
搜尋解決方案——ElasticSearch入門
一、基本簡介——來自百度百科
ElasticSearch是一個基於Lucene的搜尋伺服器。它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。Elasticsearch是用Java開發的,並作為Apache許可條款下的開放原始碼釋出,是當前流行的企業級搜尋引擎。設計用於雲端計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用方便。
ElasticSearch是一個基於Lucene的高擴充套件的分散式搜尋伺服器,支援開箱即用。
ElasticSearch隱藏了Lucene的複雜性,對外提供Restful介面來操作索引、搜尋。
優點:
1、擴充套件性好,可部署上百臺伺服器叢集,可以處理PB級資料;
2、近實時的去索引數、搜尋資料。
es和solr的選擇問題?
如果是一個新的全文檢索專案的開發,建議優先考慮ElasticSearch。
二、原理與應用
2.1 索引結構
下圖是ElasticSearch的索引結構,上面部分是邏輯結構,下邊部分是物理結構,邏輯結構是為了更好的去描述ElasticSearch的工作原理及去使用物理結構中的索引檔案。

邏輯結構部分是一個倒排索引表
- 將要搜尋的文件內容分詞,所有不重複的片語成分詞列表;
- 分詞的結果會根據分詞器使用的不同而有所不同——常用中文分詞器:IK分詞器
- 將搜尋的文件最終以Document方式儲存起來;
- 每個詞和document都有關聯。
- 如下:

- 現在如果我們想搜尋quick brown,我們只需要查詢包含每個詞條的文件:

- 兩個文件都匹配,但是第一個文件比第二個匹配度更高,如果我們使用僅計算匹配詞條數量的簡單性演算法,那麼對於我們查詢的相關性來講,第一個文件比第二個文件更佳。
- 關於倒排索引
- 我們傳統的搜尋是通過文件去裡面找詞,稱為正排索引
- 現在的搜尋是通過詞來搜尋對應的文章
- 我們傳統的搜尋是通過文件去裡面找詞,稱為正排索引
2.2 Restful引用方法
Elasticsearch提供 RESTful Api介面進行索引、搜尋,並且支援多種客戶端。
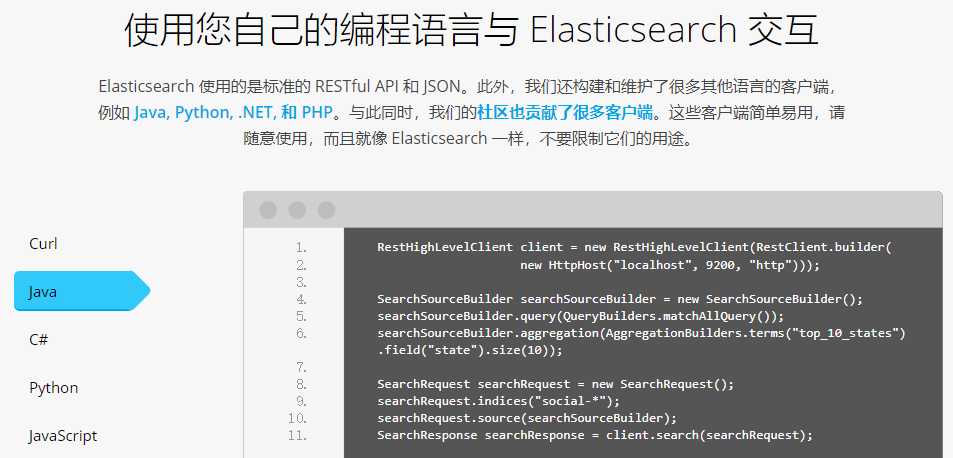
在專案中我們一般的應用方式:
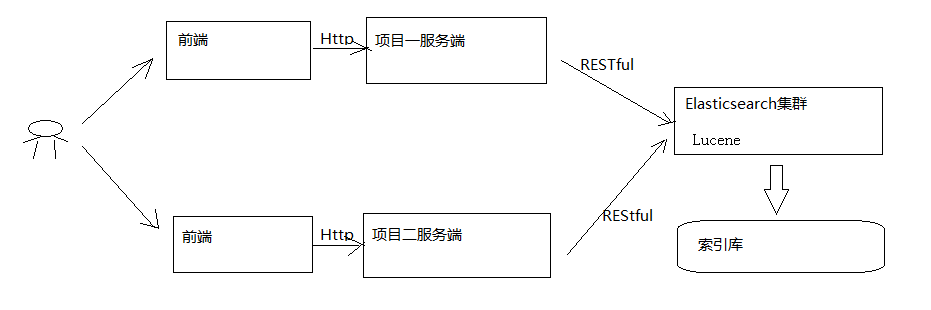
前端是可以直接通過訪問ElasticSearch進行訪問的,建立服務工程主要是為了對搜尋進行一些個性化設定以及一些安全設定。
- 使用者在前端搜尋關鍵字
- 專案前端通過http方式請求專案服務端
- 專案服務端通過Http Restful方式請求ES叢集進行搜尋
- ES叢集從索引庫檢索資料
三、ElasticSearch安裝
ElasticSearch支援多種安裝方式,在Windows下建議使用ZIP方式安裝,需注意與JDK的版本對應。
本次案例使用ElasticSearch-6.2.1.zip,需要jdk1.8及以上,解壓即可使用,目錄結構如下:

