
結構體和聯合體相關知識總結
1.結構體和陣列都是聚合資料型別,它們之間有以下的區別:
陣列是同種型別元素的集合,而結構體是相同或者不同的資料元素的集合。
陣列名在傳參時會退化為一個指標,但是結構體在作為函式引數時不會發生退化。
陣列可以通過下標來訪問某個元素,而結構體是通過結構體的成員名來訪問成員的。
struct A
{
char a;//1 對齊數:1
double b;// 8 對齊數:8
int c;//4 對齊數:4
};
這叫做聲明瞭一個結構體型別,並沒有開闢空間。
上面定義的結構體是定義了一種聚合型別,這是一種自定義型別。
而int . float . char.等屬於內建型別。
結構體的基本概念:
一般情況下,結構體標籤和結構體變數名必須至少有一個。
在定義一個結構體變數時,可以使用標籤,例如struct tag a;這裡的a即就是結構體變數。定義結構體變數時開闢空間。
訪問結構體成員時可以有兩種方法:
1.直接訪問:使用(.)操作符,.操作符的優先順序是從左到右。
2.間接訪問:使用箭頭操作符(->),應注意,這裡的箭頭操作符的左運算元必須是指標變數。
結構體的不完整宣告:
如果有兩個結構體需要互相引用對方,那麼最好使用不完整宣告,在引用對方時最好定義指向那個結構體的指標,而不是定義那個結構體的變數。
結構體的初始化類似與指標,可以使用{}來初始化結構體成員。
在c語言中,結構體成員至少要有一個,在vs2013下,不能定義一個空結構體,而在linux下,空結構體大小為0,在c++下,空結構體的大小為1.
結構體為什麼會有記憶體對齊?
對齊原因:
1、平臺原因(移植原因):
不是所有的硬體平臺都能訪問任意地址上的任意資料的;
某些硬體平臺只能在某些地址處取某些特定型別的資料,否則丟擲硬體異常。2、效能原因:資料結構(尤其是棧)應該儘可能地在自然邊界上對齊。
原因在於,為了訪問未對齊的記憶體,處理器需要作兩次記憶體訪問;而對齊的記憶體訪問僅需要一次訪問。
其他:
指定對齊值:#pragma pack (value)時的指定對齊值value。
#pragma pack () /取消指定對齊,恢復預設對齊/
結構體的記憶體對齊原則:
1.第一個成員在與結構體變數偏移量為0的地址處——也就是第一個變數沒有對齊數
2.其他成員變數要對齊到它的(對齊數)的整數倍的地址處
//對齊數 = 編譯器預設的一個對齊數與該成員大小的較小值。
// vs—-預設為8;
// linux—預設為43.結構體總大小為最大對齊數(每個成員變數除了第一個成員都有一個對齊數)的整數倍。
4.如果嵌套了結構體的情況,巢狀的結構體對齊到自己的最大對齊數的整數倍處,結構體的整體大小就是
最大對齊數(含巢狀結構體的對齊數)的整數倍。
下面通過例子來分析:(在linux下預設的對齊數是4)

注意:括號內是變數名,地址在累加,而每次前面的地址必須是後面變數對齊數的整數倍。
所以結構體p的大小為 4(e)+4(x)+1(y)+3(補得空間,因為ss結構體的最大對齊數為4) = 12(4的倍數)
12+3*20(3個結構體的大小) = 72
72(是3的倍數)+3 = 75
75(不是4的倍數,所以加1) +1 = 76(是4的倍數)
76+4(指標變數p的大小) = 80(是結構體p的最大對齊數 4的倍數)
所以結構體p的大小為80
位段(一般在協議中使用):(可以訪問一個數據中的bit位)
使用位域的主要目的是壓縮儲存
位段成員必須宣告為int 或unsigned int 或signed int型別。
宣告一個位段時:在成員名後是一個冒號和整數。例如:unsigned int a: 2.
