
MapReduce程式的讀寫過程
阿新 • • 發佈:2018-12-08
問題導讀
1、HDFS框架組成是什麼?
2、HDFS檔案的讀寫過程是什麼?
3、MapReduce框架組成是什麼?
4、MapReduce工作原理是什麼?
5、什麼是Shuffle階段和Sort階段?
1.gif (12.87 KB, 下載次數: 4)
下載附件
儲存到相簿
2015-10-8 20:58 上傳
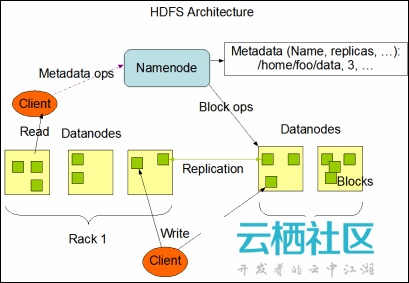
HDFS採用master/slaver的主從架構,一個HDFS叢集包括一個NameNode節點(主節點)和多個DataNode節點(從節點),並提供應用程式的訪問介面。NameNode,DataNode和Client的解釋,如下所示:
- NameNode負責檔案系統名字空間的管理與維護,同時負責客戶端檔案操作(比如開啟,關閉,重新命名檔案或目錄等)的控制及具體儲存任務的管理與分配(比如確定資料塊到具體DataNode節點的對映等);
- DataNode負責處理檔案系統客戶端的讀寫請求,提供真實檔案資料的儲存服務;
- Client是客戶端,一般指的是訪問HDFS介面的應用程式,或者HDFS的Web服務(就是讓使用者通過瀏覽器來檢視HDFS的執行狀況)等。
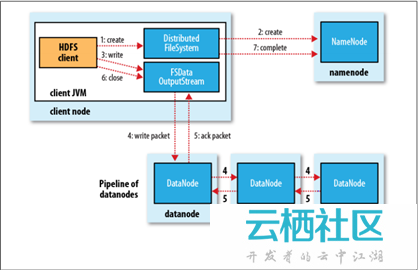
1. 檔案的讀取
Client與之互動的HDFS、NameNode、DataNode檔案的讀取流程,如下所示:
2.jpg (37.74 KB, 下載次數: 3)
下載附件
儲存到相簿
2015-10-8 20:58 上傳
- Client向遠端的NameNode發起RPC請求;(1)
- NameNode會返回檔案的部分或者全部Block列表,對於每個Block,NameNode都會返回該Block副本的DataNode地址;(2)
- Client會選擇與其最接近的DataNode來讀取Block,如果Client本身就是DataNode,那麼將從本地直接讀取資料;(3)
- 讀完當前Block後,關閉與當前的DataNode連線,併為讀取下一個Block尋找最近的DataNode;(4)
- 讀完Block列表後,並且檔案讀取還沒有結束,Client會繼續向NameNode獲取下一批Block列表;(5)
- 讀完一個Block都會進行Cheeksum驗證,如果讀取DataNode時出現錯誤,Client會通知NameNode,然後從該Block的另外一個最近鄰DataNode繼續讀取資料。Client讀取資料完畢之後,關閉資料流。(6)
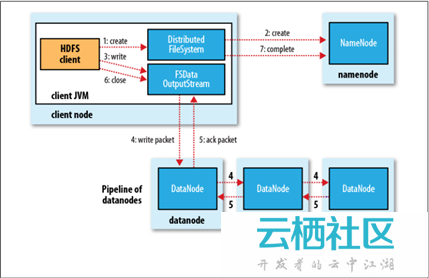
2. 檔案的寫入
Client與之互動的HDFS、NameNode、DataNode檔案的寫入流程,如下所示:
3.jpg (35.93 KB, 下載次數: 2)
下載附件
儲存到相簿
2015-10-8 20:58 上傳
- Client向遠端的NameNode發起RPC請求;(1)
- NameNode便會檢查要建立的檔案是否已經存在,建立者是否有許可權進行操作等,如果滿足相關條件,就會建立檔案,否則會讓Client丟擲異常;(2)
- 在Client開始寫入檔案的時候,開發庫(即DFSOutputStream)會將檔案切分成一個個的資料包,並寫入”資料佇列“,然後向NameNode申請新的Block,從而得到用來儲存複本(預設為3)的合適的DataNode列表,每個列表的大小根據NameNode中對replication的設定而定;(3)
- 首先把一個數據包以流的方式寫入第一個DataNode,其次將其傳遞給在此管線中的下一個DataNode,然後直到最後一個DataNode,這種寫資料的方式呈流水線的形式;(假設複本為3,那麼管線由3個DataNode節點構成,即Pipeline of datanodes)(4)
