
乾貨 | Elasticsearch 叢集健康值紅色終極解決方案
題記
Elasticsearch當清理快取( echo 3 > /proc/sys/vm/drop_caches )的時候,出現
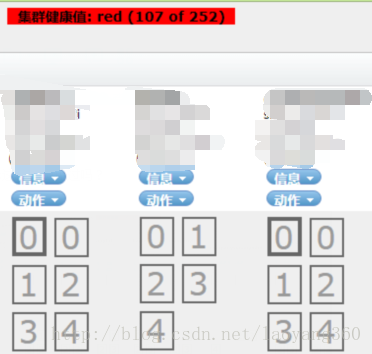
如下叢集健康值:red,紅色預警狀態,同時部分分片都成為灰色。
檢視Elasticsearch啟動日誌會發現如下:
叢集服務超時連線的情況。
bserver: timeout notification from cluster service. timeout setting [1m], time since start [1m]該問題排查耗時很長,問題已經解決。
特將問題排查及解決方案詳盡的整理出來。
1、叢集狀態解讀
head外掛會以不同的顏色顯示。
1)、綠色——最健康的狀態,代表所有的主分片和副本分片都可用;
2)、黃色——所有的主分片
3)、紅色——部分主分片不可用。(此時執行查詢部分資料仍然可以查到,遇到這種情況,還是趕快解決比較好。)
參考官網:http://t.cn/RltLEpN(部分中文叢集健康狀態博文資料翻譯的不夠精確,以官網為準)
如果叢集狀態為紅色, Head外掛顯示:叢集健康值red 。則說明:至少一個主分片分配失敗。
這將導致一些資料以及索引的某些部分不再可用。
儘管如此, ElasticSearch還是允許我們執行查詢,至於是通知使用者查詢結果可能不完整還是掛起查詢,則由應用構建者來決定。
2、什麼是unassigned 分片?
一句話解釋:未分配的分片。
啟動ES的時候,通過Head外掛不停重新整理,你會發現叢集分片會呈現紫色、灰色、最終綠色的狀態。
3、為什麼會出現 unassigned 分片?
如果不能分配分片,例如,您已經為叢集中的節點數過分分配了副本分片的數量,則分片將保持UNASSIGNED狀態。
其錯誤碼為:ALLOCATION_FAILED。
你可以通過如下指令,檢視叢集中不同節點、不同索引的狀態。
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason4、出現unassigned 分片後的症狀?
head外掛檢視會:Elasticsearch啟動N長時候後,某一個或幾個分片仍持續為灰色。
5、unassigned 分片問題可能的原因?
1)INDEX_CREATED:由於建立索引的API導致未分配。
2)CLUSTER_RECOVERED :由於完全叢集恢復導致未分配。
3)INDEX_REOPENED :由於開啟open或關閉close一個索引導致未分配。
4)DANGLING_INDEX_IMPORTED :由於匯入dangling索引的結果導致未分配。
5)NEW_INDEX_RESTORED :由於恢復到新索引導致未分配。
6)EXISTING_INDEX_RESTORED :由於恢復到已關閉的索引導致未分配。
7)REPLICA_ADDED:由於顯式新增副本分片導致未分配。
8)ALLOCATION_FAILED :由於分片分配失敗導致未分配。
9)NODE_LEFT :由於承載該分片的節點離開叢集導致未分配。
10)REINITIALIZED :由於當分片從開始移動到初始化時導致未分配(例如,使用影子shadow副本分片)。
11)REROUTE_CANCELLED :作為顯式取消重新路由命令的結果取消分配。
12)REALLOCATED_REPLICA :確定更好的副本位置被標定使用,導致現有的副本分配被取消,出現未分配。6、叢集狀態紅色如何排查?
症狀:叢集健康值紅色;
日誌:叢集服務連線超時;
可能原因:叢集中部分節點的主分片未分配。
接下來的解決方案主要圍繞:使主分片unsigned 分片完成再分配展開。
7、如何Fixed unassigned 分片問題?
