
HBase深度簡介
轉載自:https://blog.csdn.net/jiangtao_st/article/details/19499923
高江濤個人部落格
一、簡介
Hbase:全名Hadoop DataBase,是一種開源的,可伸縮的,嚴格一致性(並非最終一致性)的分散式儲存系統。具有最理想化的寫和極好的讀效能。它支援可插拔的壓縮演算法(使用者可以根據其列族中的資料特性合理選擇其壓縮演算法),充分利用了磁碟空間。
類似於Google的BigTable,其分散式計算採用MapReduce,通過MapReduce完成大塊的資料載入和全表掃描操作等。檔案儲存系統採用HDFS,通過Zookeeper來完成狀態管理協同服務。不過BigTable只支援一級索引,Hbase不僅支援一級索引,還支援二級索引。
需要指出的是:很多人都認為Hbase是面向列的資料庫,其實不是。從典型的關係型資料庫概念上來說Hbase並不是面向列的資料庫。但是充分利用了磁碟上列式儲存格式的特性。Hbase跟傳統的Columnar databases還是有區別的。Columnar databases擅長的是實時資料的分析訪問,而Hbase在基於key的單值訪問和範圍掃描上比較突出。不過我們經常談及到的Hbase是面向列的儲存系統,其實是因為Hbase是以列族的模式進行儲存的。
二、Hbase基本結構
1)架構圖
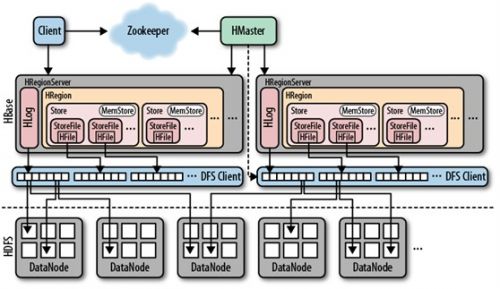
從上圖中可以看出,Hbase內部的核心結構由以下幾大塊組成:HMaster,HRegionServer,HLog,HRegion等。而Hbase依賴的外部系統有Zookeeper,HDFS等。
1)HMaster(類似於HDFS中NameNode,MapReduce中的JobTrackers)是用來管理HRegionServer的。它負責監控叢集中HRegionServer的狀態資訊變化。主要功能點如下:
1、管理HRegionServer的負載均衡,調整Region分佈。這個通過HMaster的後臺執行緒LoadBalancer來完成。LoadBalancer會定期將Region進行移動,以使各個HRegionServer達到Load均衡。
2、在Region Split後,負載新Region的分配。
3、HRegionServer的FailOver處理,當某一個HRegionServer出問題後,HMaster負責將其Region進行轉移。
4、CatalogJanitor。 CatalogJanitor會定期檢查和清理.Meta.表。
在一個HBase叢集中會存在多個HMaster,不過zookeeper的Master Election機制會保證只有一個HMaster在執行。當執行的HMaster出問題後,其他的HMaster就會立刻補上。
2)從圖中可以看出,Hbase客戶端是隻與zookeeper和HRegion Server打交道。並不會跟HMaster互動。所以如果HMaster出問題了,Hbase叢集在短時間內還是可以對外提供可靠服務的。但是,因為HMaster掌控了HRegionServer的一些功能,如:HRegion Server的FailOver操作,Region切分等,HMaster長時間不可用還是會出問題的。
3)上面所提及的Catelog表有兩個:-Root-和.Meta.表。-Root-表中儲存了.Meta.表的位置。即.Meta.表的Region key。.Meta.表儲存了所有Region的位置及每個Region所包含的RowKey的範圍。-Root-表的儲存位置記錄在zookeeper中,.Meta.表的儲存位置記錄在-Root-表中。
4)當客戶端發起一個查詢資料的請求後,首先,客戶端會先連線上zookeeper叢集,獲取-Root-表的存放在哪一個HRegionServer上。接著找到對應的HRegionServer後,就能夠獲取到-Root-表中對應的.Meta.表的位置。最後客戶端根據.Meta.表儲存的HRegion的位置到相應的HRegionServer中取對應的Hregion中的資料資訊。經過一次查詢後,訪問Catalog表的過程就會被快取起來,下次客戶端就可以直接到相應的HRegion上獲取資料。
5)Hbase已經無縫集成了HDFS,其中所有的資料最終都會通過DFS客戶端API持久化到HDFS中。
6)一個Hbase叢集中有許多個HRegionServer(類似於HDFS中的DataNode,MapReduce中的TaskTrackers),由一個HMaster進行管理。每個HRegionServer擁有一個WAL(write Ahead Log,日誌檔案,用作資料恢復)和多個HRegion(可以簡單認為是用來儲存一個表中的某些行)。一個HRegion擁有多個Store(儲存一個ColumnFamily)。一個Store又由一個MemStore(持有對該Store的所有修改於記憶體中)和0至多個StoreFiles(HFile,資料儲存的地方)組成。詳細圖如下:
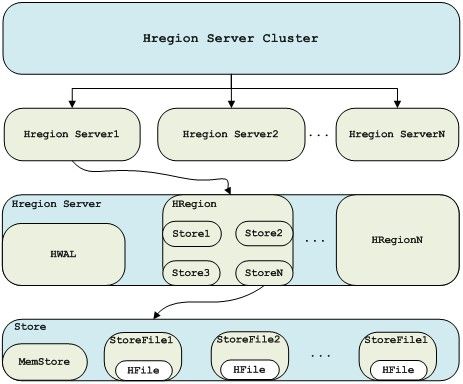
2)基本元素
1、Row Key
行標示,類似於傳統資料庫表中的行號。Rowkeys具有不變性。除非該行別刪除或者被重新插入了新的資料。Hbase中支援基於RowKey的單行查詢和範圍掃描。在Hbase的Auto-Sharding中,也是基於RowKey進行自動切分的。
2、Column Family
在Hbase中最基本的單元就是列。而列族是由一個或者列組成。一般在使用時,儘量將經常訪問的列作為一個列族。因為Hbase是面向列族的儲存,也就是說一個列族中的所有列是儲存在一起的。即上圖中的一個Store儲存一個列族。
不過有一點需要注意的是在一個表中列族被限定不能超過十個。
3、TimeStamp
Hbase中支援時間戳的概念。即允許Cell儲存多個版本值。版本之間通過時間戳來區分。也就是說可能存在某一列的某一行有多個值。一般預設是3,且最近版本在最上面。Hbase中有一個TTL(Time To Live)的配置,這個是基於列族維度的。一旦過期,列族就會自動刪除所有行。
4、HRegion Server
HRegionServer是負責服務和管理Region的。類似於我們所說的主從伺服器,HMaster就是主伺服器,HRegionServer就是從伺服器。當用戶執行CRUD等操作時,都需要通過HRegionServer定位到相應的Region上進行操作。
5、WAL
WAL全名是Write Ahead Log,類似於mysql中的Binary Log,WAL記錄了該HRegionServer上所有資料的變更。一旦這個HRegionServer死翹翹了,導致資料丟失後,WAL就是救命稻草。可以通過WAL進行資料恢復。所以在平時WAL是沒什麼用的,只是為了不可預知的災難做準備。當然,WAL起作用的前提是保證變更日誌已經記錄到了WAL中。