- 當最後一個DataNode完成之後,就會返回一個確認包,在管線裡傳遞至Client,開發庫(即DFSOutputStream)也維護著一個”確認佇列”,當成功收到DataNode發回的確認包後便會從“確認佇列”中刪除相應的包;(5)
- 如果某個DataNode出現了故障,那麼DataNode就會從當前的管線中刪除,剩下的Block會繼續在餘下的DataNode中以管線的形式傳播,同時NameNode會再分配一個新的DataNode,以保持replication設定的數量。Client寫入資料完畢之後,關閉資料流。(6)
說明:HDFS預設Block的大小為64M,提供SequenceFile和MapFile二種型別的檔案。
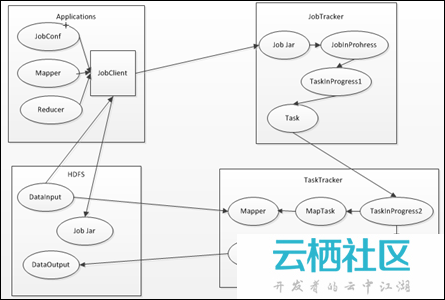
二. MapReduce框架組成
MapReduce框架的主要組成部分和它們之間的相關關係,如下所示:
4.jpg (40.03 KB, 下載次數: 10)
下載附件
儲存到相簿
2015-10-8 20:58 上傳
上述過程包含4個實體,各實體的功能,如下所示:
- Client:提交的MapReduce作業,比如,寫的MR程式,或者CLI執行的命令等;
- JobTracker:協調作業的執行,本質是一個管理者;
- TaskTracker:執行作業劃分後的任務,本質就是一個執行者;
- HDFS:用來在叢集間共享儲存的一種抽象檔案系統。
直觀來說,NameNode就是一個元資料倉庫,就像Windows中的登錄檔一樣。SecondaryNameNode可以看成NameNode的備份。DataNode可以看成是用來儲存作業劃分後的任務。在通常搭建的3臺Hadoop分散式叢集中,Master是NameNode,SecondaryNameNode,JobTracker,其它2臺Slaver都是TaskTracker,DataNode,並且TaskTracker都需要執行在HDFS的DataNode上面。
上述用到的類,或者程序的功能,如下所示:
- Mapper和Reducer
基於Hadoop的MapReduce應用程式最今本的組成部分包括:一個Mapper抽象類,一個Reducer抽象類,一個建立JobConf的執行程式。 - JobTracker
JobTracker屬於master,一般情況應該部署在單獨的機器上,它的功能就是接收Job,負責排程Job的每一個子任務Task執行在TaskTracker上,並且監控它們,如果發現有失敗的Task就重啟它即可。 - TaskTracker
TaskTracker是運行於多節點的slaver服務,它的功能是主動通過心跳與JobTracker進行通訊接收作業,並且負責執行每一個任務。 - JobClient
JobClient的功能是在Client提交作業後,把一些檔案上傳到HDFS,比如作業的jar包(包括應用程式以及配置引數)等,並且把路徑提交到JobTracker,然後由JobTracker建立每一個Task(即MapTask和ReduceTask)並將它們分別傳送到各個TaskTracker上去執行。 - JobInProgress
JobClient提交Job後,JobTracker會建立一個JobInProgress來跟蹤和排程這個Job,並且把它新增到Job佇列中。JobInProgress根據提交的Job Jar中定義的輸入資料集(已分解成FileSplit)建立對應的一批TaskInProgress1用於監控和排程Task。 - TaksInProgress2
JobTracker通過每一個TaskInProgress1來執行Task,這時會把Task物件(即MapTask和ReduceTask)序列化寫入相應的TaskTracker中去,TaskTracker會建立對應的TaskInProgress2用於監控和排程該MapTask和ReduceTask。 - MapTask和ReduceTask