方案一:極端情況——這個分片資料已經不可用,直接刪除該分片。
ES中沒有直接刪除分片的介面,除非整個節點資料已不再使用,刪除節點。
curl -XDELETE ‘localhost:9200/index_name/’
方案二:叢集中節點數量>=叢集中所有索引的最大副本數量 +1。
N> = R + 1
其中:
N——叢集中節點的數目;
R——叢集中所有索引的最大副本數目。
知識點:當節點加入和離開叢集時,主節點會自動重新分配分片,以確保分片的多個副本不會分配給同一個節點。換句話說,主節點不會將主分片分配給與其副本相同的節點,也不會將同一分片的兩個副本分配給同一個節點。
如果沒有足夠的節點相應地分配分片,則分片可能會處於未分配狀態。
由於我的叢集就一個節點,即N=1;所以R=0,才能滿足公式。
問題就轉嫁為:
1)新增節點處理,即N增大;
2)刪除副本分片,即R置為0。
R置為0的方式,可以通過如下命令列實現:
root@tyg:/# curl -XPUT "http://localhost:9200/_settings" -d' { "number_of_replicas" : 0 } '
{"acknowledged":true}方案三:allocate重新分配分片。
如果方案二仍然未解決,可以考慮重新分配分片。
可能的原因:
1)節點在重新啟動時可能遇到問題。正常情況下,當一個節點恢復與群集的連線時,它會將有關其分片的資訊轉發給主節點,然後主節點將這分片從“未分配”轉換為“已分配/已啟動”。
2)當由於某種原因(例如節點的儲存已被損壞)導致該程序失敗時,分片可能保持未分配狀態。
在這種情況下,您必須決定如何繼續:嘗試讓原始節點恢復並重新加入叢集(並且不要強制分配主分片);
或者強制使用Reroute API分配分片並重新索引缺少的資料原始資料來源或備份。
如果您決定分配未分配的主分片,請確保將“allow_primary”:“true”標誌新增到請求中。
ES5.X使用指令碼如下:
NODE="YOUR NODE NAME"
IFS=$'\n'
for line in $(curl -s 'localhost:9200/_cat/shards' | fgrep UNASSIGNED); do
INDEX=$(echo $line | (awk '{print $1}'))
SHARD=$(echo $line | (awk '{print $2}'))
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{
"commands": [
{
" allocate_replica ": {
"index": "'$INDEX'",
"shard": '$SHARD',
"node": "'$NODE'",
"allow_primary": true
}
}
]
}'
doneES2.X及早期版本,將 allocate_replica改為 allocate,其他不變。
指令碼解讀:
步驟1:定位 UNASSIGNED 的節點和分片
curl -s 'localhost:9200/_cat/shards' | fgrep UNASSIGNED步驟2:通過 allocate_replica 將 UNASSIGNED的分片重新分配。
8、核心知識點
1)路由
原理很簡單,把每個使用者的資料都索引到一個獨立分片中,在查詢時只查詢那個使用者的分片。這時就需要使用路由。
使用路由優勢:路由是優化叢集的一個很強大的機制。
它能讓我們根據應用程式的邏輯來部署文件, 從而可以用更少的資源構建更快速的查詢。
2)在索引過程中使用路由
我們可以通過路由來控制 ElasticSearch 將文件傳送到哪個分片。
路由引數值無關緊要,可以取任何值。重要的是在將不同文件放到同一個分片上時, 需要使用相同的值。
3)指定路由查詢
路由允許使用者構建更有效率的查詢,當我們只需要從索引的一個特定子集中獲取資料時, 為什麼非要把查詢傳送到所有的節點呢?
指定路由查詢舉例:
curl -XGET 'localhost:9200/documents/_search?pretty&q=*:*&routing=A'4)叢集再路由reroute
reroute命令允許顯式地執行包含特定命令的叢集重新路由分配。
例如,分片可以從一個節點移動到另一個節點,可以取消分配,或者可以在特定節點上顯式分配未分配的分片。
5)allocate分配原理
分配unassigned的分片到一個節點。
將未分配的分片分配給節點。接受索引和分片的索引名稱和分片號,以及將分片分配給它的節點。。
它還接受allow_primary標誌來明確指定允許顯式分配主分片(可能導致資料丟失)。
9、小結
1)該問題的排查累計超過6個小時,最終找到解決方案。之前幾近沒有思路,想放棄,但咬牙最終解決。
2) 切記,第一手資料很重要!
Elasticsearch出現問題,最高效的解決方案是第一手資料ES英文官網文件,其次是ES英文論壇、ES github issues,再次是stackoverflow等英文論壇、部落格。最後才是:Elasticsearch中文社群、其他相關中文技術部落格等。
因為:所有的論壇、部落格文字都是基於ES英文官方文件再整理,難免有缺失或錯誤。
3)自己的Elasticsearch基礎原理、Lucene基礎知識的不牢固,別無它法,繼續深入研究,繼續死磕中…….
參考
2018-05方法升級
elasticsearch出現unassigned shards根本原因?
medcl https://elasticsearch.cn/question/4136回覆:
原因肯定是有很多啊,但是要看具體每一次是什麼原因引起的,對照表格排查未免不太高效,怎麼辦?
es 早已幫你想好對策,使用 Cluster Allocation Explain API,會返回叢集為什麼不分配分片的詳細原因,你對照返回的結果,就可以進行有針對性的解決了。
實驗一把:
GET /_cluster/allocation/explain
{
"index": "test",
"shard": 0,
"primary": false,
"current_state": "unassigned",
"unassigned_info": {
"reason": "CLUSTER_RECOVERED",
"at": "2018-05-04T14:54:40.950Z",
"last_allocation_status": "no_attempt"
},
"can_allocate": "no",
"allocate_explanation": "cannot allocate because allocation is not permitted to any of the nodes",
"node_allocation_decisions": [
{
"node_id": "ikKuXkFvRc-qFCqG99smGg",
"node_name": "test",
"transport_address": "127.0.0.1:9300",
"node_decision": "no",
"deciders": [
{
"decider": "same_shard",
"decision": "NO",
"explanation": "the shard cannot be allocated to the same node on which a copy of the shard already exists [[test][0], node[ikKuXkFvRc-qFCqG99smGg], [P], s[STARTED], a[id=bAWZVbRdQXCDfewvAbN85Q]]"
}
]
}
]
}——————————————————————————————————
更多ES相關實戰乾貨經驗分享,請掃描下方【銘毅天下】微信公眾號二維碼關注。
(每週至少更新一篇!)

和你一起,死磕Elasticsearch!
——————————————————————————————————
2017年11月04日 13:28 於家中床前