
Machine Learning(1)
機器學習(Machine Learning, ML)是一門多領域交叉學科,涉及概率論、統計學、逼近論、凸分析、演算法複雜度理論等多門學科。專門研究計算機怎樣模擬或實現人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的效能。
機器學習步驟:define a set of function->goodness of function->pick the best function
分類
1、Non-linear Model(非線性模型)
例如:預測明天上午的PM2.5


與線性模型區別:
①線性模型是可用曲線擬合的,但分類的決策邊界一定是直線的
②區分線性模型主要看自變數x的係數w是否隻影響一個x,若是,則是線性模型
③舉例:

2、Classification(分類)
在所有輸入當中選擇類別,例如:在輸入的郵件中選擇垃圾郵件。給新聞分類(政治、經濟、娛樂、、、)
另外機器學習下圍棋也是在分類
3、Transfer Learning(遷移學習)
通俗來講,就是運用已有的知識來學習新的知識,核心是找到已有知識和新知識之間的相似性,用成語來說就是舉一反三。通俗來講,就是運用已有的知識來學習新的知識,核心是找到已有知識和新知識之間的相似性,用成語來說就是舉一反三。
遷移學習按照學習方式可以分為基於樣本的遷移,基於特徵的遷移,基於模型的遷移,以及基於關係的遷移。
4、Unsupervised Learning(無監督學習)&Supervised Learning(監督學習)
在監督學習中,賦給演算法的資料裡包含著期望得到的結果,這些東西叫 Labels(標籤)。比如一個郵件垃圾過濾系統,訓練它的時候用的郵件資料帶著標籤,郵件例項的標籤表示郵件是正常郵件,還是垃圾郵件。
常見的監管學習任務有 Classification(分類)。郵件垃圾過濾器得到一個郵件,會知道它的類別屬於正常郵件還是垃圾郵件。
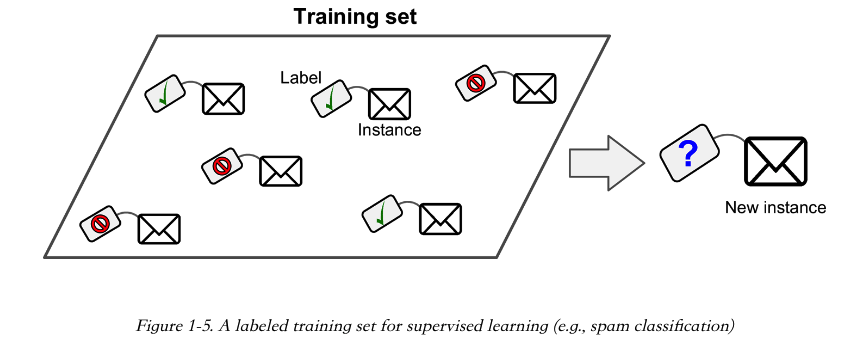
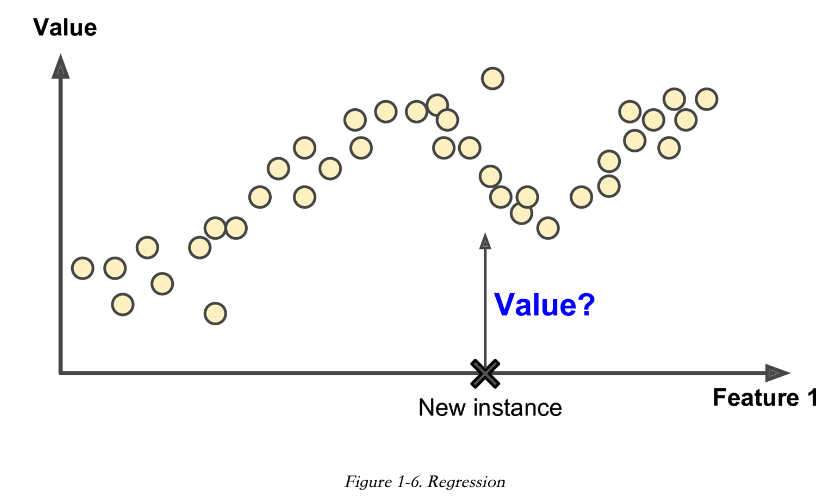
還有種常見的任務是預測目標值。比如一輛二手車,根據它的一些 Features(特徵),比如里程,車齡,品牌等等來預測這輛車的價值。這種任務叫 Regression(迴歸),它是統計學裡的概念。訓練這種系統,你得提供很多汽車示例,包含他們的 Predictors(就是上面提到的 Features),還有 Labels,比如汽車的價格。
在機器學習中,Attribute(屬性) 是一種資料型別,比如汽車的里程。Feature 根據語境有幾種意思,一般它表示的就是:屬性 + 值,比如 里程:15,000。 有時候這兩個名詞也會交替使用。
無監督學校,同樣,給了樣本,但是這個樣本是隻有資料,但是沒有其對應的結果,要求直接對資料進行分析建模。
比如我們去參觀一個畫展,我們完全對藝術一無所知,但是欣賞完多幅作品之後,我們也能把它們分成不同的派別(比如哪些更朦朧一點,哪些更寫實一些,即使我們不知道什麼時候叫做朦朧派,什麼叫做寫實派,但是至少我們能夠把它們分為兩類)。無監督學習裡面典型的例子就是聚類,聚類的目的在於把相似的東西聚在一起,而我們並不關心這一類是什麼,因此,一個聚類演算法通常只需要知道如何計算相似度就可以開始工作了。
“再比如,買房的時候,給了房屋面積以及其對應的價格,進行分析,這個就叫做監督學習;但是給了面積,沒有給價格,就叫做非監督學習。監督,意味著給了一個標準作為'監督' (或者理解為限制)。就是說建模之後是有一個標準用來衡量你的對與錯;非監督就是沒有這個標準,對資料進行聚類之後,並沒有一個標準進行對其的衡量。”
5、Reinforcement Learning
Supervised VS Reinforcement Learning
S:手把手教,有正確答案learning from teacher
R:無正確答案learning from critics