3.1 配置檔案
ES中主要的有三個配置檔案,配置檔案的位置在config目錄下:

elasticsearch.yml:要注意語法:(空格)name:(空格)value,編碼使用UTF-8
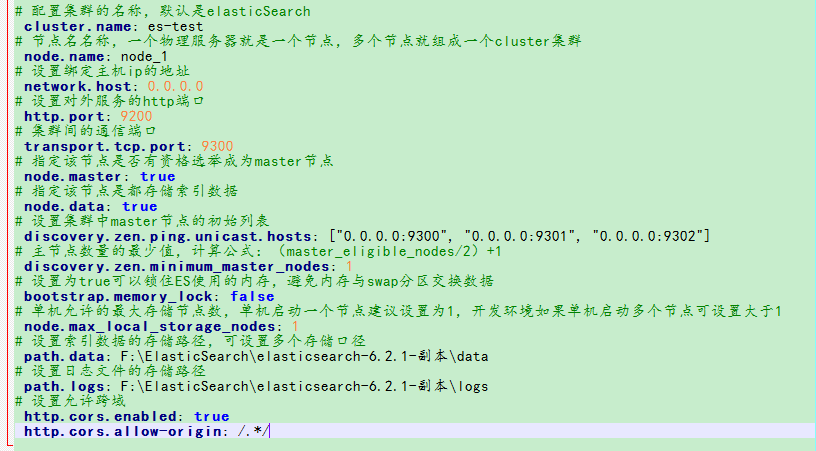
jvm.options:設定最小及最大的JVM堆記憶體大小,主要設定兩個引數-Xms和Xmx,注意如下:
- 兩個值設定為相等
- 將X夢想設定為不超過實體記憶體的一半
log4j2.properties:日誌檔案設定,ES使用log4j,注意日誌級別的配置
3.2 啟動ES
進入bin目錄,在cmd下執行:elasticsearch.bat,shift+滑鼠右鍵——》在此處開啟命令視窗
注:如果啟動失敗,注意檢查elasticsearch.yml中的語法問題
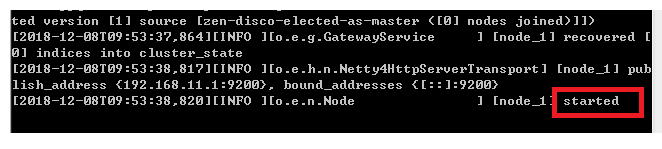
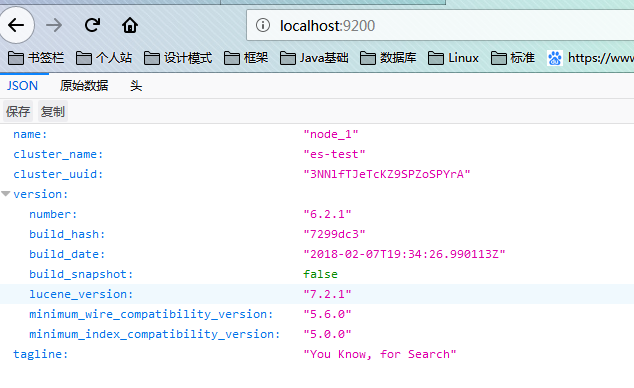
瀏覽器輸入:http://localhost:9200,顯示結果如下說明ES啟動成功,Firefox對json資料顯示友好
3.3 head外掛安裝
head外掛是ES的一個視覺化管理外掛,用來監視ES的狀態,並通過head客戶端與ES服務進行互動,比如建立對映,建立索引等,head的專案地址在https://github.com/mobz/elasticsearch-head
從ES6.0開始,head外掛支援使得node.js執行,所以安裝head外掛先安裝node.js
- 安裝node.js
- 安裝head外掛
- git clone git://github.com/mobz/elasticsearch-head.git
- cd elasticsearch-head
- npm install
- npm run start
命令需要在heade外掛的目錄執行,看到如下則表示執行成功
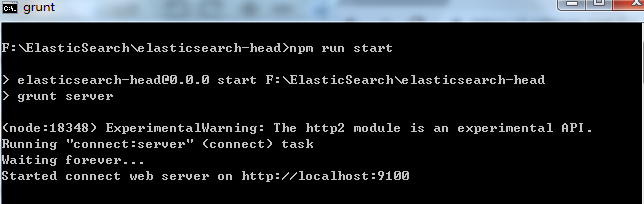
瀏覽器訪問:http://localhost:9100,如下圖表示成功連上es