Mapper根據Job Jar中定義的輸入資料<key1, value1>讀入,生成臨時的<key2, value2>,如果定義了Combiner,MapTask會在Mapper完成後呼叫該Combiner將相同Key的值做合併處理,目的是為了減少輸出結果。MapTask全部完成後交給ReduceTask程序呼叫Reducer處理,生成最終結果<key3, value3>。具體過程可以參見[4]。
三. MapReduce工作原理
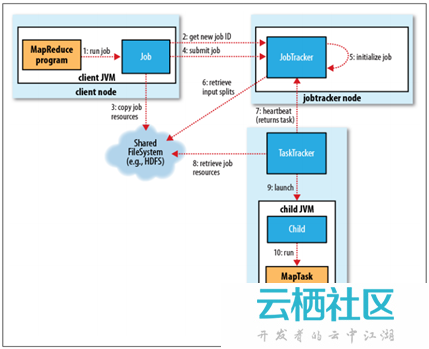
整個MapReduce作業的工作工程,如下所示:
5.jpg (47.39 KB, 下載次數: 3)
下載附件
儲存到相簿
2015-10-8 20:59 上傳
1. 作業的提交
JobClient的submitJob()方法實現的作業提交過程,如下所示:
- 通過JobTracker的getNewJobId()請求一個新的作業ID;(2)
- 檢查作業的輸出說明(比如沒有指定輸出目錄或輸出目錄已經存在,就丟擲異常);
- 計算作業的輸入分片(當分片無法計算時,比如輸入路徑不存在等原因,就丟擲異常);
- 將執行作業所需的資源(比如作業Jar檔案,配置檔案,計算所得的輸入分片等)複製到一個以作業ID命名的目錄中。(叢集中有多個副本可供TaskTracker訪問)(3)
- 通過呼叫JobTracker的submitJob()方法告知作業準備執行。(4)
2. 作業的初始化
- JobTracker接收到對其submitJob()方法的呼叫後,就會把這個呼叫放入一個內部佇列中,交由作業排程器(比如先進先出排程器,容量排程器,公平排程器等)進行排程;(5)
- 初始化主要是建立一個表示正在執行作業的物件——封裝任務和記錄資訊,以便跟蹤任務的狀態和程序;(5)
- 為了建立任務執行列表,作業排程器首先從HDFS中獲取JobClient已計算好的輸入分片資訊(6)。然後為每個分片建立一個MapTask,並且建立ReduceTask。(Task在此時被指定ID,請區分清楚Job的ID和Task的ID)。
3. 任務的分配
- TaskTracker定期通過“心跳”與JobTracker進行通訊,主要是告知JobTracker自身是否還存活,以及是否已經準備好執行新的任務等;(7)
- JobTracker在為TaskTracker選擇任務之前,必須先通過作業排程器選定任務所在的作業;
- 對於MapTask和ReduceTask,TaskTracker有固定數量的任務槽(準確數量由TaskTracker核的數量和記憶體大小來決定)。JobTracker會先將TaskTracker的MapTask填滿,然後分配ReduceTask到TaskTracker;
- 對於MapTrask,JobTracker通過會選取一個距離其輸入分片檔案最近的TaskTracker。對於ReduceTask,因為無法考慮資料的本地化,所以也沒有什麼標準來選擇哪個TaskTracker。
4. 任務的執行
- TaskTracker分配到一個任務後,通過從HDFS把作業的Jar檔案複製到TaskTracker所在的檔案系統(Jar本地化用來啟動JVM),同時TaskTracker將應用程式所需要的全部檔案從分散式快取複製到本地磁碟;(8)
- TaskTracker為任務新建一個本地工作目錄,並把Jar檔案中的內容解壓到這個資料夾中;
- TaskTracker啟動一個新的JVM(9)來執行每個Task(包括MapTask和ReduceTask),這樣Client的MapReduce就不會影響TaskTracker守護程序(比如,導致崩潰或掛起等);
- 子程序通過umbilical介面與父程序進行通訊,Task的子程序每隔幾秒便告知父程序它的進度,直到任務完成。
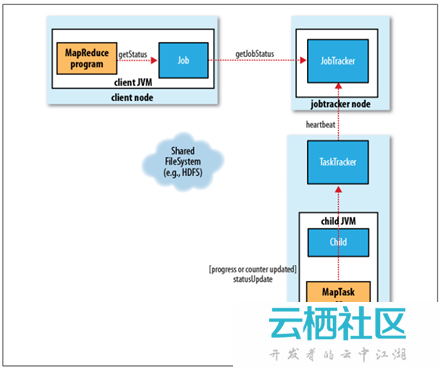
5. 程序和狀態的更新
一個作業和它的每個任務都有一個狀態資訊,包括作業或任務的執行狀態,Map和Reduce的進度,計數器值,狀態訊息或描述(可以由使用者程式碼來設定)。這些狀態資訊在作業期間不斷改變,它們是如何與Client通訊的呢?
