
大話資料結構筆記_串
阿新 • • 發佈:2018-12-08
串的定義:
串(string)是由零個或者多個字元組成的有限序列, 又名叫字串。
串的比較: 字典序
串的ADT:
串的順序結構: 使用的是陣列的方式來儲存, 但是一般都會動態的對陣列的大小進行擴容。
串的鏈式儲存結構: 一個Node儲存多少長度的字元需要根據實際情況作出調整, 每個Node大小會直接影響到字串處理的效率。
鏈式儲存除了在連線字串的時候更加方便以外,整體上不如順序儲存靈活, 效能也不如順序儲存結構好。
一個Node儲存多少長度的字元需要根據實際情況作出調整, 每個Node大小會直接影響到字串處理的效率。
鏈式儲存除了在連線字串的時候更加方便以外,整體上不如順序儲存靈活, 效能也不如順序儲存結構好。
模式匹配演算法: BD 匹配 : 低效。 KMP: 不移動主串的 i , 僅僅針對失配位置,對模式串進行調整。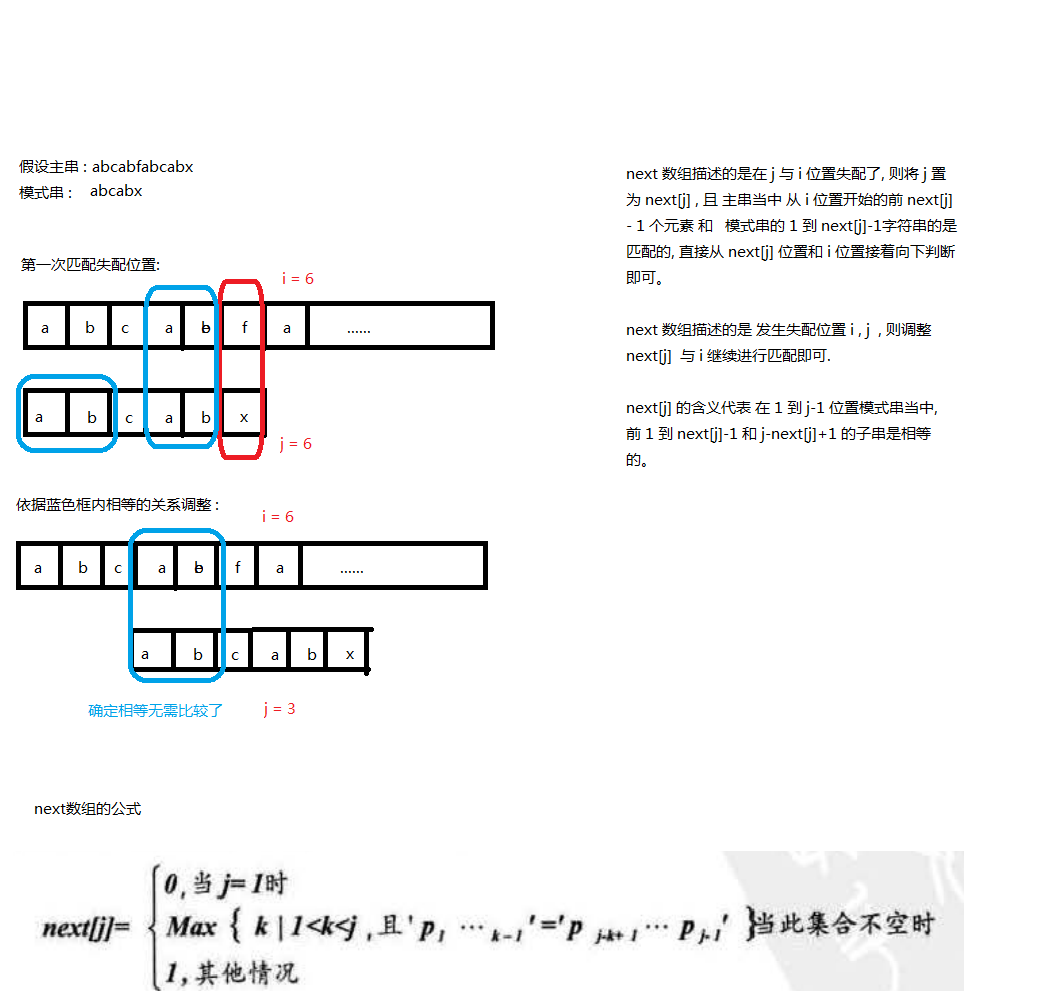 !!! 注意: 此圖是本書中使用的自定的串結構, 下標從1開始的 , 下方程式碼是使用C風格字串, 下標從0開始的, 因此上述next[j] 公式修改如下:
!!! 注意: 此圖是本書中使用的自定的串結構, 下標從1開始的 , 下方程式碼是使用C風格字串, 下標從0開始的, 因此上述next[j] 公式修改如下:
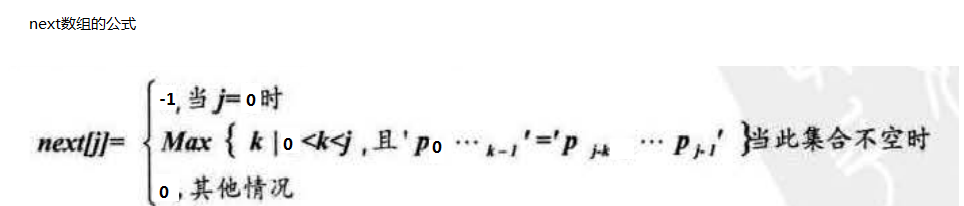
KMP 演算法程式碼實現: 以普通的C風格字串作為例子。
串的比較: 字典序
串的ADT:
串的順序結構: 使用的是陣列的方式來儲存, 但是一般都會動態的對陣列的大小進行擴容。
串的鏈式儲存結構:
一個Node儲存多少長度的字元需要根據實際情況作出調整, 每個Node大小會直接影響到字串處理的效率。
鏈式儲存除了在連線字串的時候更加方便以外,整體上不如順序儲存靈活, 效能也不如順序儲存結構好。
模式匹配演算法: BD 匹配 : 低效。 KMP: 不移動主串的 i , 僅僅針對失配位置,對模式串進行調整。
!!! 注意: 此圖是本書中使用的自定的串結構, 下標從1開始的 , 下方程式碼是使用C風格字串, 下標從0開始的, 因此上述next[j] 公式修改如下:
KMP 演算法程式碼實現: 以普通的C風格字串作為例子。

#include <stdio.h> #include <string.h> #include <stdlib.h> #define NDEBUG /*需要除錯資訊輸出請註釋此巨集*/ /*獲取next陣列*/ void get_next(const char *t, int *next) { int i,j; i = 0; j = -1; /*調整j為-1,代表主串從失配位置下一個位置 在 和模式串重頭開始匹配*/ next[0] = -1; int t_len = strlen(t); while(i < t_len) { if(-1 == j || t[i] == t[j]) { ++i; ++j; next[i] = j; }else{ j = next[j]; } } } /*匹配, 在main串中匹配pattern*/ int subString(const char *s, const char *t) { int i = 0; /*指向mian串字元位置的指標*/ int j = 0; /*指向pattern串字元位置的指標*/ int s_len = strlen(s); int t_len = strlen(t); int * next = (int *)malloc(sizeof(int) * (t_len)); get_next(t, next); while(i < s_len && j < t_len) { /*等於-1 說明將i+1的位置 和 模式串的0位置的字串在進行匹配就行了*/ if( -1 == j || s[i] == t[j]) { i++; j++; } else /*失配調整位置*/ { /*下方程式碼塊兒 輸出除錯資訊, 方便理解KMP演算法 , 可以刪除*/ { #ifndef NDEBUG int len = i - j; int k; printf("-------------------lose--------------------------\n"); printf(" i : %d -- j : %d \n", i, j); printf("%s\n", s); for(k = 0; k<i;++k) printf(" "); printf("^\n"); for(k = 0; k<len;++k) printf(" "); printf("%s\n", t); printf("--------------------------------------------------\n"); #endif } j = next[j] } } free(next); if(j >= t_len) return i - t_len; else return -1; } int main() { const char *t = "abcade"; const char *s = "abxabdabcade"; int result = subString(s, t); printf("%d\n",result); return 0; }KMP
KMP優化: 例子1: s : da a a a a a b c x a a a a a a a t : a a a a a a a next : -1 0 1 2 3 4 例子2: s:aabaabaabaaxaabaabaabaab s:aabaabaabaab 如上方的例子: 在 i = 5 且 j = 5 的位置發生了失配, 那麼 j 會調整到 j = 4 繼續 與 i = 5 匹配 又發生失配, j又 調整到 j = 3 一直調整到 j = 0 的時候-1標誌才會讓 i 加1, 進而完成一次 I的調整 。可見從 s[5] != t[5] 的那次失配的其, next調整到4, 3 , 2 , 1 完全是多餘的, 直接調整到 0 就行啦。 則 那麼求next陣列的演算法進行如下優化:
1 void get_next(const char *t, int *next) 2 { 3 int i,j; 4 i = 0; 5 j = -1; /*調整j為-1,代表主串從失配位置下一個位置 在 和模式串重頭開始匹配*/ 6 next[0] = -1; 7 int t_len = strlen(t); 8 9 while(i < t_len) 10 { 11 if(-1 == j || t[i] == t[j]) 12 { 13 ++i; 14 ++j; 15 /*i = 1 時候直接設定為0, 正好j的值為0*/ 16 /*否則判斷 next[i] 與 next[i - 1]就行了*/ 17 next[i] = ((i != 1 && str[i] == str[j]) ? next[j] : j); 18 } 19 }else{ 20 j = next[j]; /*失配, 則將 j 回溯,這麼寫是確保*/ 21 } 22 } 23 }getnext陣列的優化