每次都需要手動輸入字串,實在不爽!能寫一個模仿nc的程式,向固定埠傳送資料嗎?
RDD佇列流
除錯Spark Streaming應用程式的時候,可使用streamingContext.
queueStream(queueOfRDD)建立基於RDD佇列的Dstream;
新建一個RDDQueueStream.scala程式碼檔案,功能是:每秒建立一個RDD,Streaming每隔5秒就對資料進行處理;
這種方式多用來測試streaming程式。
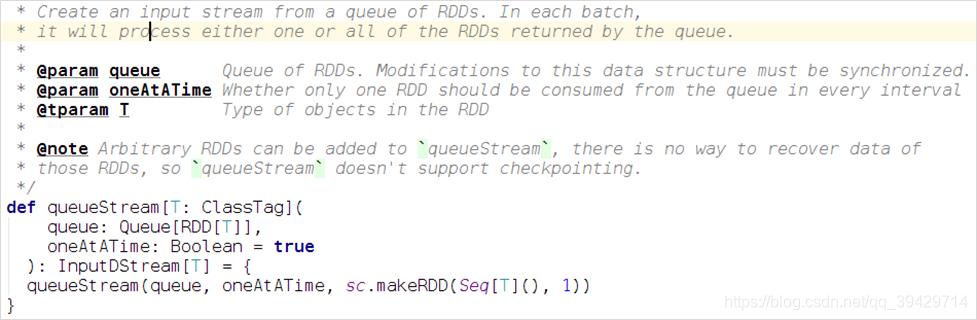
備註:
oneAtATime:預設為true,一次處理一個RDD,
設為false,一次處理全部RDD;
RDD佇列流可以使用local[1];
涉及到同時出隊和入隊操作,所以要做同步;