四、ES快速入門
ES作為一個索引及搜搜服務,對外提供豐富的REST介面,下面的快速入門使用head外掛來測試,進行一個簡單的瞭解。
4.1 建立索引庫
ES的索引庫是一個邏輯概念,它包括了分詞列表以及文件列表,同一個額索引庫中儲存了相同型別的文件,他就相當於MySQL中的表或者Mongodb中的集合。
索引:
索引(名詞):ES是一個基於Lucene構建的一個搜尋服務,他要從索引庫搜尋服務條件索引資料。
索引(動詞):索引庫港建起來的時候是空的,需要將資料新增到索引庫的過程稱為索引。
下面介紹兩種建立索引庫的方法,它們的公子哥原來都是一樣的,通過客戶端向ES服務發哦送命令。
- 使用postman或者curl這樣的工具建立,put:http://localhost:9200/索引庫名稱:
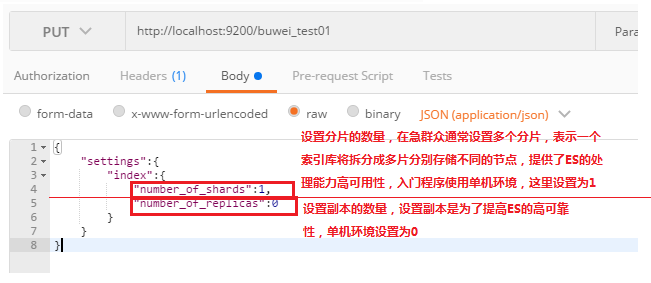

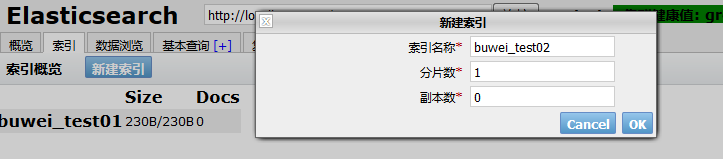
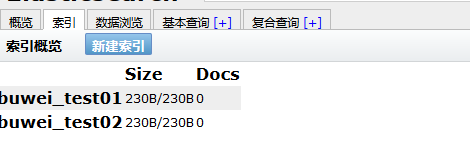
如上建立一個buwei-test01索引庫,一個分片,0個副本重新整理head的介面:
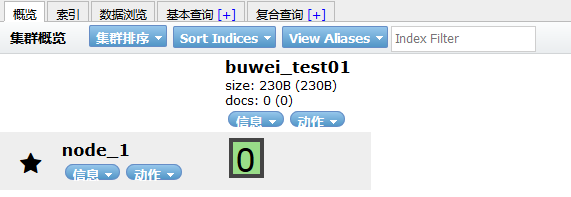
- 使用head外掛建立,在索引選單下,新建索引,填寫基本資訊,確認:
4.2 建立對映
1.概念
在索引庫中每個文件都包含一個或多個field,建立對映就是想索引庫中建立Field的過程,下面是document和Field與關係資料庫的類比:
文件(document)---------------------------row記錄
欄位(Field)----------------------------------columns列
關於索引庫的域關係型資料庫的類比
- 如果類比於資料庫的話就表示一個索引庫可以建立很多不同型別個的文件,在ES中允許這樣
- 如果類比於表就表示一個索引庫只能儲存相同型別的文件,ES官方建議在一個索引庫中之儲存相同型別的文件。
2.建立對映
我們要把被檢索的資訊儲存到ES中,需要建立資訊的對映,先做一個簡單的對映,如下:
傳送:post:http:localhost:9200/索引庫名稱/型別名稱/_mapping
建立索引庫buwei_test01的對映,包括三個欄位:name、description、studymondel
由於ES6.0版本還沒有將type徹底刪除,這裡將type設定為一個沒有意義的名字
post請求:http://localhost:9200/buwei_test01/doc/_mapping
1 { 2 "properties":{ 3 "name":{ 4 "type":"text" 5 }, 6 "description":{ 7 "type":"text" 8 }, 9 "studymodel":{ 10 "type":"keyword" 11 } 12 } 13 }
對映建立成功,檢視head介面:
3.建立文件
ES中的文件相當於MySQL資料庫表中的記錄
傳送:put或post:http://localhost:9200/buwei_test01/doc/id值(如果不指定idES會自動生成id)
http://localhost:9200/buwei_test01/doc/001
1 { 2 "name":"測試文件", 3 "description":"這是一個測試的文件", 4 "studymodel":"201801" 5 }
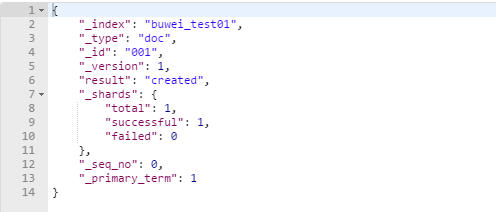
通過head查詢資料