6.jpg (37.92 KB, 下載次數: 3)
下載附件
儲存到相簿
2015-10-8 20:59 上傳
- 任務在執行時,對其進度(即任務完成的百分比)保持追蹤。對於MapTask,任務進度是已處理輸入所佔的比例。對於ReduceTask,情況稍微有點複雜,但系統仍然會估計已處理Reduce輸入的比例;
- 這些訊息通過一定的時間間隔由Child JVM—>TaskTracker—>JobTracker匯聚。JobTracker將產生一個表明所有執行作業及其任務狀態的全域性檢視。可以通過Web UI檢視。同時JobClient通過每秒查詢JobTracker來獲得最新狀態,並且輸出到控制檯上。
6. 作業的完成
當JobTracker收到作業最後一個任務已完成的通知後,便把作業的狀態設定為"成功"。然後,在JobClient查詢狀態時,便知道作業已成功完成,於是JobClient列印一條訊息告知使用者,最後從runJob()方法返回。
四. Shuffle階段和Sort階段
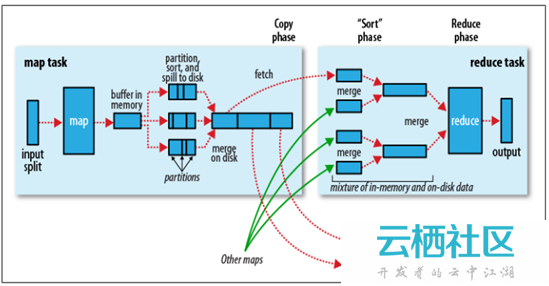
Shuffle階段是指從Map的輸出開始,包括系統執行排序以及傳送Map輸出到Reduce作為輸入的過程。Sort階段是指對Map端輸出的Key進行排序的過程。不同的Map可能輸出相同的Key,相同的Key必須傳送到同一個Reduce端處理。Shuffle階段可以分為Map端的Shuffle和Reduce端的Shuffle。Shuffle階段和Sort階段的工作過程,如下所示:
7.jpg (61.79 KB, 下載次數: 3)
下載附件
儲存到相簿
2015-10-8 20:59 上傳
如果說以上是從物理實體的角度來講解MapReduce的工作原理,那麼以上便是從邏輯實體的角度來講解MapReduce的工作原理,如下所示:
1. Map端的Shuffle
- Map函式開始產生輸出時,並不是簡單地把資料寫到磁碟,因為頻繁的磁碟操作會導致效能嚴重下降。它的處理過程更復雜,資料首先寫到記憶體中的一個緩衝區,並做一些預排序,以提升效率;
- 每個MapTask都有一個用來寫入輸出資料的迴圈記憶體緩衝區(預設大小為100MB),當緩衝區中的資料量達到一個特定閾值時(預設是80%)系統將會啟動一個後臺執行緒把緩衝區中的內容寫到磁碟(即spill階段)。在寫磁碟過程中,Map輸出繼續被寫到緩衝區,但如果在此期間緩衝區被填滿,那麼Map就會阻塞直到寫磁碟過程完成;
- 在寫磁碟前,執行緒首先根據資料最終要傳遞到的Reducer把資料劃分成相應的分割槽(partition)。在每個分割槽中,後臺執行緒按Key進行排序(快速排序),如果有一個Combiner(即Mini Reducer)便會在排序後的輸出上執行;
- 一旦記憶體緩衝區達到溢位寫的閾值,就會建立一個溢位寫檔案,因此在MapTask完成其最後一個輸出記錄後,便會有多個溢位寫檔案。在在MapTask完成前,溢位寫檔案被合併成一個索引檔案和資料檔案(多路歸併排序)(Sort階段);
- 溢位寫檔案歸併完畢後,Map將刪除所有的臨時溢位寫檔案,並告知TaskTracker任務已完成,只要其中一個MapTask完成,ReduceTask就開始複製它的輸出(Copy階段);
- Map的輸出檔案放置在執行MapTask的TaskTracker的本地磁碟上,它是執行ReduceTask的TaskTracker所需要的輸入資料,但是Reduce輸出不是這樣的,它一般寫到HDFS中(Reduce階段)。
2. Reduce端的Shuffle
- Copy階段:Reduce程序啟動一些資料copy執行緒,通過HTTP方式請求MapTask所在的TaskTracker以獲取輸出檔案。
- Merge階段:將Map端複製過來的資料先放入記憶體緩衝區中,Merge有3種形式,分別是記憶體到記憶體,記憶體到磁碟,磁碟到磁碟。預設情況下第一種形式不啟用,第二種Merge方式一直在執行(spill階段)直到結束,然後啟用第三種磁碟到磁碟的Merge方式生成最終的檔案。
- Reduce階段:最終檔案可能存在於磁碟,也可能存在於記憶體中,但是預設情況下是位於磁碟中的。當Reduce的輸入檔案已定,整個Shuffle就結束了,然後就是Reduce執行,把結果放到HDFS中。
五. 其它
HDFS和MapReduce是Hadoop的基礎架構。除了上述講解之外,還有MapReduce容錯機制,任務JVM重用,作業排程器等都還沒有總結。徹底理解了MapReduce的工作原理之後就可以大量的MapReduce程式設計了,計劃將Hadoop自帶例項看完後,再研讀《Mahout實戰》,同步學習《Hadoop技術內幕:深入解析YARN架構設計與實現原理》,正式邁入Hadoop 2.x版本的大門。
參考文獻:
[1] 《Hadoop權威指南》(第二版)
[2] 《Hadoop應用開發技術詳解》
[3] Hadoop 0.18文件:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html
[4] WordCount原始碼剖析:http://blog.csdn.net/recommender_system/article/details/42029311
[5] 外部排序技術之多路歸併排序:http://blog.chinaunix.net/uid-25324849-id-2182916.html