
SpringBoot中如何使用jpa和jpa的相關知識總結
1.介紹jpa的簡單概念:
JPA顧名思義就是Java Persistence API的意思,是JDK 5.0註解或XML描述物件-關係表的對映關係,並將執行期的實體物件持久化到資料庫中。
2.jpa的優勢:
2.1標準化 JPA 是 JCP 組織釋出的 Java EE 標準之一,因此任何聲稱符合 JPA 標準的框架都遵循同樣的架構,提供相同的訪問API,這保證了基於JPA開發的企業應用能夠經過少量的修改就能夠在不同的JPA框架下執行。 2.2容器級特性的支援 JPA框架中支援大資料集、事務、併發等容器級事務,這使得 JPA 超越了簡單持久化框架的侷限,在企業應用發揮更大的作用。 2.3簡單方便 JPA的主要目標之一就是提供更加簡單的程式設計模型:在JPA框架下建立實體和建立Java 類一樣簡單,沒有任何的約束和限制,只需要使用 javax.persistence.Entity進行註釋,JPA的框架和介面也都非常簡單,沒有太多特別的規則和設計模式的要求,開發者可以很容易的掌握。JPA基於非侵入式原則設計,因此可以很容易的和其它框架或者容器整合。 2.4查詢能力 JPA的查詢語言是面向物件而非面向資料庫的,它以面向物件的自然語法構造查詢語句,可以看成是Hibernate HQL的等價物。
3.jpa常用的註解:
| 註解 | 解釋 |
|---|---|
| @Entity | 宣告類為實體或表。 |
| @Table | 宣告表名。 |
| @Basic | 指定非約束明確的各個欄位。 |
| @Embedded | 指定類或它的值是一個可嵌入的類的例項的實體的屬性。 |
| @Id | 指定的類的屬性,用於識別(一個表中的主鍵)。 |
| @GeneratedValue | 指定如何標識屬性可以被初始化,例如自動、手動、或從序列表中獲得的值。 |
| @Transient | 指定的屬性,它是不持久的,即:該值永遠不會儲存在資料庫中。 |
| @Column | 指定持久屬性欄屬性。 |
| @SequenceGenerator | 指定在@GeneratedValue註解中指定的屬性的值。它建立了一個序列。 |
| @TableGenerator | 指定在@GeneratedValue批註指定屬性的值發生器。它創造了的值生成的表。 |
| @AccessType | 這種型別的註釋用於設定訪問型別。如果設定@AccessType(FIELD),則可以直接訪問變數並且不需要getter和setter,但必須為public。如果設定@AccessType(PROPERTY),通過getter和setter方法訪問Entity的變數。 |
