
CDH 偽分散式環境搭建
安裝環境服務部署規劃
|
伺服器IP |
192.168.1.100 |
192.168.1.110 |
192.168.1.120 |
|
|
HDFS |
NameNode |
|||
|
Secondary NameNode |
||||
|
DataNode |
DataNode |
DataNode |
||
|
YARN |
ResourceManager |
|||
|
NodeManager |
NodeManager |
NodeManager |
||
|
MapReduce |
JobHistoryServer |
|||
注: 搭建過程需要考慮自己的環境目錄和文件中的目錄路徑是否相同 以及 主機域名是否和文件中的域名相同
一:上傳壓縮包解壓
將我們重新編譯之後支援snappy壓縮的hadoop包上傳到第一臺伺服器並解壓
第一臺機器執行以下命令
cd /export/softwares/
mv hadoop-2.6.0-cdh5.14.0-自己編譯後的版本.tar.gz hadoop-2.6.0-cdh5.14.0.tar.gz
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz -C ../servers/
二:檢視hadoop支援的壓縮方式以及本地庫
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hadoop checknative
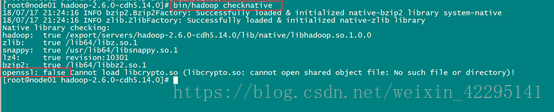
如果出現openssl為false,那麼所有機器線上安裝openssl即可,執行以下命令,虛擬機器聯網之後就可以線上進行安裝了
yum -y install openssl-devel
三:修改配置檔案
修改core-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.52.100:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas</value>
</property>
<!-- 緩衝區大小,實際工作中根據伺服器效能動態調整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 開啟hdfs的垃圾桶機制,刪除掉的資料可以從垃圾桶中回收,單位分鐘 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
修改hdfs-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<configuration>
<!-- NameNode儲存元資料資訊的路徑,實際工作中,一般先確定磁碟的掛載目錄,然後多個目錄用,進行分割 -->
<!-- 叢集動態上下線
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定義dataNode資料儲存的節點位置,實際工作中,一般先確定磁碟的掛載目錄,然後多個目錄用,進行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
修改hadoop-env.sh
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
注: 原檔案是 mapred-site.xml.template 可以先
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
修改yarn-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
修改slaves檔案
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim slaves
注: 一定要刪除原有檔案中的內容!!
刪除:
一定要改成自己的主機名, 且不要有其他多的空行
node01
node02
node03
四 :建立檔案存放目錄
node01機器上面建立以下目錄 [ 這些都建立在 hadoop-2.6.0-cdh5.14.0 目錄之下, 所以複製的時候其他機器就不用建立了 ]
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits
五:安裝包的分發
第一臺機器執行以下命令
cd /export/servers/
scp -r hadoop-2.6.0-cdh5.14.0/ node02:$PWD
scp -r hadoop-2.6.0-cdh5.14.0/ node03:$PWD
六:配置hadoop的環境變數
三臺機器執行以下命令
vim /etc/profile
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
注:可以不用拷貝到每臺機器
scp /etc/profile node02:/etc/
scp /etc/profile node03:/etc/
配置完成之後生效 每臺機器都更新一遍
source /etc/profile
七:叢集啟動
要啟動 Hadoop 叢集,需要啟動 HDFS 和 YARN 兩個叢集。
注意:
首次啟動HDFS時,必須對其進行格式化操作。本質上是一些清理和準備工作,因為此時的 HDFS 在物理上還是不存在的。
在主節點格式化:
bin/hdfs namenode -format 或者
bin/hadoop namenode -format


{{{{單個節點逐一啟動 [基本不用]
在主節點上使用以下命令啟動 HDFS NameNode:
|
hadoop-daemon.sh start namenode //一臺一個程序 namenode |
hadoop-daemons.sh start namenode //多臺機器同時啟動namenode、的程序
只需要把命令中的start 改為stop 即可}}}}
指令碼一鍵啟動(推薦)
如果配置了 etc/hadoop/slaves 和 ssh 免密登入,則可以使用程式指令碼啟動所有Hadoop 兩個叢集的相關程序,在主節點所設定的機器上執行。
啟動叢集
node01節點上執行以下命令
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
【或者:sbin/start-all.sh 和 啟動 sbin/mr-jobhistory-daemon.sh stop historyserver】
停止叢集:沒事兒不要去停止叢集
sbin/stop-dfs.sh
sbin/stop-yarn.sh
sbin/mr-jobhistory-daemon.sh stop historyserver
八:瀏覽器檢視啟動頁面
hdfs叢集訪問地址
yarn叢集訪問地址
jobhistory訪問地址:[和自己啟動historyserver 位置相同]
HDFS 使用初體驗
從Linux 本地上傳一個文字檔案到 hdfs 的/test/input 目錄下
hadoop fs -mkdir -p /test/input
hadoop fs -put /root/install.log /test/input
mapreduce程式初體驗
在 Hadoop 安裝包的
hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce 下有官方自帶的mapreduce 程式。我們可以使用如下的命令進行執行測試。
示例程式jar:
hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar
計算圓周率:
|
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.14.0.jar pi 2 5 |
關於圓周率的估算,感興趣的可以查詢資料 Monte Carlo 方法來計算 Pi 值。
注: pi 後面的值 2 5 不要改大, 測試即可, 太大有些同學的電腦會崩潰
九:測試寫入速度
向HDFS檔案系統中寫入資料,10個檔案,每個檔案10MB,檔案存放到
/benchmarks/TestDFSIO中
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.0.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
完成之後檢視寫入速度結果
hdfs dfs -text /benchmarks/TestDFSIO/io_write/part-00000
十:測試讀取速度
測試hdfs的讀取檔案效能
在HDFS檔案系統中讀入10個檔案,每個檔案10M
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.0.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
檢視讀取結果
hdfs dfs -text /benchmarks/TestDFSIO/io_read/part-00000
十一:清除測試資料
hadoop jar /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.0-cdh5.14.0.jar TestDFSIO -clean
更多基準測試參見:實際工作中按照自己的叢集配置進行測試