
快速人體姿態估計--Pose Proposal Networks
Pose Proposal Networks ECCV2018
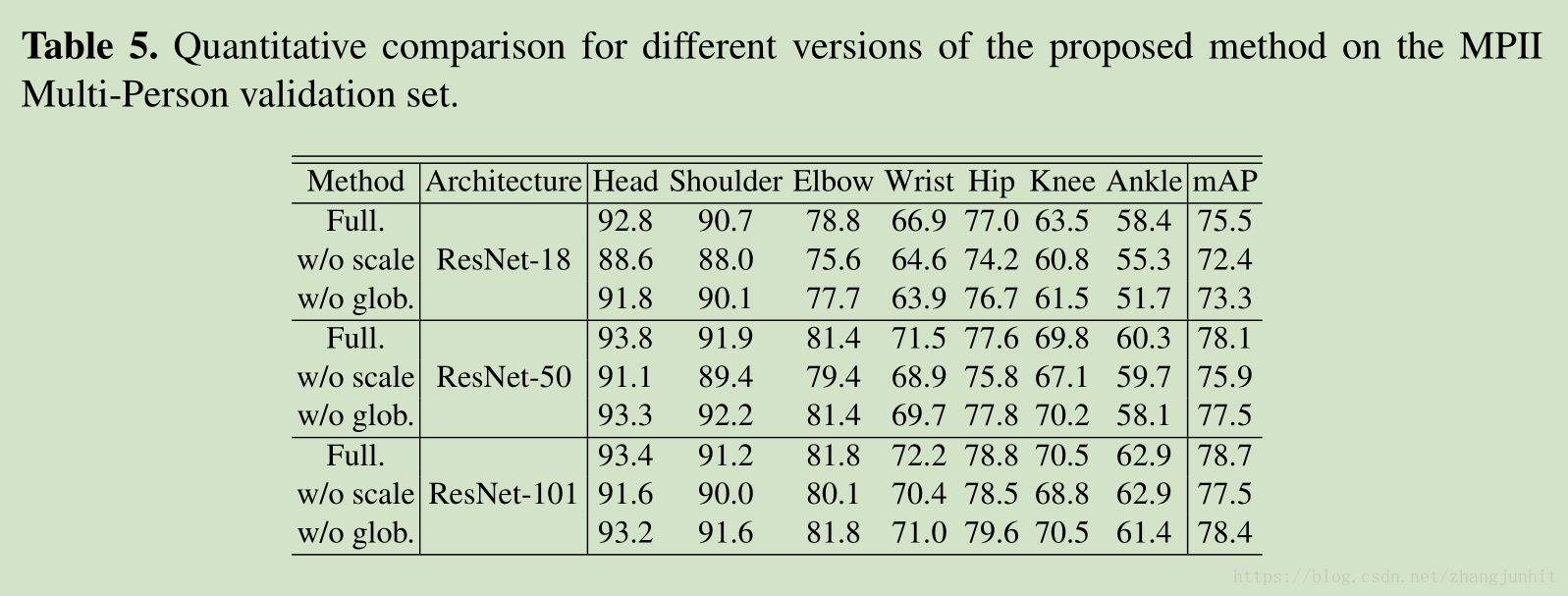
本文使用 YOLO + bottom-up greedy parsing 進行人體姿態估計
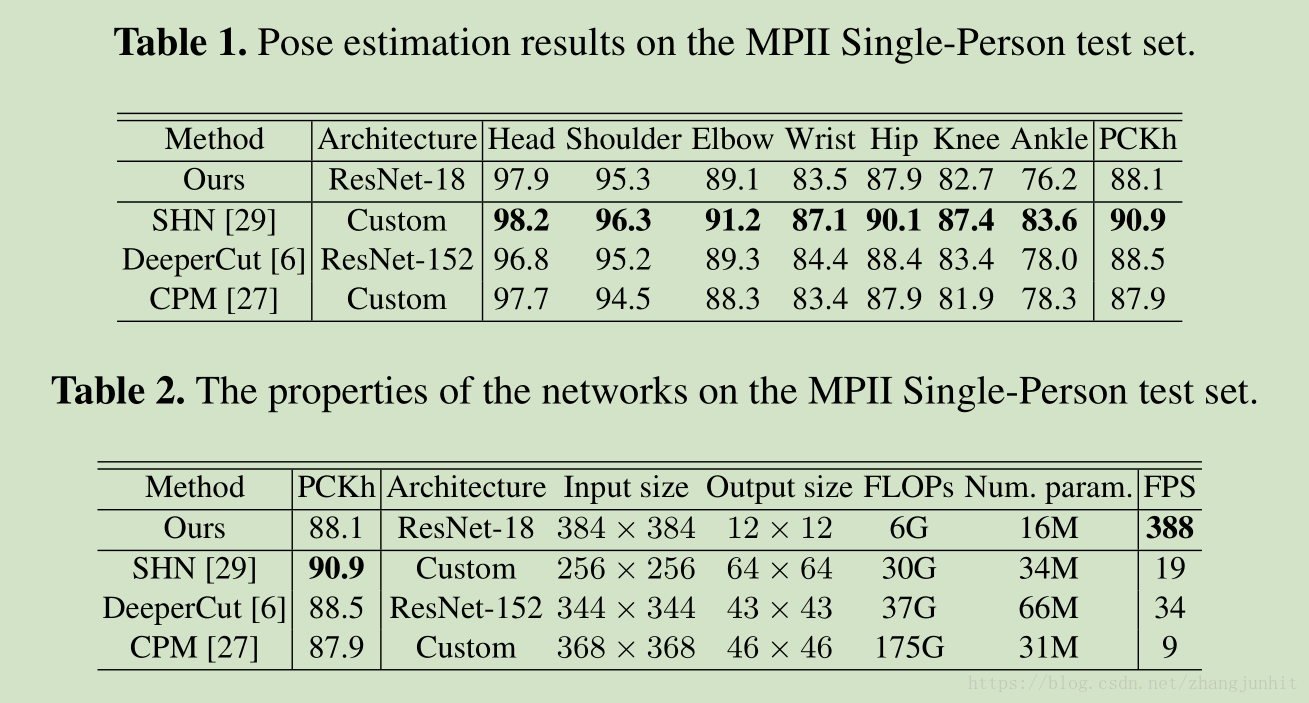
its total runtime using a GeForce GTX1080Ti card reaches up to 5.6 ms (180 FPS)