| @JoinColumn | 指定一個實體組織或實體的集合。這是用在多對一和一對多關聯。 |
| @UniqueConstraint | 指定的欄位和用於主要或輔助表的唯一約束。 |
| @ColumnResult | 參考使用select子句的SQL查詢中的列名。 |
| @ManyToMany | 定義了連線表之間的多對多一對多的關係。 |
| @ManyToOne | 定義了連線表之間的多對一的關係。 |
| @OneToMany | 定義了連線表之間存在一個一對多的關係。 |
| @OneToOne | 定義了連線表之間有一個一對一的關係。 |
| @NamedQueries | 指定命名查詢的列表。 |
| @NamedQuery | 指定使用靜態名稱的查詢。 |
4.實戰
4.1新增maven依賴包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>4.2配置檔案:
在application.yml檔案中新增如下配置
spring.datasource.url=jdbc:mysql://localhost:3306/zdb3
spring.datasource.username=zdb
spring.datasource.password=zdb
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.properties.hibernate.hbm2ddl.auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.show-sql= true
jpa.hibernate.ddl-auto是hibernate的配置屬性,其主要作用是:自動建立、更新、驗證資料庫表結構。該引數的幾種配置如下: ·create:每次載入hibernate時都會刪除上一次的生成的表,然後根據你的model類再重新來生成新表,哪怕兩次沒有任何改變也要這樣執行,這就是導致資料庫表資料丟失的一個重要原因。 ·create-drop:每次載入hibernate時根據model類生成表,但是sessionFactory一關閉,表就自動刪除。 ·update:最常用的屬性,第一次載入hibernate時根據model類會自動建立起表的結構(前提是先建立好資料庫),以後載入hibernate時根據model類自動更新表結構,即使表結構改變了但表中的行仍然存在不會刪除以前的行。要注意的是當部署到伺服器後,表結構是不會被馬上建立起來的,是要等應用第一次執行起來後才會。 ·validate:每次載入hibernate時,驗證建立資料庫表結構,只會和資料庫中的表進行比較,不會建立新表,但是會插入新值。