WAL的實現類是HLog。因為在一個HRegionServer中持有一個WAL,所以對於該HRegionServer上的所有Region來說,WAL是全域性,共享的。當HRegion例項建立的時候,在HRegionServer例項中的HLog就會被當做HRegion建構函式的引數傳遞到HRegion。當HRegion接收到一個變更操作時,HRegion就能直接通過HLog將變更日誌追加(append()方法)到共享WAL中。當然基於效能考慮,HBase還提供了一個setWriteToWAL(false)方法。一旦使用者呼叫了此方法。變更日誌就不會追加到WAL中。預設是需要寫入的,除非使用者自己保證資料不會丟失。
HLog還有一個重要的特性就是:跟蹤變更。在HLog類中有一個原子型別的變數,HLog會讀取StoreFiles中最大的sequence number(HLog中每一條變更日誌都有一個number號,因為對於一個HRegionServer中的所有HRegion是共享HLog的,所以會將變更日誌順序寫入WAL,StoreFiles中也持有該number),並存放到變數中。這樣HLog就知道已經已經儲存到哪一個位置了。
WAL還有兩個比較重要的類,一個是LogSyncer,另一個是LogRoller。
1、在建立表時,有一個引數設定:Deferred Log Flush,預設是false,表示log一旦更新就立即同步到filesystem。如果設定為true,則HRegionServer會快取那些變更,並由後臺任務LogSyncer定時將變更資訊同步到filesystem。
2、WAL是有容量限制的,LogRoller是一個後臺執行緒,會定時滾動logfile,使用者可以設定這個間隔時間(hbase.regionserver.logroll.period,預設是一小時)。當檢查到某個logfile檔案中的所有sequence number均小於那個最大的sequence number時,就會將此logfile移到.oldLog目錄。
如下是WAL的檔案結構,目前WAL採用的是Hadoop的SequenceFile,其儲存記錄格式是key/value鍵值對的形式。其中Key儲存了HLogkey的例項,HLogKey包含資料所屬的表名及RegionName,timeStamp,sequenceNumber等資訊。Value儲存了WALEdit例項,WALEdit包含客戶端每一次發來的變更資訊。
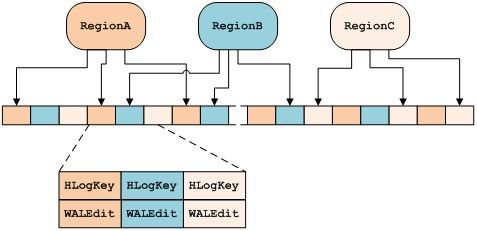
6、Region
在Hbase中實現可擴充套件性和負載均衡的基本單元是Region。Region儲存著連續的RowKey的資料。剛開始時,一個表就只有一個Region,當一個表隨著資料增多而不斷變大時,如果達到指定的大小後就會根據Rowkey自動一分為二成兩個Region。每個Region中儲存著一個【startkey,endkey】。隨著表的繼續增大,每個Region又會自動split成更多的Region。每個Region只會由一個HRegionServer服務。這就是所謂的Hbase的AutoSharding特性。當然,Region除了會spilt外,也可能進行合併以減少Region數目(這就是Hbase的compaction特性,後面會談到)。
既然Region是表的基本元素。那麼,使用者如何獲取到對應的Region呢??前面已經提及—通過Catalog表。
7、Store
Store是核心儲存單元。在一個HRegion中可能存在多個ColumnFamily,那麼Store中被指定只能儲存一個ColumnFamily。不同的ColumnFamily儲存在不同的Store中(所以在建立ColumnFamily時,儘量將經常需要一起訪問的列放到一個ColumnFamily中,這樣可以減少訪問Store的數目)。一個Store由一個MemStore和0至多個StoreFile組成。
8、MemStore
Hbase在將資料寫入StoreFile之前,會先寫入MemStore。MemStore是一個有序的記憶體緩衝器。當MemStore中的資料量達到設定的大小時(Flush Size),HRegionServer就會執行Flush操作,將MemStore中的資料flush到StoreFile中。
當HRegionServer正在將MemStore中的資料Flush到StoreFile時,MemStore還可以對外進行讀寫服務。這個是通過MemStore的滾動機制實現的。通過滾動MemStore,新的空的塊就可以接收變更,而老的滿的塊就會執行flush操作。
9、StoreFile/HFile
StoreFile是HFile的實現,對HFile做了一層包裝。HFile是資料真正儲存的地方。HFile是基於BigTable的SSTable File和Hadoop的TFile。HFile是以keyvalue的格式儲存資料的。(Hbase之前使用過Hadoop得MapFile,因為其效能上相當糟糕而放棄。)下圖是HFile中版本1的格式,版本2稍有改變(詳見Hbase wiki):
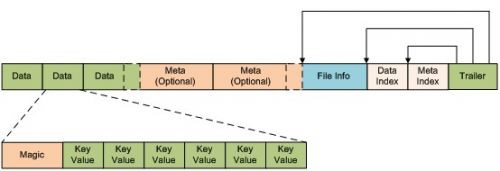
從上圖中看出,HFile是由多個數據塊組成。大部分資料塊是不定長的,唯一固定長度的只有兩個資料塊:File Info和Trailer。DataIndex和MetaIndex分別記錄了Data塊和Meta塊的起始位置。每個data塊由一些kevalue鍵值對和Magic header組成。Data塊的大小可以再建立表時通過HColumnDescriptor設定。Magic記錄了一串隨機的數字,防治資料丟失和損壞。
如果使用者想繞過Hbase直接訪問HFile時,比如檢查HFile的健康狀態,dump HFile的內容,可以通過HFile.main()方法完成。
如下圖是KeyValue的格式:

KeyValue是一個數組,對byte陣列做了一層包裝。Key Length和Value Length都是固定長度的數值。Key包含的內容有行RowKey的長度及值,列族的長度及值,列,時間戳,key型別(Put, Delete, DeleteColumn, DeleteFamily)。
從上圖可以看出,每一個keyValue只包含一列,即使對於同一行的不同列資料,會建立多個KeyValue例項。此外KeyValue不能被Split,即使此KeyValue值超過Block的大小,比如:
Block大小為16Kb,而KeyValue值有8Mb,那麼KeyValue會通過相連的多個Block進行儲存。
3)總結
以上對Hbase的基本元素做了一個大體的介紹。下圖是Hbase的儲存結構圖。記錄了客戶端發起變更或者新增操作時,Hbase內部的儲存流程。
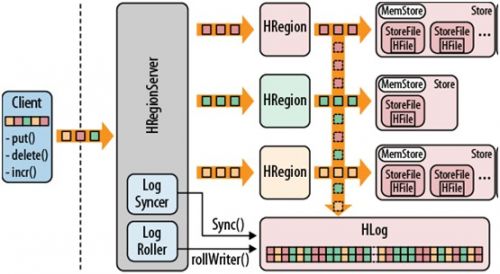
