
hbase 讀寫過程
HBase中的每張表都通過行鍵按照一定的範圍被分割成多個子表(HRegion),預設一個HRegion超過256M就要被分割成兩個,由HRegionServer管理,管理哪些HRegion由HMaster分配。
HRegionServer存取一個子表時,會建立一個HRegion物件,然後對表的每個列族(Column Family)建立一個Store例項,每個Store都會有0個或多個StoreFile與之對應,每個StoreFile都會對應一個HFile, HFile就是實際的儲存檔案。因此,一個HRegion有多少個列族就有多少個Store。另外,每個HRegion還擁有一個MemStore例項
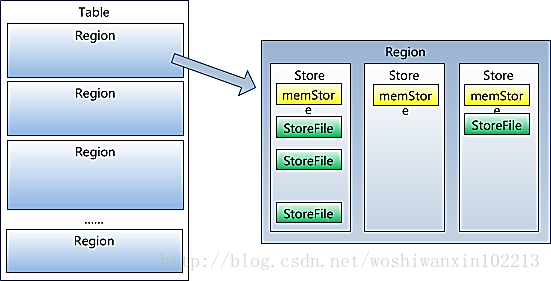
Region雖然是分散式儲存的最小單元,但並不是儲存的最小單元。Region由一個或者多個Store組成,每個store儲存一個columns family;每個Store又由一個memStore和0至多個StoreFile組成,StoreFile包含HFile;memStore儲存在記憶體中,StoreFile儲存在HDFS上。
HBase是基於BigTable的面向列的分散式儲存系統,其儲存設計是基於Memtable / SSTable設計的,主要分為兩部分,一部分為記憶體中的MemStore (Memtable),另外一部分為磁碟(這裡是HDFS)上的HFile (SSTable)。還有就是儲存WAL的log,主要實現類為HLog.
本質上MemStore就是一個記憶體裡放著一個儲存KEY/VALUE的MAP,當MemStore(預設64MB)寫滿之後,會開始刷磁碟操作。
HBase儲存在HDFS上的主要包含兩種檔案型別: 1. HFile, HBase中KeyValue資料的儲存格式,HFile是Hadoop的二進位制格式檔案,實際上StoreFile就是對HFile做了輕量級包裝,即StoreFile底層就是HFile 2. HLog File,HBase中WAL(Write Ahead Log) 的儲存格式,物理上是Hadoop的Sequence FileHFile結構:

Data Block:儲存表中的資料,這部分可以被壓縮
Meta Block:(可選)儲存使用者自定義的kv對,可以被壓縮。
File Info :Hfile的meta元資訊,不被壓縮,定長。
Data Block Index :Data Block的索引。每個Data塊的起始點。
Meta Block Index:(可選的)Meta Block的索引,Meta塊的起始點。
Trailer: 定長。儲存了每一段的偏移量,讀取一個HFile時,會首先讀取Trailer,Trailer有指標指向其他資料塊的起始點,儲存了每個段的起始位置(段的Magic Number用來做安全check),然後,DataBlock Index會被讀取到記憶體中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從記憶體中找到key所在的block,通過一次磁碟io將整個block讀取到記憶體中,再找到需要的key。DataBlock Index採用LRU機制淘汰。
HFile的Data Block,Meta Block通常採用壓縮方式儲存。Data Block是HBase I/O的基本單元,為了提高效率,HRegionServer中有基於LRU的Block Cache機制。每個Data塊的大小可以在建立一個Table的時候通過引數指定,大號的Block有利於順序Scan,小號Block利於隨機查詢。每個Data塊除了開頭的Magic以外就是一個個KeyValue對拼接而成, Magic內容就是一些隨機數字,目的是防止資料損壞。
HFile中的Key-Value結構
HFile中的每個Key-Value對就是一個簡單的byte陣列。但這個byte陣列包含了很多項資訊,並含有固定的結構。(有點類似資料流)

開始是兩個長度固定的數值,分別表示Key的長度和Value的長度。緊接著是Key,開始是固定長度的數值,表示RowKey的長度,緊接著是RowKey,然後是固定長度的數值,表示Family的長度,然後是Family(列族),接著是Qualifier(小列),然後是兩個固定長度的數值,表示Time Stamp和Key Type(Put/Delete)。Value部分則相對簡單,是純粹的二進位制資料。