以上我們完成了基本的配置工作,記下來看一下如何進行表與實體的對映,以及資料訪問介面。
4.3建立實體以及資料訪問介面
首先來看一下實體類Person.java
@Entity
@Getter
@Setter
public class Person {
@Id
@GeneratedValue
private Long id;
@Column(name = "name", nullable = true, length = 20)
private String name;
@Column(name = "agee", nullable = true, length = 4)
private int age;
}然後需要dao層介面實現JpaRepository
public interface PersonRepository extends JpaRepository<Person, Long> {
}在web層中呼叫:
@RestController
@RequestMapping(value = "person")
public class PerconController {
@Autowired
private PersonRepository personRepository;
@PostMapping(path = "addPerson")
public void addPerson(Person person) {
personRepository.save(person);
}
@DeleteMapping(path = "deletePerson")
public void deletePerson(Long id) {
personRepository.delete(id);
}
}當執行專案的時候,查詢資料庫的時候發現已經幫助我們建立表:
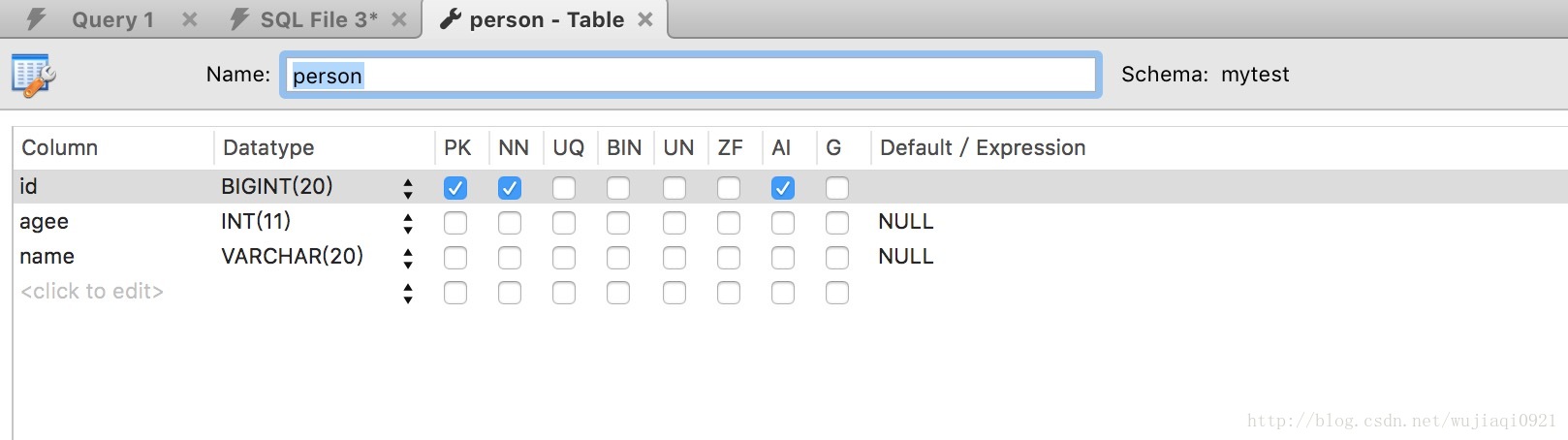
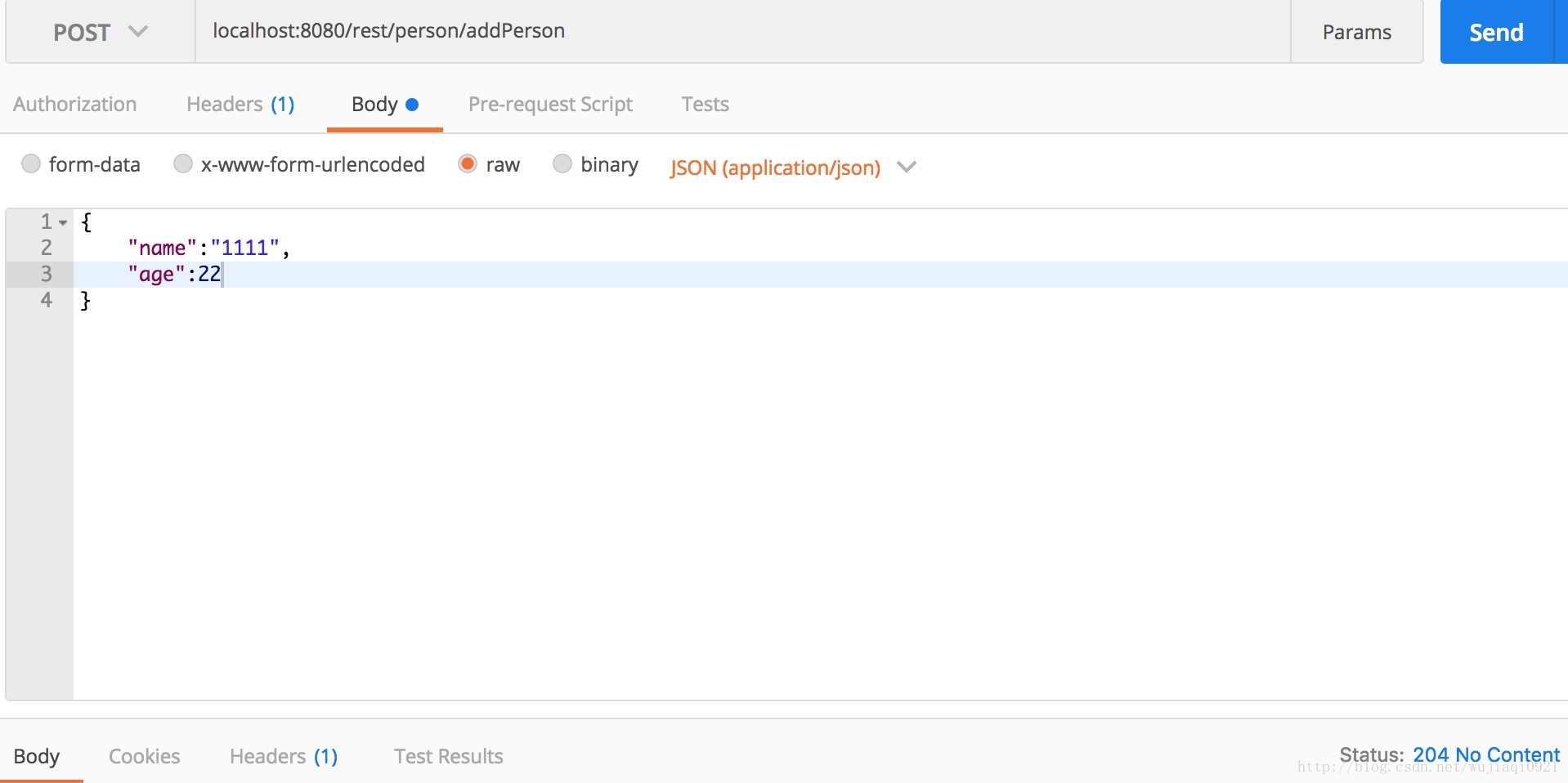
接下來我們呼叫一下addPerson介面。我們使用postman來測試:
然後通過查詢資料庫來看一下結果: 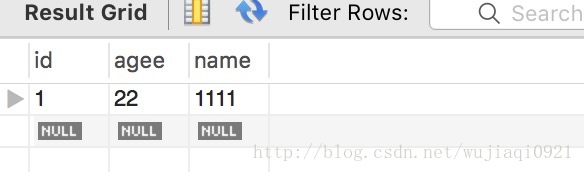
接下來我們來看一下如何編寫自己的方法。我們以根據name查詢person為例。新增一個rest介面
@GET
@Produces(TYPE_JSON)
@Path("getPerson")