下面來分析下整個儲存流程:
1)當客戶端提交變更操作(如插入put,刪除delete,計數新增incr),首先客戶端會連線上Zookeeper找到-Root-表的儲存位置,然後根據-Root-表所提供的.Meta.表的位置找到對應的Region所在的HRegionServer。資料變更資訊會先通過HRegionServer寫入一個commit log,也就是WAL。當寫入WAL成功後,資料變更資訊會存到MemStore中。當MemStore達到設定的maximum value(hbase.hregion.memstore.flush.size,預設64MB)後,MemStore就會開始進行Flush操作,將其內容持久化到一個新的HFile中。在Flush操作過程中,MemStore通過滾動機制繼續對使用者提供讀寫服務。隨著Flush操作的不斷進行,HFile檔案越來越多。 當HFile檔案超過設定的數量後,Hbase的HouseKeeping機制就會通過Compaction特性將HFile小檔案合併成一個更大的HFile檔案。在Compaction的過程中,會進行版本的合併以及資料的刪除。由於storeFiles是不變的,使用者執行刪除操作時,並不能簡單地通過刪除其鍵值對來刪除資料內容。Hbase提供了一個delete marker機制(也稱為tombstone marker),會告訴HRegionServer那個指定的key已經被刪除了。這樣其它使用者檢索這個key的內容時,因為已經被標記為刪除,所以也不會檢索出來。在進行Compaction操作中就會丟棄這些已經打標的記錄。經過多次Compaction後,HFile檔案會越來越大,當達到設定的值時,會觸發Split操作。將當前的Region根據RowKey對等切分成兩個子Region,當期的那個Region被廢棄,兩個子Region會被分配到其他HRegionServer上。所以剛開始時一個表只有一個Region,隨著不斷的split,會產生越來越多的Region,通過HMaster
的LoadBalancer調整,Region會均勻遍佈到所有的HRegionServer中。
2)當HLog滿時,HRegionServer就會啟動LogRoller,通過執行rollWriter方法將那些所有sequence number均小於最大的那個sequence number的logfile移動到.oldLog目錄中等待被刪除。如果使用者設定了Deferred Log Flush為true,HRegionServer會快取有關此表的所有變更,並通過LogSyncer呼叫sync()方法定時將變更資訊同步到filesystem。預設為false的話,一旦有變更就會立刻同步到filesystem。
3)在一個HRegionServer中只有一個WAL,所有Region共享此WAL。HLog會根據Region提交變更資訊的先後順序依次順序寫入WAL中。如果使用者設定了setWriteToWAL(false)方法,則有關此表的所有Region變更日誌都不會寫入WAL中。這也是上圖中Region將變更日誌寫入WAL的那個垂直向下的箭頭為什麼是虛線的原因。
三、Hbase基本操作
Hbase中主要的客戶端介面是HTable類,HTable提供了對資料的所有CRUD操作。需要注意的是由於建立HTabe例項比較耗時, 所以在實際使用中最好建立單例模式的HTable例項,不過如果需要多個HTable例項的話,可以考慮使用HBase的HTablePool特性(下面後講到)。Hbase不提供直接的update操作。由於Hbase中資料儲存有版本支援。所以如果需要update一條記錄,一般是通過put操作,這樣歷史版本會在Compaction操作中被合併掉,這樣就間接實現了更新。(在MemStore中有一個變數MemstoreTS,該變數是隨put操作而遞增的。比如首先往列A,timeStamp為T1上put一條資料data1,假設此時MemstoreTS為1;之後如果想更新這條資料,只需要往列A,timeStamp為T1上put一條資料data2,此時MemstoreTS為2,Hbase會自動會將MemstoreTS大的排在前面。MemstoreTS小的在Compaction過程中就被過濾掉了。)
1)put操作
Put操作就是講資料插入到Hbase中。有兩種模式,一種是對單行的操作(single put);還有一種是對多行的操作(List of put)。針對單行操作的方式如下:
1、建立put例項有如下建構函式:需要使用者指定某行,使用者也可以設定時間戳作為版本標示。此外,使用者還可以加入自定義的行鎖,以防其它使用者或者其它執行緒在變更期間訪問此行的資料。
Put(byte[] row)
Put(byte[] row, RowLock rowLock)
Put(byte[] row, long ts)
Put(byte[] row, long ts, RowLock rowLock)
在Hbase中引數的傳遞大多是byte陣列型別。Hbase提供了許多靜態方法將java型別轉換成byte陣列型別。如下:
static byte[] toBytes(ByteBuffer bb)
static byte[] toBytes(String s)
static byte[] toBytes(boolean b)
static byte[] toBytes(long val)
static byte[] toBytes(float f)
static byte[] toBytes(int val)
2、一旦建立好put例項後,就可以通過put類提供的方法插入資料了。插入資料的操作需要指定列族,所在列等。如下:
Put add(byte[] family, byte[] qualifier, byte[] value)
Put add(byte[] family, byte[] qualifier, long ts, byte[] value)
Put add(KeyValue kv) throws IOException
3、put組裝完成後,就可以通過HTable提供的void put(Put put)throws IOException完成資料的插入操作。
如果需要對多行進行put操作,可以組裝一系列的put例項,然後呼叫HTable提供的void put(List puts) throws IOException來完成多行插入操作。不過需要指出的是:如果在這多個Put例項中存在一個put例項有誤(比如:往一個不存在的列族中插入資料),那麼該put例項會報錯,但是不影響其他的put例項。跟後面的get操作有點區別。
此外,Hbase還提供了一個原子型的put操作:Atomic compare-and-set ,方法如下:boolean checkAndPut(byte[] row, byte[] family, byte[] qualifier,byte[] value, Put put) throws IOException。只有校驗成功後才會完成put操作.