其大致的規則為:
1) 如果相鄰位域欄位的型別相同,且其位寬之和小於型別的sizeof大小,則後面的欄位將緊鄰前一個欄位儲存,直到不能容納為止;
2) 如果相鄰位域欄位的型別相同,但其位寬之和大於型別的sizeof大小,則後面的欄位將從新的儲存單元開始,其偏移量為其型別大小的整數倍;
3) 如果相鄰的位域欄位的型別不同,則各編譯器的具體實現有差異,VC6採取不壓縮方式,Dev-C++採取壓縮方式;
4)如果位段之間穿插著非位域欄位,則不進行壓縮。
5)結構體總大小為最大對齊數的整數倍。
總體來看,位段的對齊方式和結構體對齊方式類似,宣告位域時最好宣告為同一種類型的。
測試位段在記憶體中的儲存方式:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
struct A
{
unsigned int a : 4;
unsigned int b : 4;
unsigned int c : 6;
unsigned int d : 13;
unsigned int e : 6;
}obj;
int main()
{
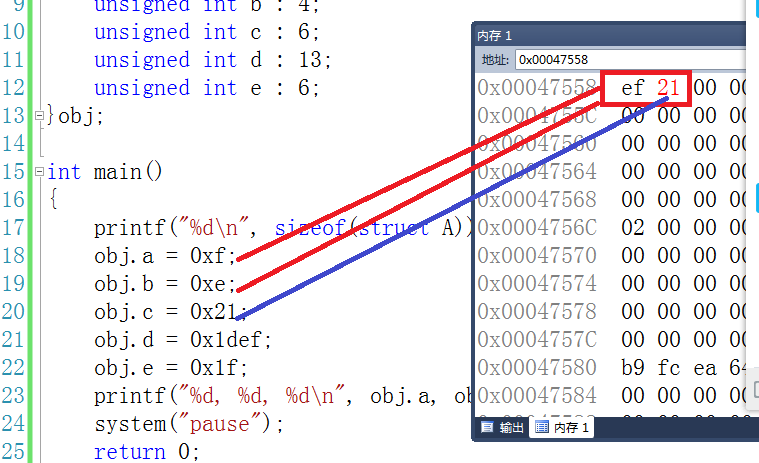
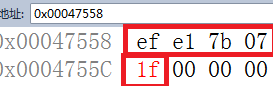
printf("%d\n", sizeof(struct A));//8
obj.a = 0xf;
obj.b = 0xe;
obj.c = 0x21;
obj.d = 0x1def;
obj.e = 0x1f;
printf("%d, %d, %d\n", obj.a, obj.b, obj.c);
system("pause");
return 0;
}
位段的對齊方式類似與結構體:

注意:
當一個位段變數的大小可以和前面已定義的位段存放在一個整型大小的空間時,就不用另外開闢空間,但是如果不夠儲存,則另外再開闢一個整型變數的大小,從它的型別的對齊數的倍數的地址處開始儲存。
聯合體(union):(也有記憶體對齊,所有的成員都必須對齊)
當多個數據需要共享記憶體或者多個數據每次只取其一時,可以利用聯合體(union)。
1)聯合體是一個結構;
2)它的所有成員相對於基地址的偏移量都為0;
3)此結構空間要大到足夠容納最”寬”的成員;
4)其對齊方式要適合其中所有的成員;
下面解釋這四條描述:
由於聯合體中的所有成員是共享一段記憶體的,因此每個成員的首地址相對於於聯合體變數的基地址的偏移量為0,即所有成員的首地址都是一樣的。為了使得所有成員能夠共享一段記憶體,因此該空間必須足夠容納這些成員中最寬的成員。對於這句“對齊方式要適合其中所有的成員”是指其必須符合所有成員的自身對齊方式。
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
struct A{
int a;
char b;
double c;//16
};
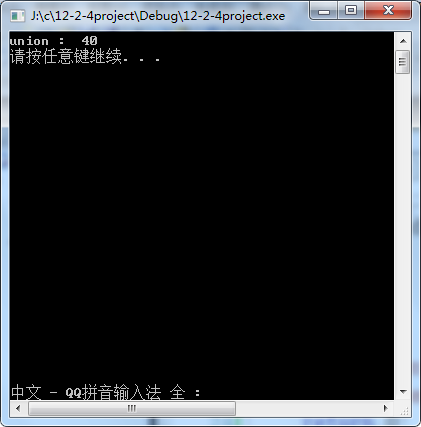
union un{
double a;
char b;
char g[39];//39 注意:結構體總的大小也要考慮記憶體對齊,聯合體也應該遵循它裡面的每個成員都應該記憶體對齊。
char c[5];
struct A d;//16
}obj;
int main()
{
printf("union :%d\n",sizeof(obj));
system("pause");
return 0;
}
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#pragma pack(4)//將預設對齊數設定為了4
struct A{
int a;//4
union {
int b;
char c;
char d[5];
}obj;//8
struct {
int e;
double f;
char g[5];
};//20
double x;//8
};//最終結構體的大小為40個位元組
int main()
{
