
Scrapy中整合selenium
阿新 • • 發佈:2018-12-08
面對眾多動態網站比如說淘寶等,一般情況下用selenium最好
那麼如何整合selenium到scrapy中呢?
因為每一次request的請求都要經過中介軟體,所以寫在中介軟體中最為合適
from selenium import webdriver from scrapy.http import HtmlResponse class JSPageMiddleware(object): def process_request(self, request, spider): if spider.name == "xinlang": # 這只是一個示例表示爬蟲為新浪,當然可以自定義比如正則表示式對於某一種網址來進行過濾browser = webdriver.Chrome() browser.get(request.url) import time time.sleep(3) print("訪問:{0}".format(request.url)) # 如何在這裡傳送完成之後就不傳送給scrapy下載器了呢? return HtmlResponse(url=browser.current_url, body=browser.page_source, encoding="utf-8",request=request) # 一旦遇到HTMLResponse,scrapy就不會向download傳送了,而是直接返回給spider了,上面所有值都是必須的
注意別忘了 將中介軟體寫入到settings中!
是不是可以優化的空間了呢?
每一次請求都要開啟一次Chrome,這個就很煩了,因為速度比較慢
from selenium import webdriver from scrapy.http import HtmlResponse class JSPageMiddleware(object): def __init__(self): self.browser = webdriver.Chrome super().__init__() def process_request(self, request, spider): if spider.name == "xinlang": # 這只是一個示例表示爬蟲為新浪,當然可以自定義比如正則表示式對於某一種網址來進行過濾 self.browser.get(request.url) import time time.sleep(3) print("訪問:{0}".format(request.url)) # 如何在這裡傳送完成之後就不傳送給scrapy下載器了呢? return HtmlResponse(url=self.browser.current_url, body=self.browser.page_source, encoding="utf-8", request=request) # 一旦遇到HTMLResponse,scrapy就不會向download傳送了,而是直接返回給spider了,上面所有值都是必須的
這樣只需要開啟一次Chrome了,但是,注意下,這樣的話scrapy就不會關閉了,那怎麼辦?
我們把它放到spider中

那這樣的話,中介軟體中改為
from scrapy.http import HtmlResponse class JSPageMiddleware(object): def process_request(self, request, spider): if spider.name == "xinlang": spider.browser.get(request.url) # 利用spider來進行呼叫 import time time.sleep(3) print("訪問:{0}".format(request.url)) # 如何在這裡傳送完成之後就不傳送給scrapy下載器了呢? return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding="utf-8", request=request)
但是這樣還是有問題,我咋知道什麼時間關閉?
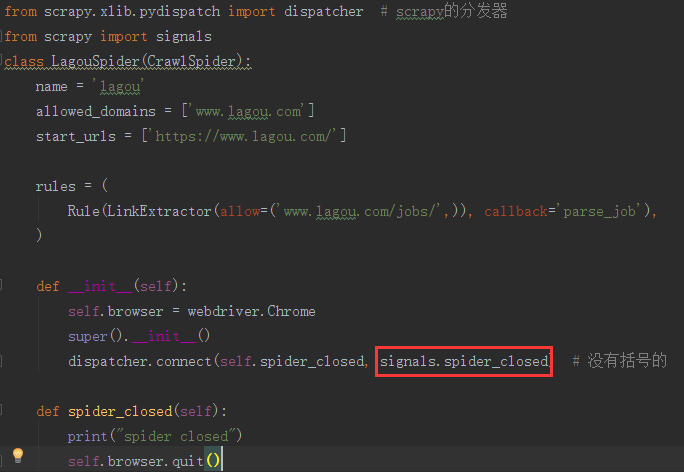
from selenium import webdriver from scrapy.xlib.pydispatch import dispatcher # scrapy的分發器 from scrapy import signals class LagouSpider(CrawlSpider): name = 'lagou' allowed_domains = ['www.lagou.com'] start_urls = ['https://www.lagou.com/'] rules = ( Rule(LinkExtractor(allow=('www.lagou.com/jobs/',)), callback='parse_job'), ) def __init__(self): self.browser = webdriver.Chrome super().__init__() dispatcher.connect(self.spider_closed, signals.spider_closed) # 沒有括號的 def spider_closed(self): print("spider closed") self.browser.quit()
是不是和django的用法非常一致?
但是非同步處理的時候,則麼辦,現在是一個同步的請求!
那麼重寫download
git 搜尋scrapy download一搜便知