需要注意的是,因為每次的put操作相當於一個RPC,將資料從客戶端傳遞到服務端並返回。如果你的應用中RPC非常頻繁,比如一秒內成千上萬次,可能會有隱患。解決的辦法就是儘量降低RPC次數,Hbase提供了一個嵌入的客戶端寫快取器(Client-side Write Buffer)。它會快取所有的put操作,然後再一次性提交。預設情況下Client-side Write Buffer是沒有啟用的。使用者可以在建立HTable的時候通過呼叫table.setAutoFlush(false)方法來啟用它。並且可以通過isAutoFlush()來檢查是否已經啟用。預設是true,表示一旦有put操作會立即傳送到伺服器端。當你想將所有put操作提交到伺服器端時,可以呼叫flushCommits()操作。它會將快取器中所有變更提交到遠端伺服器。Client-side Write Buffer還會自動對buffer中的所有變更進行分組,同一個HRegionServer的分到同一個組。這樣每個HRegionServer通過一個RPC傳送.
2)get操作
Get操作就是從伺服器端獲取資料。跟put操作一樣,get操作也分為兩種模式,一種是對單行的get操作(single get),另一種是對多行進行檢索操作(List of gets)。
1、HTable提供的get方法如下:其返回值為Result類,該類包含了列族,列,keyvalue,
RowKey等資訊。該類提供的豐富的方法供使用者獲取返回的各種資訊。
Result get(Get get) throws IOException
2、Get類的建構函式如下,需要使用者傳入指定的行及行鎖等引數。
Get(byte[] row)
Get(byte[] row, RowLock rowLock)
3、 一旦建立的get例項後,使用者可以呼叫Get類提供的如下方法來框定你需要檢索的資料。如下:使用者可以指定列族,列,時間戳,最大版本號等。如果不設定版本號,預設是1,表示最大的版本。
Get addFamily(byte[] family)
Get addColumn(byte[] family, byte[] qualifier)
Get setTimeRange(long minStamp, long maxStamp) throws IOException
Get setTimeStamp(long timestamp)
Get setMaxVersions()
Get setMaxVersions(int maxVersions) throws IOException
跟List of put 類似,對於多行的檢索操作,HTable也提供了類似的如下方法:使用者只要建立多個get例項,就可以通過如下方法獲取需要的資料。不過需要注意的是:跟List of put不同的是,如果Get例項列表中只要存在一個Get例項有誤(比如get一個不存在的列族的值),那麼整體就會丟擲一個異常.
Result[] get(List gets) throws IOException
3)delete操作
Delete操作也類似,HTable提供了兩種方法,支援單個delete例項和多個delete例項的操作。如下:
void delete(Delete delete) throws IOException
void delete(List deletes) throws IOException
1、相應的delete例項建構函式有:
Delete(byte[] row)
Delete(byte[] row, long timestamp, RowLock rowLock)
2、如果你需要新增一些限制條件,可以使用delete類提供的相關方法,支援指定列族,列,時間戳等。如果你指定了一個時間戳,則表示小於等於該時間戳的時間將被刪除。如果指定了列和行號,但沒有指定時間戳,則預設會刪掉版本號最大的那個值。
Delete deleteFamily(byte[] family)
Delete deleteFamily(byte[] family, long timestamp)
Delete deleteColumns(byte[] family, byte[] qualifier)
Delete deleteColumns(byte[] family, byte[] qualifier, long timestamp)
Delete deleteColumn(byte[] family, byte[] qualifier)
Delete deleteColumn(byte[] family, byte[] qualifier, long timestamp)
void setTimestamp(long timestamp)
3、當使用List of delete時,如果有一個delete例項出錯,那麼會丟擲異常。而且delete的例項列表中只會存在那個出問題的delete例項。Delete也支援原子型的Compare-and- Delete,如下:
boolean checkAndDelete(byte[] row, byte[] family, byte[] qualifier,byte[] value, Delete delete) throws IOException
4)Batch操作
Hbase還支援批量操作。其實上面所談到的List of puts,gets,deletes都是基於Batch操作來的。不過List of puts,gets,deletes逐漸會被廢棄。推薦使用Batch操作。HTable提供的batch操作方法如下:引數中Row類是Put,Delete,Get類的父類。表示使用者可以同時傳入put,get及delete例項操作。不過在一個batch中,最好不要同時傳入針對同一行的put和delete例項。
(1) void batch(List actions, Object[] results) throws IOException, InterruptedException
(2) Object[] batch(List actions) throws IOException, InterruptedException上面這兩個batch方法比較類似,但有比較大的區別。第一個batch方法需要使用者傳遞一個數組,該陣列用來填充batch操作中所有成功的操作的結果集。如果沒有指定這個陣列,比如第二個方法。一旦batch操作中某一個例項出現問題,那麼Hbase只會丟擲一個異常。那些成功的操作的結果並不會返回。而第一個方法則會將那些成功的操作的結果集返回給使用者。
此外Batch操作不支援Client-side write buffer,Batch方法是同步的,會直接將其包含的操作發往伺服器。這點需要注意!