HBase 為每個值維護了多級索引,即:<key, column family, column name(qualifer), timestamp>
Hbase寫資料流程
a) Client發起了一個HTable.put(Put)請求給HRegionServer
b) HRegionServer會將請求匹配到某個具體的HRegion上面
c) 決定是否寫WAL log。WAL log檔案是一個標準的Hadoop SequenceFile,檔案中儲存了HLogKey,這些Keys包含了和實際資料對應的序列號,主要用於崩潰恢復。
d) Put資料儲存到MemStore中,同時檢查MemStore狀態,如果滿了,則觸發Flush to Disk請求。
e) HRegionServer處理Flush to Disk的請求,將資料寫成HFile檔案並存到HDFS上,並且儲存最後寫入的資料序列號,這樣就可以知道哪些資料已經存入了永久儲存的HDFS中。
由於不同的列族會共享region,所以有可能出現,一個列族已經有1000萬行,而另外一個才100行。當一個要求region分割的時候,會導致100行的列會同樣分佈到多個region中。所以,一般建議不要設定多個列族。
相關推薦
Hbase讀寫過程
和寫流程相比,HBase讀資料是一個更加複雜的操作流程,這主要基於兩個方面的原因:其一是因為整個HBase儲存引擎基於LSM-Like樹實現,因此一次範圍查詢可能會涉及多個分片、多塊快取甚至多個數據儲存檔案;其二是因為HBase中更新操作以及刪除操作實現都很簡單,更新操作並沒有更新
hbase學習教程(二):HBase容錯性和Hbase使用場景、Hbase讀寫過程詳解
HBase容錯性 Write-Ahead-Log(WAL) 該機制用於資料的容錯和恢復: 每個HRegionServer中都有一個HLog物件,HLog是一個實現Write Ahead Log的類,在每次使用者操作寫入MemStore的同時,也會寫一份
hbase 讀寫過程
HBase中的每張表都通過行鍵按照一定的範圍被分割成多個子表(HRegion),預設一個HRegion超過256M就要被分割成兩個,由HRegionServer管理,管理哪些HRegion由HMaster分配。 HRegionServer存取一個子表時,會建立一個HRegion物件,然後對表的每個列
HBASE系統架構圖以及各部分的功能作用,物理儲存,HBASE定址機制,讀寫過程,Region管理,Master工作機制
1.1 hbase內部原理 1.1.1 系統架構 Client 1 包含訪問hbase的介面,client維護著一些cache來加快對hbase的訪問,比如regione的位置資訊。 Zookeeper 1 保證任何時候,叢集中只有一個master&
Hbase結構和讀寫過程
1、Hbase寫如過程圖(圖片來源於網路) 2、Hbase的結構 Master:HBase Master用於協調多個Region Server,偵測各個RegionServer之間的狀態,並平衡RegionServer之間的負載,並且分配Region給RegionS
ceph學習筆記之六 數據讀寫過程
ceph sds 數據寫過程1、Client向PG所在的主OSD發送寫請求。2、主OSD接收到寫請求,同時向兩個從OSD發送寫副本的請求,並同時寫入主OSD的本地存儲中。3、主OSD接收到兩個從OSD發送寫成功的ACK應答,同時確認自己寫成功,就向客戶端返回寫成功的ACK應答。4、在寫操作的過程中,主
hbase讀寫流程
ems 服務 region flush 以及 hba 表數據 new 剛才 HBase讀數據流程 1) HRegionServer保存著meta表以及表數據,要訪問表數據,首先Client先去訪問zookeeper,從zookeeper裏面獲取meta表所在的位置信息,即找
關於HBase讀寫數據的方法
cep tin return ces n) .get eof tab exceptio 目前我這邊有兩種方案讀寫HBase數據 1.將對象直接序列化然後存儲到HBase;2.將對象利用反射,一個Field對應一個列進行存儲 第一種方法 private Connection
MapReduce程式的讀寫過程
問題導讀1、HDFS框架組成是什麼?2、HDFS檔案的讀寫過程是什麼?3、MapReduce框架組成是什麼?4、MapReduce工作原理是什麼?5、什麼是Shuffle階段和Sort階段?
