
Spark本地安裝及Linux下偽分散式搭建
title: Spark本地安裝及Linux下偽分散式搭建
date: 2018-12-01 12:34:35
tags: Spark
categories: 大資料
toc: true
個人github部落格:Josonlee’s Blog
文章目錄
前期準備
spark可以在Linux上搭建,也能不安裝hadoop直接在Windows上搭建單機版本。首先是從官網上
可以放心的是,spark安裝遠比hadoop安裝簡單的多
本地安裝
把下載的壓縮包解壓到本地某個位置上,修改環境變數,新增%SPARK_HOME%:解壓的位置;修改Path,增加一欄%SPARK_HOME%/bin
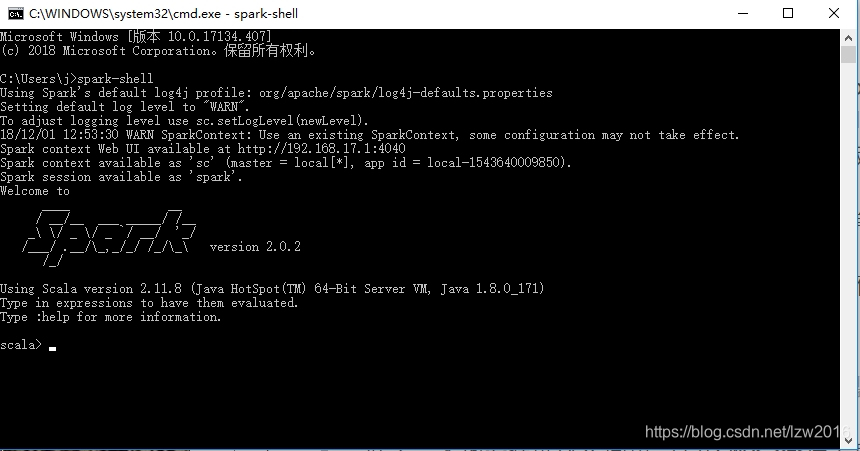
好了,本地安裝就這麼簡單。開啟CMD命令列工具,輸入spark-shell,如圖顯示就是安裝成功了
- Error:安裝後執行是有可能會遇到一個錯誤:
Failed to find Spark jars directory- 解決方法:安裝路徑名上不能有空格(比如Program Files就不行)
基於hadoop偽分散式搭建
將你下載的spark壓縮包,通過某些工具(我用的是WinSCP)上傳到虛擬機器中
有必要說一下,我的是centos7系統,hadoop也是偽分散式的,主從節點名namenode(具體的你可以看我之前搭建hadoop的部落格)
- 解壓到使用者目錄下(我這裡是
/home/hadoop)
# 上傳到了/root目錄下,cd到該目錄下執行 tar -zxvf spark-2.0.2-bin-hadoop2.6.tgz -C /home/hadoop
- 同本地安裝一樣,配置環境變數
- 可以選擇在系統環境變數中配置
/etc/profile,也可以選擇使用者環境變數中配置/home/hadoop/.bash_profile,推薦後者
- 可以選擇在系統環境變數中配置
vi .bash_profile
# 新增
export SPARK_HOME=/home/hadoop/spark-2.0.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
# 儲存退出後,source .bash_profile使配置生效
配置完成後同樣可以輸入spark-shell檢視執行
- 配置spark的設定檔案(conf目錄下)spark-env.sh和slaves
切換到spark下的conf目錄下,cd /home/hadoop/spark-2.0.2-bin-hadoop2.6/conf
spark沒有spark-env.sh和slaves檔案,只有以template結尾的兩個模板檔案,依據模板檔案生成即可cp spark-env.sh.template spark-env.sh,cp slaves.template slaves
# 修改spark-env.sh
vi spark-env.sh
# 增加類似下文內容
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.12.1
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop
export SPARK_MASTER_HOST=namenode
export SPARK_WORKER_MEMORY=1024m
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
像JAVA_HOME,HADOOP_HOME是你之前java和hadoop安裝的位置,可以使用echo JAVA_HOME檢視
SPARK_MASTER_HOST,spark也是主從關係,這裡指定spark主節點為hadoop的主節點名即可
後三行是預設配置,依你電腦配置可修改。分別代表worker記憶體、核、例項分配
# 修改slaves
vi slaves
# 增加從節點
namenode #因為是偽分散式,namenode既是主也是從
還有就是要注意,你之前配置hadoop時已經完成了ip和名的對映
以上內容完成後,就搭建完了
啟動spark
先完成一個事,你可以看到spark下sbin目錄中啟動和結束的命令是start-all.sh,stop-all.sh,和hadoop啟動結束命令重名了,用mv命令修改為start-spark-all.sh,stop-spark-all.sh就好了
- 啟動hadoop叢集
start-hdfs.sh,start-yarn.sh - 啟動spark
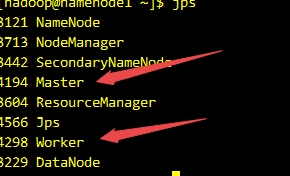
start-spark-all.sh - 使用jps命令檢視執行情況
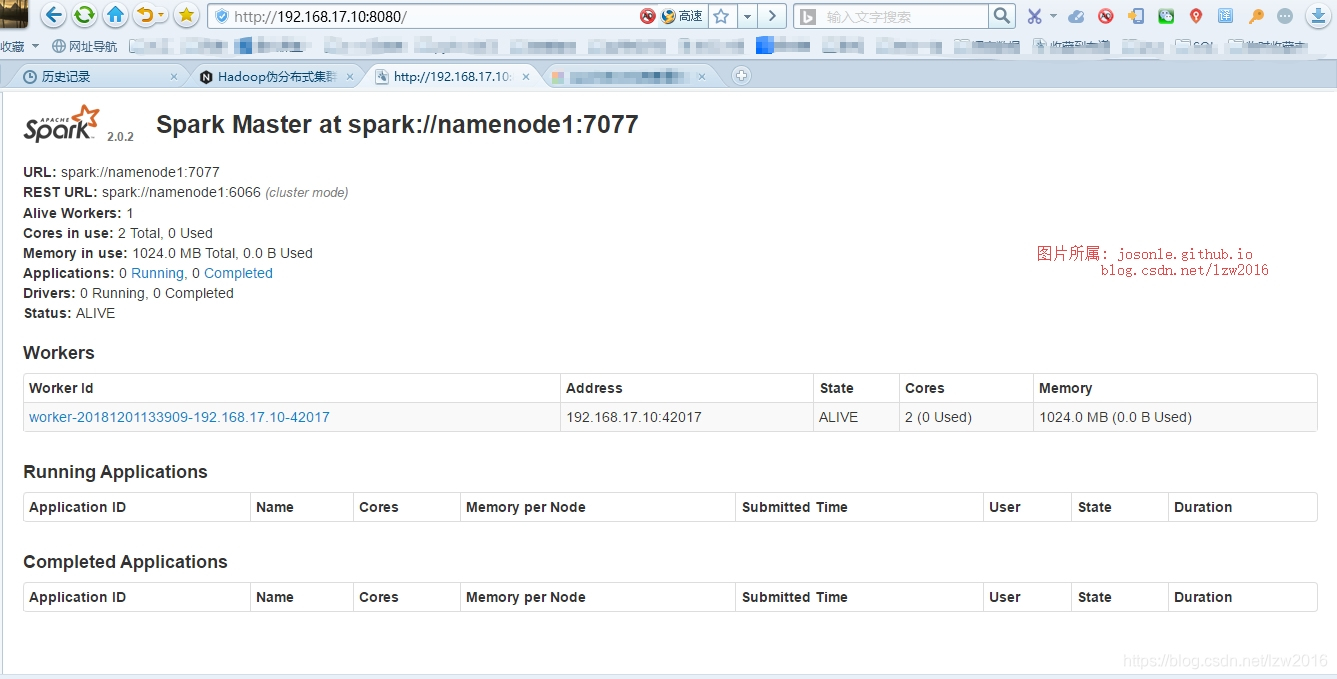
- 本地瀏覽器開啟
http://192.168.17.10:8080(這個IP是我之前在hadoop中配置的namenode的IP,埠是固定的)
安裝過程可能遇到的問題
在配置以上設定時,一定要分清楚,這都是我的環境設定,要合理的區分開。比如說你java,hadoop安裝的位置和我的不一樣等等
在替別人檢視這一塊配置時,它執行spark叢集時,遇到了幾個問題
- 使用者hadoop無許可權在spark下建立logs等目錄
- 通過
ls -l檢視spark-2.0.2-bin-hadoop2.6這個資料夾所屬組和使用者是root - 修改資料夾所屬組和使用者即可,
chown -R hadoop:hadoop /home/hadoop/spark-2.0.2-bin-hadoop2.6
- 通過
spark-class: line 71…No such file or directory,顯示大概是找不到java- 這個問題就是配置寫錯了,spark-env.sh中java_home寫錯了
spark完全分佈叢集搭建
過程和偽分散式搭建一樣,不同在於slaves中設定的從節點名為datanode1、datanode2類似的
然後,再複製到從節點主機中,如scp -r /home/hadoop/spark-2.0.2-bin-hadoop2.6 datanode1:/home/hadoop (這是因為之前配好了ssh免密登入)
版權宣告:本文為博主原創文章,未經博主允許不得轉載。
https://josonle.github.io
https://blog.csdn.net/lzw2016