Batch操作返回的結果可能的結果有如下幾種:
1、null:表示那個操作操作連線遠端伺服器失敗。
2、Empty Result:put和delete操作的返回結果,表示操作成功。
3、Result:get操作的返回結果集
4、Throwable:異常結果
5)Scan操作
Scan操作類似於傳統的RDBMS中的遊標的概念。其目的跟get一樣,也是檢索伺服器端資料。Hbase也提供了一個Scan類。由於Scans類似於迭代器,所以你需要通過getScanner()方法獲取。HTable提供瞭如下方法:如果你看了原始碼就會知道,後面那兩個方法其實是先建立一個scan例項,並加入傳入的引數,然後再呼叫第一個方法。
ResultScanner getScanner(Scan scan) throws IOException
ResultScanner getScanner(byte[] family) throws IOException
ResultScanner getScanner(byte[] family, byte[] qualifier) throws IOException
1、Scan類提供了多個建構函式,如下:startRow和stopRow是左閉右開的。從建構函式中可以看出,使用者只需要指定rowKey的範圍,或者新增相應的過濾器,Hbase能夠自動檢索你指定的RowKey的範圍的資料。如果沒有指定startRow,預設從第一行開始.
Scan()
Scan(byte[] startRow, Filter filter)
Scan(byte[] startRow)
Scan(byte[] startRow, byte[] stopRow)
2、當建立好Scan例項後,如果想新增更多的限制條件,可以通過呼叫Scan提供的如下方法:允許新增列族,列,時間戳等.
Scan addFamily(byte [] family)
Scan addColumn(byte[] family, byte[] qualifier)
Scan setTimeRange(long minStamp, long maxStamp) throws IOException
Scan setTimeStamp(long timestamp)
Scan setMaxVersions()
Scan setMaxVersions(int maxVersions)
GetScanner()方法返回的是一個ResultScanner例項。需要注意的是:如果結果集存在多行,Scans並不會一次性將所有行在一個RPC裡面傳送給客戶端,而是基於一行一行傳送。這樣做主要是因為多行需要耗費大量時間。
ResultScanner類包裝了Result類將其每行結果以迭代的方式輸出,使得Scan操作類似於get操作。此外ResultScanner類提供瞭如下方法供使用者進行迭代使用:使用者可以選擇一次返回一行或者多行。不過不要認為是伺服器端一次性返回多行。其實是客戶端迴圈呼叫nbRows 次next()方法而已。伺服器端在一個RPC裡面還是隻傳送一行資料。這個確實有點影響心情,但Hbase就喜歡噁心下你,不過它也提供的相應的解決辦法:Scanner Caching,預設是關閉的。
Result next() throws IOException
Result[] next(int nbRows) throws IOException
void close()
close()方法表示釋放ResultScanner例項。因為ResultScanner例項持有了一定的資源,如果不及時釋放,可能隨著時間推移會佔用很大的記憶體空間。此外,close()操作最好放在finally模組,原因你懂得!
四、Hbase特性
HBase提供了許多賞心悅目的特性。如Filters,Counters,Coprocessors,Compaction,HTablePool等。
1)Filters
當你通過Scan或者Get操作檢索資料時,會發現Scan和Get只支援基於RowKey,列族,列,時間戳等粗粒度的檢索。如果使用者想基於Key或者Value或者正則表示式等作為查詢條件進行查詢的話,Scan和Get是沒辦法做到的。而Filter就是幹這事的。Hbase提供了一系列的Filters,使用者只要實現Filter,也可以自定義Filters。
需要說明的是Hbase提供的這些Filters都是配置在客戶端,但應用在伺服器端,也叫做Predicate push-down。(比如使用者在進行Scan操作時可以傳入Filter,序列化後傳送到伺服器端,HRegionServer就會將其反序列化,並應用到內部Scanner)。這樣可以有效減少資料傳輸帶來的網路開銷。
需要注意的是:Filters的通用約定是過濾掉你不需要的資料,而不是用來指定你需要的資料。不過凡是繼承CompareFilter過濾器的Filter,其作用剛好相反,用來指定你需要的資料。
Hbase提供的Filters有:
Ⅰ. Comparison Filters
Compartison Filters是基於比較的過濾器。定義如下:
CompareFilter(CompareOp valueCompareOp,WritableByteArrayComparable valueComparator)
該構造器有兩個特定的引數,一個是比較運算子,另一個是比較器。
A、常見的比較運算子有:
LESS,LESS_OR_EQUAL,EQUAL,NOT_EQUAL,GREATER_OR_EQUAL,GREATER,NO_OP。前面幾個運算子根據名字定義就能判斷其意思,最後一個是NO_OP,表示排除任何資料。
B、常見的比較器有:其中NullComparator是判斷給定的值是否為空或者非空。最後三個比較器只能搭配使用EQUAL,NOT_EQUAL比較運算子,返回0表示匹配,1表示不匹配。
BinaryComparator
BinaryPrefixComparator
NullComparator
BitComparator
RegexStringComparator
SubstringComparator
C、基於Comparison Filter的過濾器有好多種,比如:
1、RowFilter
2、FamilyFilter
3、QualifierFilter
4、ValueFilter
5、DependentColumnFilter
(1) RowFilter過濾器顧名思義就是根據RowKey來過濾資料。所以RowFilter中的比較運算子和比較器引數都是基於RowKey來比較的。比如如下Filter表示RowKey包含-4的資料。
Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL,new SubstringComparator("-4"))。
(2) FamilyFilter過濾器跟RowFilter類似,不過FamilyFilter是基於ColumnFamily的比較。
QualifierFilter和ValueFilter過濾器也類似,分別是基於列和數值的比較。
