
python爬蟲基礎(13:Scrapy框架之架構流程與目錄)
框架
對於特別小的爬蟲,一般直接編寫就可以了,但一般面對一個專案級別的爬蟲,都選擇用框架
框架可以理解為一個 等你填坑的程式碼:
1. 為你編寫好那些必須的、重複的程式碼
2. 為你模組化好每一個元件,自動建立元件之間的聯絡,這樣就方便使用者清晰瞭解它的流程和各功能的定製
Scrapy框架架構和原理
Scrapy就是一個爬蟲常用的框架,我們先來了解一下它的結構和原理:
元件圖
元件介紹
Scrapy Engine: 這是引擎,負責Spiders、ItemPipeline、Downloader、Scheduler中間的通訊,訊號、資料傳遞等等!(像不像人的身體?)
Scheduler(排程器): 它負責接受引擎傳送過來的requests請求,並按照一定的方式進行整理排列,入隊、並等待Scrapy Engine(引擎)來請求時,交給引擎。
Downloader(下載器):負責下載Scrapy Engine(引擎)傳送的所有Requests請求,並將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spiders來處理,
Spiders:它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,並將需要跟進的URL提交給引擎,再次進入Scheduler(排程器),
Item Pipeline:它負責處理Spiders中獲取到的Item,並進行處理,比如去重,持久化儲存(存資料庫,寫入檔案,總之就是儲存資料用的)
Downloader Middlewares(下載中介軟體):你可以當作是一個可以自定義擴充套件下載功能的元件
Spider Middlewares(Spider中介軟體):你可以理解為是一個可以自定擴充套件和操作引擎和Spiders中間‘通訊‘的功能元件(比如進入Spiders的Responses;和從Spiders出去的Requests)
執行流程
引擎:Hi!Spider, 你要處理哪一個網站?
Spiders:我要處理23wx.com
引擎:你把第一個需要的處理的URL給我吧。
Spiders:給你第一個URL是XXXXXXX.com
引擎:Hi!排程器,我這有request你幫我排序入隊一下。
排程器:好的,正在處理你等一下。
引擎:Hi!排程器,把你處理好的request給我,
排程器:給你,這是我處理好的request
引擎:Hi!下載器,你按照下載中介軟體的設定幫我下載一下這個request
下載器:好的!給你,這是下載好的東西。(如果失敗:不好意思,這個request下載失敗,然後引擎告訴排程器,這個request下載失敗了,你記錄一下,我們待會兒再下載。)
引擎:Hi!Spiders,這是下載好的東西,並且已經按照Spider中介軟體處理過了,你處理一下(注意!這兒responses預設是交給def parse這個函式處理的)
Spiders:(處理完畢資料之後對於需要跟進的URL),Hi!引擎,這是我需要跟進的URL,將它的responses交給函式 def xxxx(self, responses)處理。還有這是我獲取到的Item。
引擎:Hi !Item Pipeline 我這兒有個item你幫我處理一下!排程器!這是我需要的URL你幫我處理下。然後從第四步開始迴圈,直到獲取到你需要的資訊,
注意!只有當排程器中不存在任何request了,整個程式才會停止,(也就是說,對於下載失敗的URL,Scrapy會重新下載。)
以上就是Scrapy整個流程了。

Scrapy目錄介紹
1.建立Scrapy專案
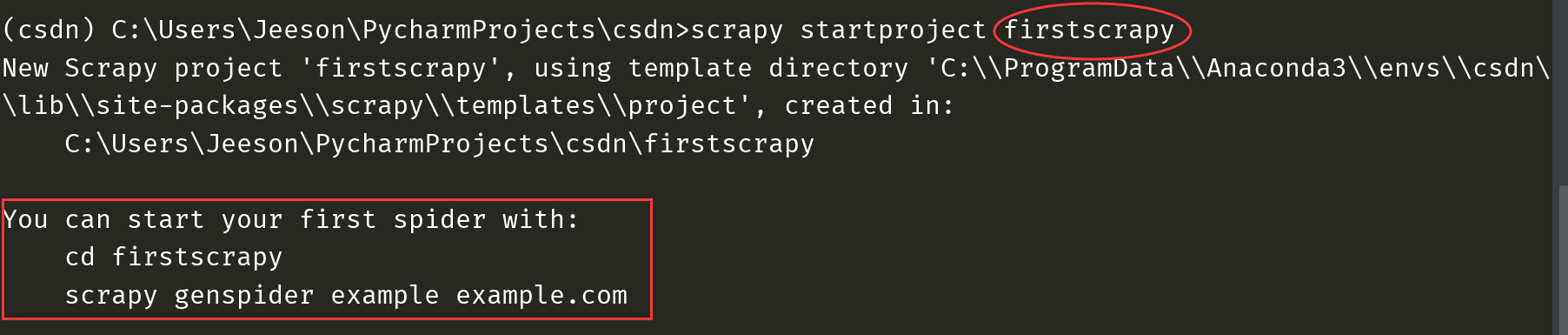
命令:scrapy startproject firstscrapy (firstscrapy是自己命名的專案名稱,出現以下內容代表成功)
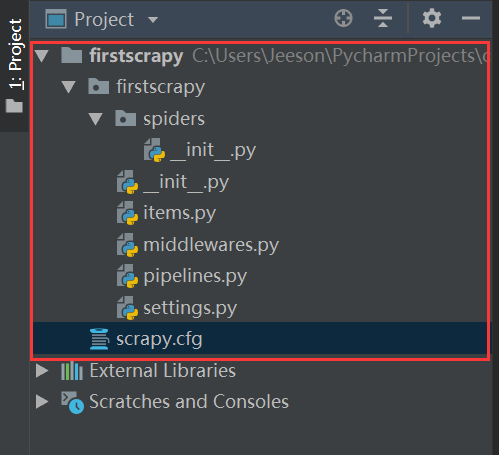
2.專案目錄簡介:
用pycharm開啟剛才建立的專案後,全部展開得到以下目錄
----------fisrtscrapy 整個專案的容器
-----------fisrtscrapy 專案檔案
----------spider 爬蟲檔案放這個目錄裡面,可以放很多,微博啊、知乎啊、豆瓣等
----------__init__.py:爬蟲初始化檔案,可以先不管
-----------__init__.py:專案初始化檔案, 可以先不管
-----------items.py:定義要爬取資料的格式,這樣統一的格式方便資料在各個模組間流轉
-----------middlewares.py:中介軟體,對request等進行定製的模組,相當於一個包裝部門,可以先不管
-----------pipilines.py:對爬到資料進行處理的模組,儲存啊、去重啊、修改等
-----------settings.py:對各個模組和功能配置檔案,裡面全是註釋,一般都是用到哪個功能了,就把哪兒 的註釋取消掉
-----------scrapy.cfg 專案配置檔案, 可以先不管
認識了Scrapy的架構、流程和目錄後,我們下篇將用專案來演示編寫流程