printf("STRUCT : %d\n",sizeof(struct A));
system("pause");
return 0;
}
應特別注意的是:聯合體也需要記憶體對齊,指的是它內部所有的成員都應該自身對齊。
2017.1.17.更新
求解結構體中任意一個變數的地址的偏移量?——–offsetof巨集
1.#define offsetof(Type,member) (size_t)&(((Type*)0)->member)
巨集的功能:返回結構體中成員變數的偏移量
分析表示式:由內到外逐層分析
①0
②(Type )0—–可以看出,此表示式的意義是:將整型0強制型別轉換為(Type )型別的,(這裡的Type指的是結構體型別),
那麼分析得:將0強轉為了結構體指標型別,那麼0代表的就是一個sizeof(Type)大小的記憶體空間的首地址③(Type *)0->member—-可以這樣理解:定義了一個結構體指標,即強制型別轉換後的0,然後是訪問結構體成員的兩種方法中的第二種,使用指標,形式為:結構體指標->成員變數,所以這個表示式就是訪問結構體變數。
④&(((Type*)0)->member)——這個很好理解,就是給成員變數取地址。
⑤(size_t)&(((Type*)0)->member)——-將成員變數的地址強制型別轉換為size_t(unsigned int),地址肯定不會為負啦…
綜之分析:因為結構體的首地址取的是0,那麼成員變數的地址即就是結構體成員變數的偏移量啦。
下面舉例來看:

相關推薦
結構體和聯合體相關知識總結
1.結構體和陣列都是聚合資料型別,它們之間有以下的區別: 陣列是同種型別元素的集合,而結構體是相同或者不同的資料元素的集合。 陣列名在傳參時會退化為一個指標,但是結構體在作為函式引數時不會發生退化。 陣列可以通過下標來訪問某個元素,而結構體是
結構體和聯合體在記憶體分佈中的總結
結構體記憶體分佈三大原則: 原則1:資料成員對齊規則:結構(struct或聯合union)的資料成員,第一個資料成員放在offset為0的地方,以後每個資料成員儲存的起始位置要從該成員大小的整數
C和指標之結構體和聯合體
1、結構體基礎知識 聚合資料型別(aggregate data type)能夠同時儲存超過一個的單獨資料。C語言提供了兩種型別的聚合資料結構,陣列和結構體。 陣列是相同型別的資料元素的集合,它的每個元素都是通過下標引用或者指標間接訪問來選擇的;結構也是一些值的集合,這些值稱為它的成
C和指針之結構體和聯合體
第一個 test col 聚合 要求 拷貝 破壞 存儲位置 字節 1、結構體基礎知識 聚合數據類型(aggregate data type)能夠同時存儲超過一個的單獨數據。C語言提供了兩種類型的聚合數據結構,數組和結構體。 數組是相同類型的數據元素的集合,它的每個元
結構體和聯合體
原來 作用 變量 結構體 spa str 空間 union 它的 定義: 結構體是將不同的數據類型組成一個新的數據類型(自定義數據類型) 聯合是幾個不同的數據類型共用同一個內存段(相互覆蓋) 所占內存大小: 結構體變量所占內存長度是各成員占的內存長度的總和。 共同體所占內存
結構體和聯合體的區別——全網最佳文章
聯合體 用途:使幾個不同型別的變數共佔一段記憶體(相互覆蓋) 結構體是一種構造資料型別 用途:把不同型別的資料組合成一個整體-------自定義資料型別 總結: 宣告一個聯合體: [cpp] view plaincopy union
結構體和聯合體的位元組對齊問題
為了提速之類的,在結構體和聯合體的記憶體塊中,是按照一定的規則安排的 聯合體: 聯合體的記憶體不會為了所有成員安排,而是隻取最大的成員的所需記憶體大小,每次只能使用其中一個成員。但是有一個問題: typedef union { char a; int[5] b;
結構體和聯合體 的區別
struct和union都是由多個不同的資料型別成員組成; 同一時刻,struct中的資料成員可以都存在,union中的資料成員只能存放被選中的那個; struct的大小是所有資料成員的大小之和,union的大小等於其資料成員中最大的那個; 對於union的不同成員賦值,將