(3) DependentColumnFilter過濾器稍微複雜一點。它可以說是timeStamp Filter和ValueFilter的結合。因為DependentColumnFilter需要指定一個參考列,然後獲取跟改參考列有相同時間戳的所有列,再在此基礎上獲取滿足ValueFilter的列值。建構函式如下:使用者可以根據自己喜好省略valueFilter或者通過設定dropDependentColumn為true省略timestamp Filter。不過需要注意的是:此過濾器不能跟Scan中的Batch操作結合使用。
A、DependentColumnFilter(byte[] family, byte[] qualifier)
B、DependentColumnFilter(byte[] family, byte[] qualifier,boolean dropDependentColumn)
C、DependentColumnFilter(byte[] family, byte[] qualifier,boolean dropDependentColumn, CompareOp valueCompareOp,WritableByteArrayComparable valueComparator)
Ⅱ. Dedicated Filters
專有的一些過濾器,Hbase提供了許多個性化的專有過濾器。常見的Dedicated Filters有:
A、SingleColumnValueFilter
B、SingleColumnValueExcludeFilter
C、PrefixFilter
D、PageFilter
E、KeyOnlyFilter
F、FirstKeyOnlyFilter
G、InclusiveStopFilter
H、TimestampsFilter
I、ColumnCountGetFilter
J、ColumnPaginationFilter
K、ColumnPrefixFilter
L、RandomRowFilter
(1) 如果你想分頁獲取資料,可以通過PageFilter來完成。ColumnPaginationFilter跟PageFilter類似,只不過PageFilter是基於行的分頁,而ColumnPaginationFilter是基於列的分頁。如:
ColumnPaginationFilter(int limit, int offset),表示獲取從offset列開始的連續limit列的資料。
(2) 如果只想獲取每一行的第一列的值,那麼FirstKeyOnlyFilter是不錯的選擇。此外,因為前面提到的Scan操作需要使用者指定一個startRow和EndRow,其中這兩個引數時左閉右開區間的。如果想EndRow也包含,可以通過InclusiveStopFilter來解決。如下:獲取從Row5至Row10的資料
。不過因為Hbase是字典排序的,所以得到的結果中可能會包含Row51,Row52等這些行的資料。
Filter filter = new InclusiveStopFilter(Bytes.toBytes("row-9"));
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes("row-5"));
scan.setFilter(filter);
ResultScanner scanner = table.getScanner(scan);
(3) 如果想獲取某個版本的所有資料。可以通過TimestampsFilter來設定,使用者需要傳入版本號。如下:
TimestampsFilter(List timestamps)
(4) PrefixFilter和ColumnPrefixFilter都是基於字首的過濾器,不過PrefixFilter是基於行的字首過濾,而後者是基於列的字首過濾。
(5) RandomRowFilter是基於隨機行的過濾器,使用者需要指定一個在0到1之間的隨機數,建構函式如下:如果chance大於1,則會返回所有行。如果小於0,則過濾掉所有行。
RandomRowFilter(float chance)
Ⅲ. Decorating Filters
Decorating Filters稱為裝飾型的過濾器。它的作用是為其他過濾器返回的結果提供一些附加的校驗操作。常見的Decorating Filters有:
A、SkipFilter
B、WhileMatchFilter
(1) SkipFilter包裝了其它的過濾器,只要被包裝的過濾器返回的結果中有一行的某一列或者某個KeyValue被過濾掉了,那麼SkipFilter會將該列或者KeyValue所處的整行全部過濾。被包裝的過濾器必須實現filterKeyValue()方法。因為SkipFilter會依靠filterKeyValue()返回的結果進行附加的處理。比如:
Filter filter = new ValueFilter(CompareFilter.CompareOp.NOT_EQUAL,new BinaryComparator(Bytes.toBytes("val-1")));
上面這樣一個filter,表示返回的結果中值不能等於val-1,這樣值為val-1的那個列就不會展示,但該行的其他列只要滿足值不等於val-1都會返回。
不過一旦使用了SkipFilter,如:Filter filter2 = new SkipFilter(filter);只要存在某一行中的某個列的值等於val-1,那麼該行的所有資料都不會返回。
(2) WhileMatchFilter跟SkipFilter類似,不過區別之處在於WhileMatchFilter一旦找到某一行中的某些列值或者KeyValue不滿足條件,那麼整個Scan操作就會被終止。SkipFilter只是會將此行過濾,不作為返回值,但Scan操作會繼續。
Ⅳ. Custom Filters
如果想實現自定義的Filter,可以實現Filter介面或者擴充套件FilterBase類。FilterBase類提供了基本的Filter實現。
如果使用者想在一次檢索資料的過程中使用多個Filter,那麼可以使用FilterList特性。其建構函式如下:
FilterList(List rowFilters)
FilterList(Operator operator)
FilterList(Operator operator, List rowFilters)
其引數operator其列舉值有兩個:MUST_PASS_ALL(表示返回的結果集資料必須通過所有過濾器的過濾),MUST_PASS_ONE(表示返回的結果集資料只要通過了其中一個過濾器就行)。
2)Counters
Hbase提供了計數器Counters機制。它將列當做Counters,通過對列的操作來完成計數。在命令列下使用者可以通過如下命令增加計數。
incr ‘
’,’’,’’,[]
如果想獲取當前計數器的值,可以通過get命令或者get_counter或者incr命令。如下:
get ‘
’,’’;
get_counter ‘
’,’’;