人體姿態估計總的來說有兩大類方法: top-down and bottom-up top-down: 就是首先檢測影象中的所有人,然後分別對每個人進行人體姿態估計 one detects person instances first and then applies single-person pose estimators to each detection
bottom-up:首先提取出影象中所有的人體部件 person parts,然後 對部件進行聚類,講屬於同一個人的部件連線起來。 detects parts first and then parses them into each person instance
從時間效率的角度來說, bottom-up 更具優勢,它的時間不會隨著影象人數的增加而線性增加

Human pose detection is achieved via the following steps. 1. Resize an input image to the input size of the CNN. 2. Run forward propagation of the CNN and obtain RPs of person instances and parts and limb detections. 3. Perform non-maximum suppression (NMS) for these RPs. 4. Parse the merged RPs into individual people and generate pose proposals.


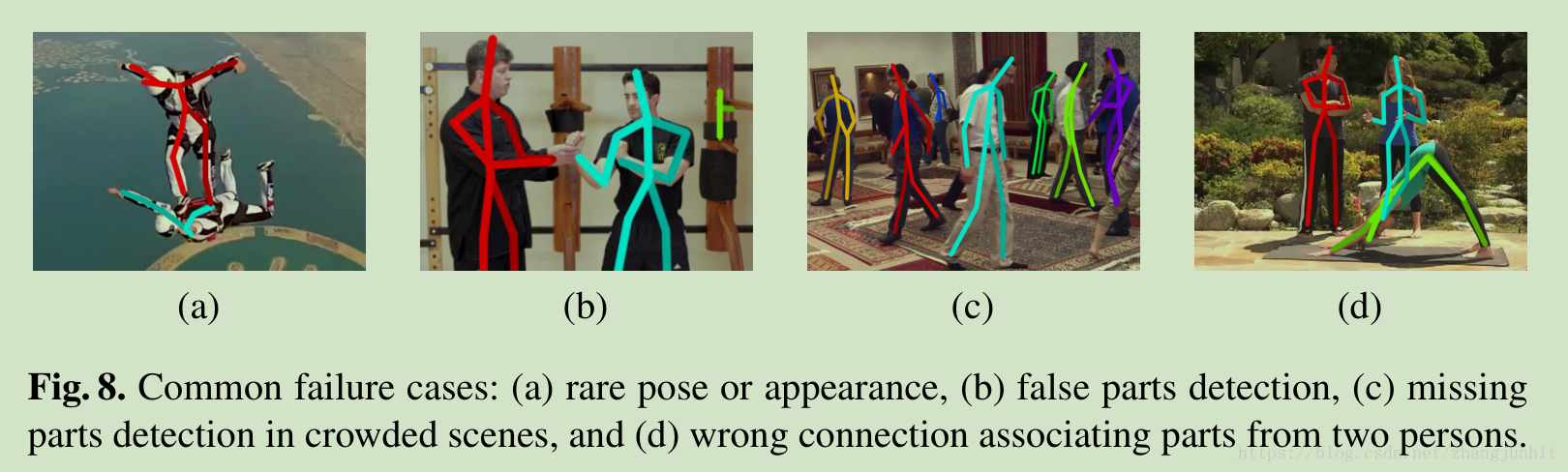
面對擁擠人群的姿態就力不從心了,網格檢測的弊端啊
11