Hbase讀寫流程和定址機制
寫操作流程 (1) Client通過Zookeeper的排程,向RegionServer發出寫資料請求,在Region中寫資料。 (2) 資料被寫入Region的MemStore,直到MemStore達到預設閾值。 (3) MemStore中的資料被Flush成一個StoreFile。 (4) 隨著S
hbase讀寫原理(2)
HBase的原理 7.1體系圖 7.2寫流程 客戶端向HregionServer傳送請求 HregionServer將資料寫到hlog(提前寫入日誌)。為了資料的持久化和恢復 HregionServer將資料寫到記憶體(memstore)
HDFS資料的讀寫過程
1.資料讀取過程 一般的檔案讀取操作包括:open 、read、close等 客戶端讀取資料過程,其中1、3、6步由客戶端發起: 客戶端首先獲取FileSystem的一個例項,這裡就是HDFS對應的例項: ①客戶端呼叫FileSystem例項的open方法,獲得這個
hbase 讀寫資料流程----文字簡介
hbase讀取資料流程 0、client發出請求 1、訪問zk 2、zookeeper返回-ROOT-表所在的資訊,返回的是位置資訊 -ROOT-表中儲存了.META表的元資料資訊 .META表儲存了Region的元資料 -ROOT-:只對應一個region,不能切分,通過-ROOT-表可以
HDFS資料儲存與讀寫過程
InnoDB是在MySQL儲存引擎中第一個完整支援ACID事務的引擎,該引擎之前由Innobase oy公司所開發,後來該公司被Oracle收購。InnoDB是MySQL資料庫中使用最廣泛的儲存引擎,已被許多大型公司所採用如Google、Facebook、YouTube等,如
Ceph中糾刪碼的讀寫過程與快取分層
之前一直在關注Ceph讀寫過程與修復,現將之前看到的內容記錄下來。歡迎探討。 讀寫過程 上圖大體可以表示從檔案到儲存在儲存實體上的過程,詳細步驟如下: 1. RADOS中需要配置Object Size的值,也就是每個Object大小的最大值,一般情況下會設
HBase-讀寫流程及JavaAPI
1、讀寫流程 1.1、HBase 讀資料流程 1) HRegionServer 儲存著 meta 表以及表資料,要訪問表資料,首先 Client 先去訪問 zookeeper,從 zookeeper 裡面獲取 meta 表所在的位置資訊,即找到這個 meta 表在哪個 HRegionServ
從核心檔案系統看檔案讀寫過程
回到頂部系統呼叫作業系統的主要功能是為管理硬體資源和為應用程式開發人員提供良好的環境,但是計算機系統的各種硬體資源是有限的,因此為了保證每一個程序都能安全的執行。處理器設有兩種模式:“使用者模式”與“核心模式”。一些容易發生安全問題的操作都被限制在只有核心模式下才可以執行,例
hbase讀寫效能測試調優_初稿
Hbase讀寫效能測試調優 日期 版本 修訂 審批 修訂說明 2016.9.23 1.0 章鑫 初始版本 1 前言 本篇文章主要講的是hbase讀寫效能調優過程中遇到的一些技巧和配置項的修改,對於hbase本身的原
linux0.11字元裝置的讀寫過程分析
首先要知道linux系統/dev目錄下的各種裝置檔案(檔案屬性c打頭)並不佔用空間,你可以發現他們的大小為0位元組,他們的區別在於檔案的i節點的成員i_zone[0]的值不同,該值標識不同的裝置號。比如tty0檔案的裝置號為0x0400,tty1裝置號為0x0401,hd0
Hadoop之HDFS檔案讀寫過程
4.DFSOutputStream將資料分成塊,寫入data queue。data queue由Data Streamer讀取,並通知元資料節點分配資料節點,用來儲存資料塊(每塊預設複製3塊)。分配的資料節點放在一個pipeline裡。Data Streamer將資料塊寫入pipeline中的第