incr ‘
’,’’,’’,0;
第一個和第二個的區別就是第一個返回的值是位元組陣列型別,使用者很難立刻知道到底代表什麼值。第二個返回的是可讀的值。第三個命令採用比較投機取巧的辦法,通過incr計數加0來返回當前值。如果將減少計數,可以通過incr命令來增加一個負數的值。
HTable提供了單個計數器(Single Counters)和多個計數器(Multiple Counters)。對於單個的Counters,需要指定準確的列名,跟命令列的incr一樣,可以通過增加正數和負數或者零來達到增加計數,減少計數以及訪問當期計數的目的。建構函式如下:
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier,long amount) throws IOException
long incrementColumnValue(byte[] row, byte[] family, byte[] qualifier,long amount, boolean writeToWAL) throws IOException
對於多重計數器,HTable提供的方法如下:
Result increment(Increment increment) throws IOException
1、使用者需要建立一個Increment例項,可以採用如下建構函式:
Increment() {}
Increment(byte[] row)
Increment(byte[] row, RowLock rowLock)
2、如果想為這個Increment例項新增必要的條件,如列名,或者時間戳範圍,可以通過如下方法來完成。可以在一個Increment例項中通過增加多列來實現多重計數器。
Increment addColumn(byte[] family, byte[] qualifier, long amount)
Increment setTimeRange(long minStamp, long maxStamp) throws IOException
3)Coprocessors
Coprocessors是Hbase提供的另一大特性。可以認為是簡化的MapReduce元件。Coprocessors是一組內嵌於RegionServer和HMaster程序的框架(BigTable的coprocessors擁有獨立程序和地址空間),支援使用者請求在每個Region上並行執行,類似於傳統資料庫中觸發器的功能。
1、Hbase提供的Coprocessors有兩種型別:observer和endpoint。其中observer類似於RDBMS中的觸發器,即鉤子函式,其程式碼部署在伺服器端執行,在真實的方法前新增pre(),實現後加入
post(),以實現對真實方法的輔助操作。而endpoint類似於儲存過程。
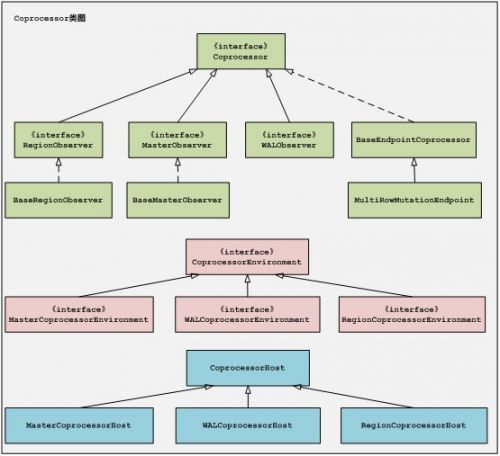
2、Coprocessors框架有三個模組組成:Coprocessors,CoprocessorEnvironment,
CoprocessorHost。CoprocessorEnvironment提供Coprocessors例項執行的環境以及持有
Coprocessors例項的生命週期狀態。CoprocessorHost是用來維護Coprocessors例項和
Coprocessors執行環境的。
三元體類圖如下(Hbase94版本):使用者可以通過繼承BaseRegionObserver, WALObserver,
BaseMasterObserver或者BaseEndpointCoprocessor來實現自定義的Coprocessors。
A、coprocessors Load
Coprocessors有兩種載入方式:通過配置檔案方式的靜態載入和動態載入方式。
a、配置檔案載入
靜態載入方式就是通過hbase-site.xml配置檔案配置指定的coprocessors來載入。配置方式如下,其執行順序就是按照配置檔案指定的順序:
hbase.coprocessor.region.classes
coprocessor.RegionObserverExample,coprocessor.otherCoprocessor
hbase.coprocessor.master.classes
coprocessor.MasterObserverExample
hbase.coprocessor.wal.classes
coprocessor.WALObserverExample, bar.foo.MyWALObserver
需要注意的是:通過這種方式載入的RegionObserver是針對所有Region和表的。使用者無法指定某一具體的Region或者table。
b、通過table description載入
通過這種方式的載入是細化到具體的表的維度。只有跟該表有關的Region操作才會載入。所以這種方式的載入只能針對RegionCoprocessor。載入方法是:
HTableDescriptor.setValue(),其中key是Coprocessor,value是||
B、observer
observer又有三種實現型別:
a、RegionObserver
RegionObserver一般用來進行資料操作的coprocessor,比如資料訪問前的許可權身份驗證,Filter,二級索引等。如:
void preFlush(...) / void postFlush(...) MemStore中內容flush到Storefile前後新增輔助型操作。
void preGet(...) / void postGet(...) 獲取資料的前後新增輔助操作
b、MasterObserver
MasterObserver是面向整個叢集的事件,比如基於管理員的操作和DDL型別的操作的監控。如:
void preCreateTable(...) / void postCreateTable(...) 建立表前後做些輔助操作
void preAddColumn(...) / void postAddColumn(...) 建立列前後做些輔助操作
void preMove(...) / void postMove(...) 移動Region的前後新增輔助操作
c、WALObserver
WALObserver則是提供鉤子函式對Write Ahead Log的的操作。
C、Endpoint
Endpoint動態擴充套件了RPC協議。只支援Region的操作,不支援Master和WAL的操作。使用者可以通過Endpoint完成一些聚集函式的功能,如AVG,Count,SUM等。其原理是通過包裝客戶端的實現,類似於MapReduce,比如getSum()操作,Map端endpoint通過並行的scan完成對每個Region的操作,每個Region的scan結果彙總到endpoint包裝的客戶端,將每個Region反饋的結果進行彙總即可得到getSum()的結果。
D、小結
