
Hive on Spark 偽分散式環境搭建過程記錄
進入hive cli是,會有如下提示:
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Hive預設使用MapReduce作為執行引擎,即Hive on mr。實際上,Hive還可以使用Tez和Spark作為其執行引擎,分別為Hive on Tez和Hive on Spark。由於MapReduce中間計算均需要寫入磁碟,而Spark是放在記憶體中,所以總體來講Spark比MapReduce快很多。因此,Hive on Spark也會比Hive on mr快。為了對比Hive on Spark和Hive on mr的速度,需要在已經安裝了Hadoop叢集的機器上安裝Spark叢集(Spark叢集是建立在Hadoop叢集之上的,也就是需要先裝Hadoop叢集,再裝Spark叢集,因為Spark用了Hadoop的HDFS、YARN等),然後把Hive的執行引擎設定為Spark。
Spark執行模式分為三種:
1、Spark on YARN
2、Standalone Mode
3、Spark on Mesos
Hive on Spark預設支援Spark on YARN模式,本次部署也選擇Spark on YARN模式。Spark on YARN就是使用YARN作為Spark的資源管理器。分為Cluster和Client兩種模式。
基礎環境資訊
Centos7
JDK1.8
偽分散式的hadoop-2.7.7叢集
hive-2.1.1(可正常使用hive on mr)
maven-3.5.4
scala-2.11.6
編譯環境要能連線網際網路
編譯Spark
Hive on Spark,所用的Spark版本必須不包含Hive的相關jar包,hive on spark 的官網上說“Note that you must have a version of Spark which does not include the Hive jars”。在spark官網下載的編譯的Spark都是有整合Hive的,因此需要自己下載原始碼來編譯,並且編譯的時候不指定Hive。
Hive和Spark的相容版本也有要求,可參照官網配套說明選擇,本次使用hive2.1.1,選的spark版本為spark-1.6.3,對hadoop的版本並未有明顯限制,確保大版本一致即可。
hive官網連線
https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started

下載hive1.6.3原始碼
http://spark.apache.org/downloads.html
編譯前請確保已經安裝基礎環境資訊中列出的JDK、Maven和Scala,並在/etc/profile裡配置環境變數。
編譯spark原始碼
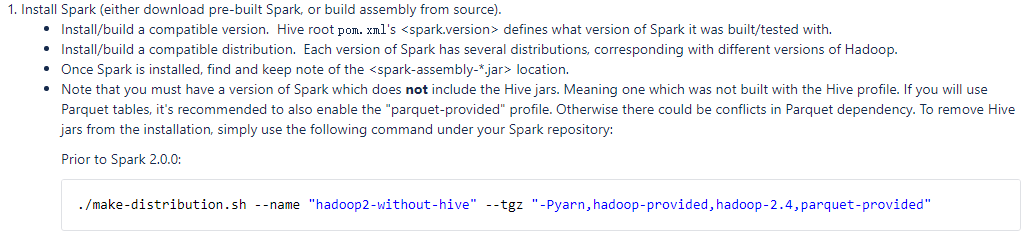
解壓原始碼檔案,並進入解壓後的原始碼目錄,執行hive官網提供的編譯命令,編譯spark-1.6.3-bin-hadoop2-without-hive.tgz安裝包
[root@node222 spark-1.6.3]# ./make-distribution.sh --name "hadoop2-without-hive" --tgz "-Pyarn,hadoop-provided,hadoop-2.4,parquet-provided"
經過漫長的編譯和等待(取決於編譯伺服器的資源和網路情況),出現以下輸出,說明編譯成功。
並在編譯目錄下生成spark-1.6.3-bin-hadoop2-without-hive.tgz包。
安裝配置spark
解壓spark-1.6.3-bin-hadoop2-without-hive.tgz至/usr/local/目錄,並修改解壓後的目錄名稱為spark-1.6.3
配置環境變數,並使配置生效
export SPARK_HOME=/usr/local/spark-1.6.3
export SCALA_HOME=/usr/local/scala-2.11.6
export PATH=.:$SPARK_HOME/bin:$SCALA_HOME/bin:$PATH配置spark-env.sh
修改spark-env.sh.template檔名spark-env.sh,在檔案未追加如下內容
[root@node222 spark-1.6.3]# mv conf/spark-env.sh.template conf/spark-env.sh
export SCALA_HOME=/usr/local/scala-2.11.6
export JAVA_HOME=/usr/local/jdk1.8.0_121
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-1.6.3
export SPARK_MASTER_IP=node222
export SPARK_EXECUTOR_MEMORY=512M
# 否則啟動時會報錯誤 Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/conf/Configuration
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.7.7/bin/hadoop classpath)配置spark-defaults.conf
修改spark-defaults.conf.template檔名,在檔案未追加如下內容
spark.master spark://node222:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node222:9000/user/spark-log
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512M
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"配置YARN

[root@node222 spark-1.6.3]# vi /usr/local/hadoop-2.7.7/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>將spark依賴jar包拷貝至hive的lib目錄