public Object getPerson(@QueryParam("name") String name) {
return personRepository.findByName(name);
}- 1
- 2
- 3
- 4
- 5
- 6
並在repository介面中新增如下查詢方法:
Person findByName(String name);- 1
重啟之後讓我們來看一下查詢結果
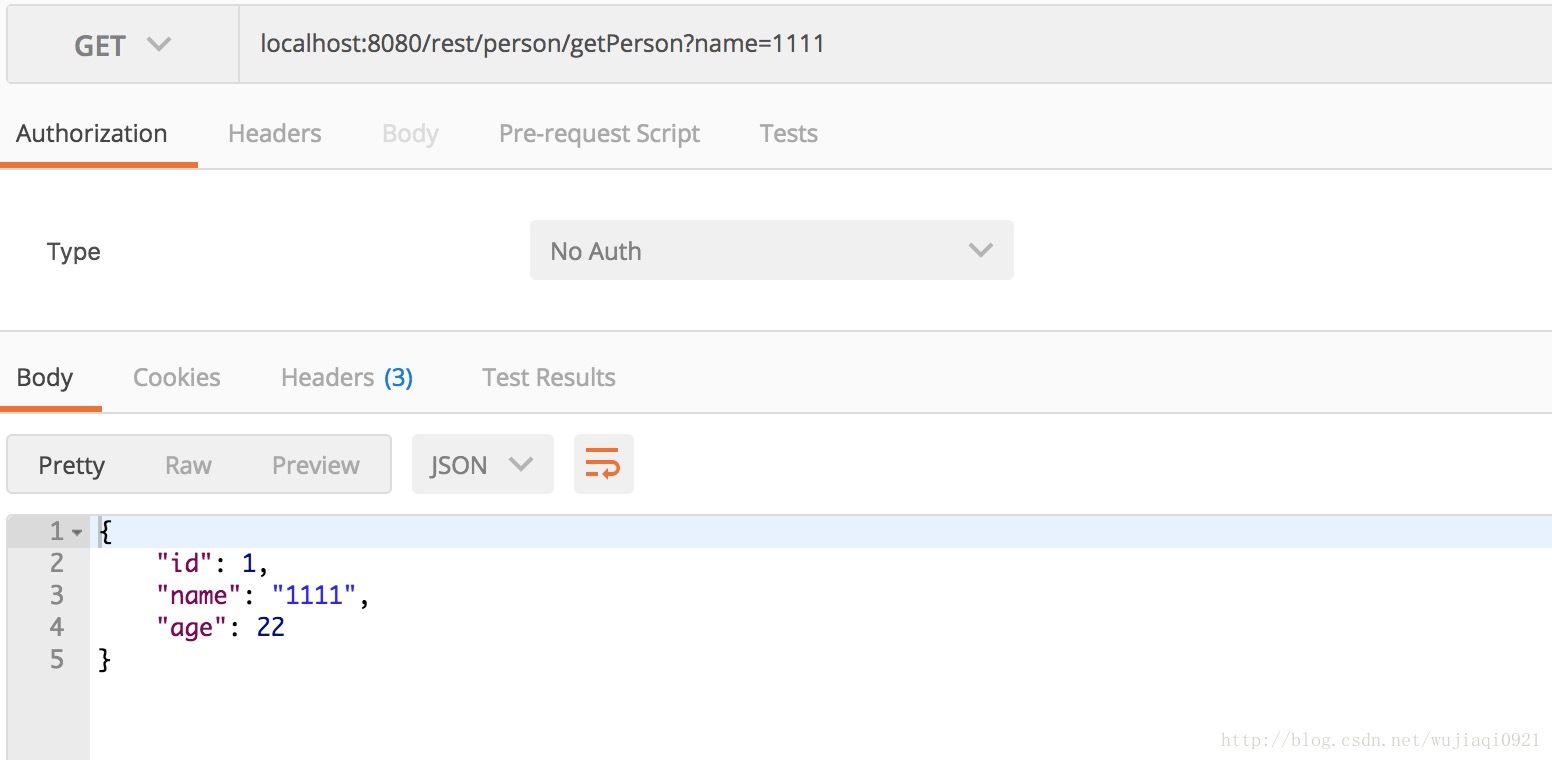
Hibernate: select person0_.id as id1_0_, person0_.agee as agee2_0_, person0_.name as name3_0_ from person person0_ where person0_.name=?
那麼JPA是通過什麼規則來根據方法名生成sql語句查詢的呢? 其實JPA在這裡遵循Convention over configuration(約定大約配置)的原則,遵循spring 以及JPQL定義的方法命名。Spring提供了一套可以通過命名規則進行查詢構建的機制。這套機制會把方法名首先過濾一些關鍵字,比如 find…By, read…By, query…By, count…By 和 get…By 。系統會根據關鍵字將命名解析成2個子語句,第一個 By 是區分這兩個子語句的關鍵詞。這個 By 之前的子語句是查詢子語句(指明返回要查詢的物件),後面的部分是條件子語句。如果直接就是 findBy… 返回的就是定義Respository時指定的領域物件集合,同時JPQL中也定義了豐富的關鍵字:and、or、Between等等,下面我們來看一下JPQL中有哪些關鍵字:
| Keyword | Sample | JPQL snippet |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is,Equals | findByFirstnameIs,findByFirstnameEquals | … where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age ⇐ ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| TRUE | findByActiveTrue() | … where x.active = true |
| FALSE | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
| …… |
以上就是jpa的簡單實用和介紹。