a、Coprocessors有兩種型別:observer和endpoint。observer類似於傳統的關係型資料庫中的觸發器,通過鉤子函式來完成對被鉤的方法的輔助功能,endpoint類似於關係型資料庫中的儲存過程,用來實現聚合函式的相關功能。
b、Coprocessors支援動態載入,擁有多種載入方式。
c、Coprocessors可以將多個Coprocessor連結在一起使用,類似於Servlet中的filters過濾器。
d、Coprocessors中有優先順序的概念,SYSTEM級別的Coprocessor優先處理,USER級別的Coprocessor優先順序更低。
4)Split And Comcaption
A、Region Split
當建立一個表時,此時該表只對應一個Region。隨著不斷了往表中插入記錄,表資料越來越多,當超過設定的值hbase.hregion.max.filesize時,該Region就會Split成兩個子Region。原來的那個Region就會被刪除。具體操作如下:
a、HRegionServer建立一個splits目錄,並且關閉其父Region以防接收其它請求。
b、HRegionServer會在splits目錄準備好兩個子Region,父Region的RowKey對半切。然後將其移動到表目錄下,並且更細.Meta.表的資料,指示該父Region正在被執行Split操作。
c、讀取父Region的資料到子Region中。更新.Meta.表。
d、清理父Region,通知HMaster將新的子Region遷移到其它RegionServer中。
Split過程核心程式碼如下:如果想了解有關Split的詳細流程,可以參考:
http://punishzhou.iteye.com/blog/1233802
B、Compaction
當Hbase將MemStore中的內容flush到StoreFile中後,由於每次flush都會產生一個新的HFile檔案。隨著一次次的flush,HFile檔案越來越多,當達到設定的閥值時,Hbase提供了Compaction特性,會通過此機制將HFile檔案進行壓縮。
Compaction機制分為兩種方式:minor compactions和major compactions 。minor compactions是將相鄰的一些小的HFile合併成一個稍大的HFile,表演一個多路合併的過程,其檔案的數目由(hbase.hstore.compaction.min)指定;而major compactions會將一個Store中的所有HFile合併成一個HFile,並且在壓縮的過程中會進行版本合併和刪除過濾操作。比如對於那些同一個Cell中且同一個時間戳的資料,只保留最新的那個值,其他的值將被廢棄。此外標記了刪除樣式的資料以及過期的資料也將被過濾。
其實Compaction就是將多個有序的HFile檔案合併成一個有序的HFile檔案的一個過程。它會建立一個StoreFileScanner來包裝每一個StoreFile,然後再通過一個StoreFileScanner例項來組裝StoreFile對應的StoreFileScanner列表。通過StoreFileScanner例項提供的next()和seek()方法獲取每個storeFile中的資料,最後再將此資料append到一個新的HFile中。
5)HTablePool
如果使用者每次發起一個請求時都建立一個HTable例項,如下建立方式:
Configuration conf = HBaseConfiguration.create();
HTable table = new HTable(conf, "testtable");
這種方式雖然可以滿足要求,但對於請求數比較多的情況或者要求響應時間比較快的情況,如上建立HTable例項就比較落伍了。因為建立Htable是一個比較耗時的過程,此外,HTable並不能保證執行緒安全,在多執行緒處理下就可能產生莫名其妙的問題。
HBase提供了HTable池特性可以解決此問題。使用者可以直接從HTable池中獲取HTable例項。
1、可以通過如下建構函式來建立HTablePool例項,如下:
HTablePool()
HTablePool(Configuration config, int maxSize)
HTablePool(Configuration config, int maxSize,HTableInterfaceFactory tableFactory)
上面的第一個建構函式會預設獲取classpath下的配置,並且建立無窮大的HTable個數。使用者可以提供定製的建立的HTable例項的工廠來,這樣建立的HTablePool中的HTable就是使用者定製的
HTable例項。maxSize引數是指定HTable池中最大持有多少個HTable例項。比如如果此size為5,
而使用者通過getTable獲取了10次引用,那麼當用戶通過putTable方法將例項放回HTable池中時,只能放回5個例項,另外的5次將被忽略掉了。
2、建立HTablePool例項後,就可以通過getTable方法獲取對應的表的HTable例項了。如下:
HTableInterface getTable(String tableName)
HTableInterface getTable(byte[] tableName)
3、當使用完HTable例項後,需要將HTable例項關閉,可以採用如下方法:
void closeTablePool(String tableName)
void closeTablePool(byte[] tableName)
void putTable(HTableInterface table)
closeTablePool(tableName)相當於直接將此Table例項關閉。建議使用此方法。PutTable(FilterBase)表示將此例項放回HTable池中供下次使用。建議不要使用此方法,目前此方法也在逐漸廢棄。需要注意的是以上操作最好放到finally模組進行處理。
五、總結
A、總的來說Hbase因為其面向列族的key-value儲存特性使得其擁有列式資料庫的優勢。分散式的Hbase應用是由客戶端和服務端程序組成,通過HDFS作為其持久層,採用Zookeeper來完成叢集的管理和狀態監控協調服務。對於全表掃描和大資料的載入通過MapReduce來完成。Hbase無縫集成了Apache的這幾大元件來實現可伸縮,面向列族的分散式儲存系統。
B、Hbase是嚴格一致性的分散式儲存系統,從兩個方面來保證嚴格一致性問題:它提供行鎖,但不提供多行鎖和事務,保證了讀寫的原子性。此外Hbase資料儲存支援多版本和時間戳的特性。
C、Hbase可以認為是BigTable的開源實現,但跟BigTable還是有很多區別。比如:Hbase的Coprocessors跟BigTable不同。Hbase支援伺服器端的Filter以減少網路傳輸開銷。此外Hbase支援可插拔的檔案系統,目前檔案系統是HDFS,BigTable是GFS。
D、Hbase通過實現伺服器端的鉤子(Coprocessors)來完成二級索引。這也是BigTable沒有實現的。