[root@node222 spark-1.6.3]# cp lib/spark-assembly-1.6.3-hadoop2.4.0.jar /usr/local/hive-2.1.1/lib/配置hive-site.xml檔案
增加如下內容,需要結合實際環境修改
<!--hive on spark or spark on yarn -->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>spark.home</name>
<value>/usr/local/spark-1.6.3</value>
</property>
<property>
<name>spark.master</name>
<value>spark://node222:7077</value>
</property>
<property>
<name>spark.submit.deployMode</name>
<value>client</value>
</property>
<property>
<name>spark.eventLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.eventLog.dir</name>
<value>hdfs://node222:9000/user/spark-log</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<property>
<name>spark.executor.memeory</name>
<value>512m</value>
</property>
<property>
<name>spark.driver.memeory</name>
<value>512m</value>
</property>
<property>
<name>spark.executor.extraJavaOptions</name>
<value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value>
</property>啟動spark
啟動前確保hadoop基礎環境已正常啟動
[root@node222 spark-1.6.3]# sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-1.6.3/logs/spark-root-org.apache.spark.deploy.master.Master-1-node222.out
localhost: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-1.6.3/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node222.out
[root@node222 spark-1.6.3]# jps
91507 JobHistoryServer
122595 Jps
92178 HQuorumPeer
122374 Master
122486 Worker
86859 ResourceManager
92251 HMaster
92397 HRegionServer
86380 NameNode
86684 SecondaryNameNode
86959 NodeManager
86478 DataNode通過webui檢視spark
http://192.168.0.222:8080/
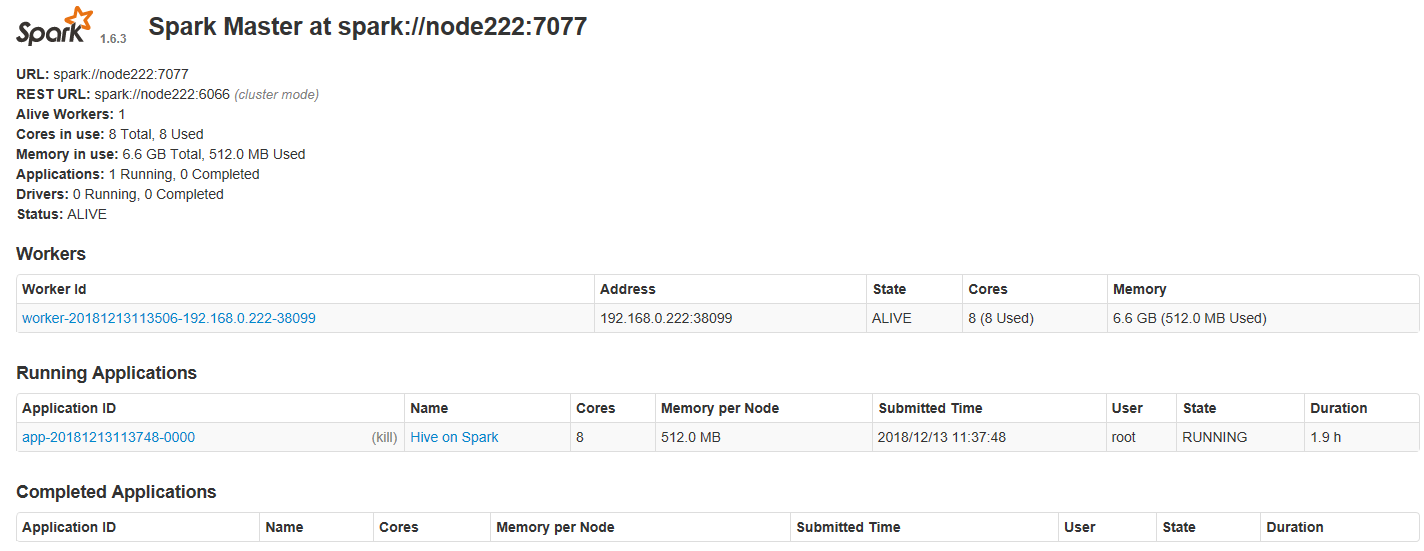
執行hive命令驗證hive on spark
[root@node222 spark-1.6.3]# hive
Logging initialized using configuration in jar:file:/usr/local/hive-2.1.1/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true
hive> use default;
OK
Time taken: 1.247 seconds
hive> show tables;
OK
kylin_account
kylin_cal_dt
kylin_category_groupings
kylin_country
kylin_sales
Time taken: 0.45 seconds, Fetched: 15 row(s)
hive> select count(1) from kylin_sales;
Query ID = root_20181213152833_9ca6240f-7ead-4565-b21d-fb695259da3b
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Spark Job = 15967d00-97a6-4705-9fa2-e7a2ef3c3798
Query Hive on Spark job[0] stages:
0
1
Status: Running (Hive on Spark job[0])
Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount [StageCost]
2018-12-13 15:28:53,906 Stage-0_0: 0(+1)/1 Stage-1_0: 0/1
2018-12-13 15:28:56,943 Stage-0_0: 0(+1)/1 Stage-1_0: 0/1
2018-12-13 15:28:59,966 Stage-0_0: 0(+1)/1 Stage-1_0: 0/1
2018-12-13 15:29:02,988 Stage-0_0: 0(+1)/1 Stage-1_0: 0/1
2018-12-13 15:29:04,000 Stage-0_0: 1/1 Finished Stage-1_0: 0(+1)/1
2018-12-13 15:29:05,014 Stage-0_0: 1/1 Finished Stage-1_0: 1/1 Finished
Status: Finished successfully in 21.17 seconds
OK
10000
Time taken: 31.752 seconds, Fetched: 1 row(s)