4.搜尋文件
- 根據課程id查詢文件
- 傳送get:http://localhost:9200/buwei_test01/001
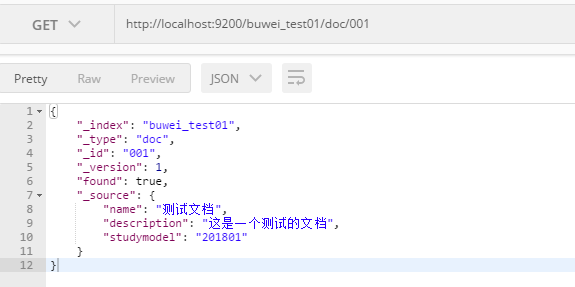
- 查詢所有記錄:傳送get:http://localhost:9200/buwei_test01/_search
- 查詢名稱中包括文的關鍵字:傳送get:http://localhost:9200/buwei_test01/_search?q:name:測試文件
5.搜尋結果分析

五、IK分詞器
5.1 測試分詞器
在新增文件時會進行分詞,索引中存放的就是一個一個的詞(term),當你去搜索時就是拿關鍵字去匹配詞,最終找到詞關聯的文件。
測試當前索引庫使用的分詞器:post:http://localhost:9200/_analyze
1 { 2 "text":"測試文件" 3 }
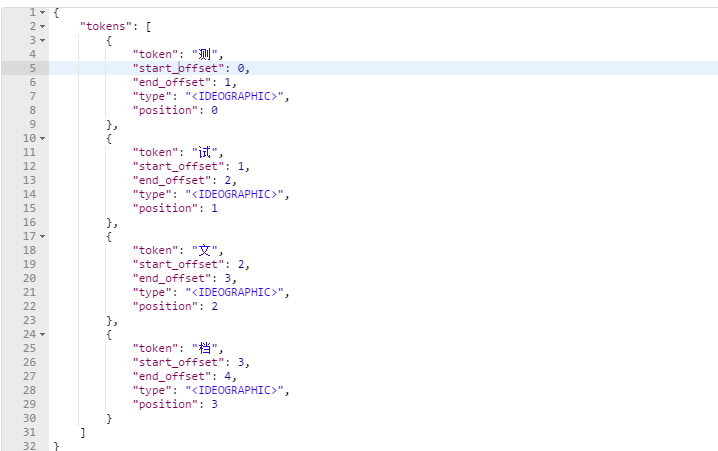
發現分詞的效果是將"測試文件"這個詞拆分成四個字,這是因為當前索引庫使用的分詞器是對中文單字分詞。
5.2 安裝IK分詞器
使用IK分詞器可以實現歲中文分詞的效果
下載IK分詞器:https://github.com/medcl/elasticsearch-analysis-ik,要找到對應版本
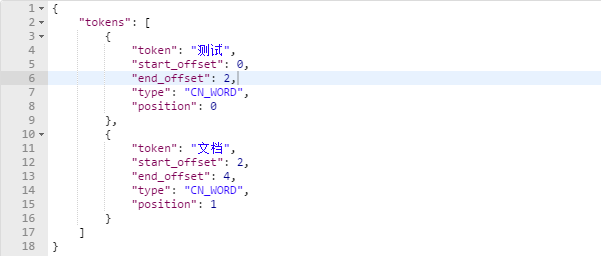
將下載後的檔案解壓後拷貝到ES安裝目錄的plugins下,,修改目錄名為ik,重啟elasticsearch。bat,再次請求資料
1 { 2 "text":"測試文件", 3 "analyzer":"ik_max_word" 4 }
5.3 兩種分詞模式
ik分詞器由兩種分詞模式:ik_max_word和ik_samrt模式
- ik_max_word:會將文字做最細力度的拆分,比如會將"中華人民共和國"拆分如下:

- ik_smart:會做最粗粒度的拆分,同樣是"中華人名共和國",拆分情況如下:

5.4 自定義詞庫
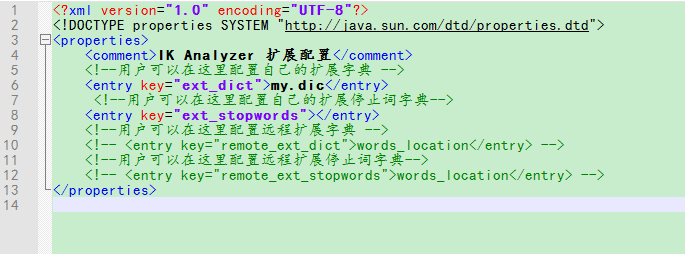
如果要讓分詞器支援一些專有詞語,可以自定義詞庫。
在ik分詞器的config目錄下自帶一個main.dic的檔案,就是詞庫檔案,可以在同級目錄中建立一個my.dic檔案(需為UTF-8格式)。在ik分詞器的配置檔案IKAnalyzer.cfg.xml中配置my.dic。
六、對映
在上面,我們安裝了ik分詞器,這時候我們就需要設定在索引和搜尋時使用ik分詞器,同時制定其他型別的Field,比如日期型別,數值型別等。
6.1 對映的維護方法
- 查詢所有索引的對映:get:http://localhost:9200/_mapping
- 建立對映:post:http:localhost:9200/buwei_test01/doc/_mapping——前面的案例中有講解
- 更新對映:對映建立成功可以新增新欄位,不允許更新已有欄位
- 刪除對映:通過刪除索引來刪除對映
6.2 常見對映型別
- text文字欄位
- type:定義屬性
- analyzer:定義分詞模式(ik_max_word/ik_smart)
- search_analyzer:定義搜尋是的分詞模式(ik_max_word/ik_smart)
- index:定義是否索引(true/false),只有進行索引的詞才可以從索引庫中搜索到,但是有些內容不需要被索引,比如圖片地址等
- store:是否在source之外儲存,每個文件索引後會在ES中儲存一份原始文件,存放在"_source"中,一般情況下設定為true,因為在"_source"中已經有一份原始文件了
- keyword關鍵字欄位
- 上邊介紹的text文字欄位在對映時需要設定分詞器,keyword欄位為關鍵字欄位,通常搜尋keyword欄位是按照整體搜尋的,索引建立keyword欄位的索引是不需要進行分詞的,比如手機號碼、郵政編碼等,keyword欄位通常用於過濾、排序、聚合等。
- date日期型別
- 日期型別不用設定分詞器,通常日期型別的欄位用於排序
- format:設定日期的格式
- "format": "yyyy‐MM‐dd HH:mm:ss||yyyy‐MM‐dd"
- 數值型別:long、integer、short、byte、double、float、half_float、scaled_float
- 需儘量選擇範圍小的型別,提高搜尋效率
七、索引管理
7.1 ES客戶端
ES提供多種不同的客戶端:
1、TransportClient
ES提供的傳統客戶端,官方計劃8.0版本刪除此客戶端
2、RestClient
RestClient是官方推薦使用的,它包括兩種:Java Low Level Rest Client和Java High Level Rest Client,不過當前前它還處於完善中,有些功能還沒有。
使用的時候引入相關的依賴即可。
1 <dependency> 2 <groupId>org.elasticsearch.client</groupId> 3 <artifactId>elasticsearch-rest-high-level-client</artifactId> 4 <version>6.2.1</version> 5 </dependency> 6 <dependency> 7 <groupId>org.elasticsearch</groupId> 8 <artifactId>elasticsearch</artifactId> 9 <version>6.2.1</version> 10 </dependency>
在Java中就是通過執行RestClient的相關api執行對elasticsearch的操作。