C語言系列(六)結構體和聯合體
結構體 在C語言中,可以使用結構體(Struct)來存放一組不同型別的資料。結構體的定義形式為: struct 結構體名{ 結構體所包含的變數或陣列 }; 結構體是一種集合,它裡面包含了多個變數或陣列,它們的型別可以相同,也可以不同,每
我計算結構體和聯合體大小的方法
#include <stdio.h> struct A { int i; char ch[9]; }; void main() { struct A a
WinForm開發,窗體顯示和窗體傳值相關知識總結
ica 簡單的 winform 隨著 open sender mes accep 構造函數 以前對WinForm窗體顯示和窗體間傳值了解不是很清楚最近做了一些WinForm開發,把用到的相關知識整理如下 A.WinForm中窗體顯示顯示窗體可以有以下2種方法:Form.Sh
SpringBoot中如何使用jpa和jpa的相關知識總結
1.介紹jpa的簡單概念: JPA顧名思義就是Java Persistence API的意思,是JDK 5.0註解或XML描述物件-關係表的對映關係,並將執行期的實體物件持久化到資料庫中。 2.jpa的優勢: 2.1標準化 JPA 是 JCP 組織釋出的 Java EE
Oracle樹形結構資料-相關知識總結
Oracle樹形結構資料--基本知識 1.資料組成 2.基本查詢 2.1.查詢某節點及該節點下的所有子孫節點 SELECT * FROM QIANCODE.TREE_TABLE_BASIC T START WITH T.ID='111' CONNECT BY PRIOR T.ID=T
UNIX網路程式設計-結構體和相關函式
IPv4結構體 除非涉及路由套接字,否則不用設定和檢查 sin_len 欄位 POSIX規範只要求結構中的3個欄位,sin_family,sin_addr,sin_port sin_family對應的是 sa_family_t sin_port 對應的是 in_
程序和執行緒相關知識總結
程序 1. 組成結構:由程式段、程式碼段和程序控制塊(PCB)組成。 2. 基本屬性:1)是一個可以獨立擁有資源的獨立單位 2)同時又是一個可獨立排程和分派的基本單位。 3. 三種基本狀態:就緒狀
【知識積累】C#中結構體和類的區別
【類】 類是對現實生活中一類具有共同特徵的事物的抽象。類的實質是一種資料型別,類似於int、char等基本型別,不同的是它是一種複雜的資料型別。因為它的本質是型別,而不是資料,所以不存
C 語言中的結構體和共用體(聯合體)
本文主要總結了譚浩強主編的《C 程式設計》教材中結構體和共用體相關章節的內容。 在 C 語言中, 結構體(struct) 是一個或多個變數的集合,這些變數可能為不同的型別,為了處理的方便而將這些變數組織在一個名字之下。由於結構體將一組相關變數看作一個單元而不是各自獨立的實體,因此結構體有助於組織複雜的資料,
結構體和結構體指標詳細總結
結構體:結構體也是一種資料型別,在一個結構體中包含了多種型別的資料,比如int,float,char等等。使用結構體可以很好地管理一批有聯絡的資料,使用結構體資料可以提高程式的易讀易寫效能。結構體也是C語言用的較多的型別,小型實時作業系統ucos,當讀其原始碼時,會發現指標結
資料結構預備知識之指標,結構體和動態記憶體的分配與釋放
資料結構的整體框架: 資料結構只解決儲存問題,演算法解決操作問題。演算法依附於儲存結構,儲存不同,演算法不同。 衡量演算法的標準: 時間複雜度:執行的次數而非時間空間複雜度:佔用的記憶體難易程度健壯性 1.預備知識之指標 記憶體是CPU唯一可以直接訪問的大容量儲存區域,
結構體、聯合體和位斷的記憶體對齊問題
記憶體對齊的原因: 1.平臺原因 不是所有硬體平臺都可以訪問任意地址上的任意資料; 某些硬體平臺只能在某些地址處取某些特定型別的資料,否則丟擲硬體異常。 2.效能原因 資料結構(尤其是