
偽分散式的搭建(啟動HDFS並執行MapReduce程式)
如果前一章測試成功,那麼恭喜你,你已經可以開始新的篇章了(但是如果測試不成功,請務必搭建測試成功後再看此篇章)
偽分散式的搭建(啟動HDFS並執行MapReduce程式)
1、啟動HDFS並執行MapReduce程式
1.1配置偽分散式叢集
1.1.1 配置hadoop-env.sh
切換到當前目錄中:
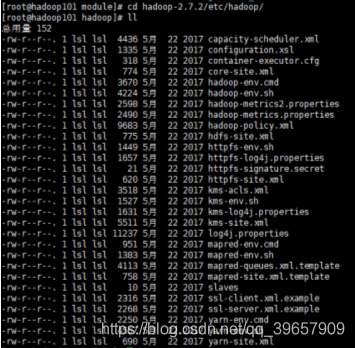
修改hadoop-env.sh的JAVA_HOME 路徑:vim hadoop-env.sh
新增如下內容:

1.1.2配置core-site.xml
執行命令:vim core-site.xml
檔案加入如下文字:
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</ 1.1.3 配置hdfs-site.xml
執行命令:vim hdfs-site.xml
<!-- 指定HDFS副本的數量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
1.2啟動叢集
1.2.1切換到當前目錄
1.2.2格式化NameNode
執行命令:bin/hdfs namenode -format
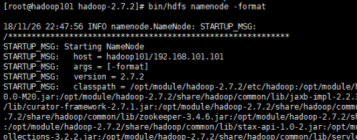
1.2.3啟動NameNode(執行成功後可執行JPS看是否啟動成功)
執行命令:sbin/hadoop-daemon.sh start namenode

1.2.4啟動DataNode
執行命令:sbin/hadoop-daemon.sh start datanode

1.2.5注意的一些事項
1.格式化NameNode,會產生新的叢集id,導致NameNode和DataNode的叢集id不一致,叢集找不到已往資料,而導致叢集啟動異常。
所以,再次格式NameNode時,一定要先刪除data資料和log日誌,然後再格式化NameNode。(當然也還有其他辦法,但是這個是最直接了當的!!!)
2.JPS執行無效
原因:全域性變數hadoop、java沒有生效,需要source /etc/profile檔案。
1.3檢視叢集
1.3.1web端檢視HDFS檔案系統
瀏覽器中檢視:http://Linux ip地址:50070/dfshealth.html#tab-overview
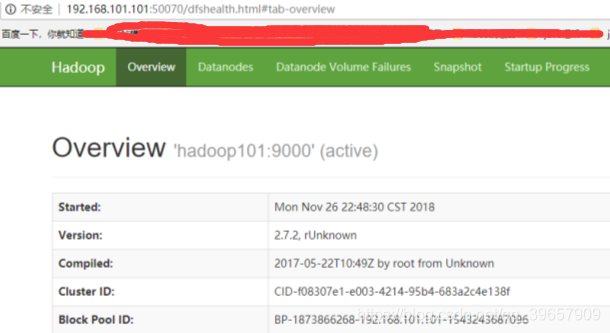
如果不能檢視,看如下帖子處理:http://www.cnblogs.com/zlslch/p/6604189.html
1.4操作叢集
1.4.1切換到當前目錄
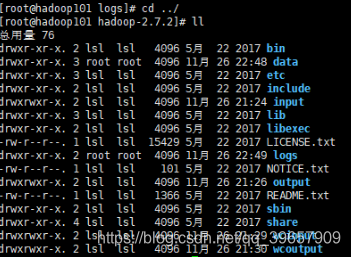
1.4.2在HDFS檔案系統上建立一個input資料夾
執行命令:bin/hdfs dfs -mkdir -p /user/lsl/input
1.4.3將測試檔案內容上傳到檔案系統上
執行命令:bin/hdfs dfs -put wcinput/wc.input /user/lsl/input/
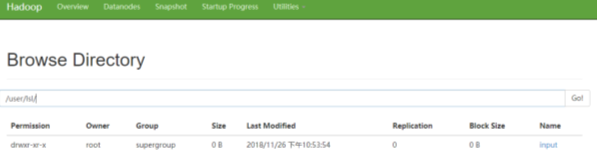
1.4.4檢視上傳的檔案是否正確
1.執行命令:bin/hdfs dfs -ls /user/lsl/input/

2.執行命令:bin/hdfs dfs -cat /user/lsl/input/wc.input

3.也可在瀏覽器上檢視
1.4.5執行MapReduce程式
執行命令:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/lsl/input/ /user/lsl/output
1.4.6檢視輸出結果
1.執行命令:bin/hdfs dfs -cat /user/lsl/output/*

2.在瀏覽器上檢視

1.4.7 將測試檔案內容下載到本地
執行命令:hdfs dfs -get /user/lsl/output/part-r-00000 ./wcoutput/

1.4.8刪除輸出結果
1.執行命令:hdfs dfs -rm -r /user/lsl/output

2.檢視:

版權宣告:本部落格為記錄本人自學感悟,轉載需註明出處!
https://me.csdn.net/qq_39657909