
用於CTC loss的幾種解碼方法:貪心搜尋 (greedy search)、束搜尋(Beam Search)、字首束搜尋(Prefix Beam Search)
在CTC網路中我們可以訓練出一個對映![]() :
:
假如序列目標為字串(詞表大小為 n),則Nw輸出為n維多項概率分佈。
網路輸出為:y=Nw,其中,![]() 表示t時刻輸出是第k項的概率。
表示t時刻輸出是第k項的概率。
但是這個輸出只是一組組概率,我們要由這個Nw得到我們預測的標籤,這就涉及到一個解碼的問題。
按照最大似然準則,最優的解碼結果為:

但是上式並不存在已知的高效解法。故我們可以採用下面介紹的幾種實用的近似破解碼方法。
貪心搜尋 (greedy search):
在實際過程中![]() 難以計算,但對於某個具體的字串 π(去 blank 前),我們可以計算出
難以計算,但對於某個具體的字串 π(去 blank 前),我們可以計算出![]() :
:
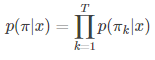
因此,我們放棄尋找使 ![]() 最大的字串,而是尋找一個使
最大的字串,而是尋找一個使![]() 最大的字串,即:
最大的字串,即:
![]()
![]()
簡化後,解碼過程(構造![]() )變得非常簡單(基於獨立性假設): 在每個時刻t時輸出概率最大的字元:
)變得非常簡單(基於獨立性假設): 在每個時刻t時輸出概率最大的字元:
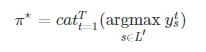
如:
假如y的分佈如下圖:

greedy search的結果為:

程式碼實現:
import numpy as np # 求每一列(即每個時刻)中最大值對應的softmax值 def softmax(logits): # 注意這裡求e的次方時,次方數減去max_value其實不影響結果,因為最後可以化簡成教科書上softmax的定義 # 次方數加入減max_value是因為e的x次方與x的極限(x趨於無窮)為無窮,很容易溢位,所以為了計算時不溢位,就加入減max_value項 # 次方數減去max_value後,e的該次方數總是在0到1範圍內。 max_value = np.max(logits, axis=1, keepdims=True) exp = np.exp(logits - max_value) exp_sum = np.sum(exp, axis=1, keepdims=True) dist = exp / exp_sum return dist def remove_blank(labels, blank=0): new_labels = [] # 合併相同的標籤 previous = None for l in labels: if l != previous: new_labels.append(l) previous = l # 刪除blank new_labels = [l for l in new_labels if l != blank] return new_labels def insert_blank(labels, blank=0): new_labels = [blank] for l in labels: new_labels += [l, blank] return new_labels def greedy_decode(y, blank=0): # 按列取最大值,即每個時刻t上最大值對應的下標 raw_rs = np.argmax(y, axis=1) # 移除blank,值為0的位置表示這個位置是blank rs = remove_blank(raw_rs, blank) return raw_rs, rs np.random.seed(1111) y_test = softmax(np.random.random([20, 6])) label_have_blank, label_no_blank = greedy_decode(y_test) print(label_have_blank) print(label_no_blank)
執行結果如下:
[1 3 5 5 5 5 1 5 3 4 4 3 0 4 5 0 3 1 3 3]
[1, 3, 5, 1, 5, 3, 4, 3, 4, 5, 3, 1, 3]
Process finished with exit code 0束搜尋(Beam Search):
貪心搜尋的效能非常受限。如它不能給出除最優路徑之外的其他其優路徑。很多時候,如果我們能拿到nearbest的路徑,後續可以利用其他資訊來進一步優化搜尋的結果。束搜尋能近似找出 top 最優的若干條路徑。
基本原理是通過 ![]() 中
中![]() 個序列,每個序列分別連線
個序列,每個序列分別連線![]() 中
中![]() 個節點,得到
個節點,得到 ![]()
如:
假設![]() 為2,。
為2,。
t=1時:

這個時候只會將兩個概率最大的節點放進路徑集合中,即有兩條路徑。
t=2時:
上面的兩個路徑每個路徑都會和下一個時間點的每一項組成新的路徑,因此一共有![]() 個新路徑。
個新路徑。

然後我們還是隻保留概率最大的兩條路徑(次大的兩個路徑相等,這裡捨棄掉一個)。

t=3時:

和t=2時類似,又組成了新的6條路徑。我們還是取概率最大的兩條路徑。

實際使用該演算法時,往往取前20,這裡前2只是為了方便舉例。
程式碼實現:
import numpy as np
# 求每一列(即每個時刻)中最大值對應的softmax值
def softmax(logits):
# 注意這裡求e的次方時,次方數減去max_value其實不影響結果,因為最後可以化簡成教科書上softmax的定義
# 次方數加入減max_value是因為e的x次方與x的極限(x趨於無窮)為無窮,很容易溢位,所以為了計算時不溢位,就加入減max_value項
# 次方數減去max_value後,e的該次方數總是在0到1範圍內。
max_value = np.max(logits, axis=1, keepdims=True)
exp = np.exp(logits - max_value)
exp_sum = np.sum(exp, axis=1, keepdims=True)
dist = exp / exp_sum
return dist
def remove_blank(labels, blank=0):
new_labels = []
# 合併相同的標籤
previous = None
for l in labels:
if l != previous:
new_labels.append(l)
previous = l
# 刪除blank
new_labels = [l for l in new_labels if l != blank]
return new_labels
def insert_blank(labels, blank=0):
new_labels = [blank]
for l in labels:
new_labels += [l, blank]
return new_labels
def beam_decode(y, beam_size=10):
# y是個二維陣列,記錄了所有時刻的所有項的概率
T, V = y.shape
# 將所有的y中值改為log是為了防止溢位,因為最後得到的p是y1..yn連乘,且yi都在0到1之間,可能會導致下溢位
# 改成log(y)以後就變成連加了,這樣就防止了下溢位
log_y = np.log(y)
# 初始的beam
beam = [([], 0)]
# 遍歷所有時刻t
for t in range(T):
# 每個時刻先初始化一個new_beam
new_beam = []
# 遍歷beam
for prefix, score in beam:
# 對於一個時刻中的每一項(一共V項)
for i in range(V):
# 記錄新增的新項是這個時刻的第幾項,對應的概率(log形式的)加上新的這項log形式的概率(本來是乘的,改成log就是加)
new_prefix = prefix + [i]
new_score = score + log_y[t, i]
# new_beam記錄了對於beam中某一項,將這個項分別加上新的時刻中的每一項後的概率
new_beam.append((new_prefix, new_score))
# 給new_beam按score排序
new_beam.sort(key=lambda x: x[1], reverse=True)
# beam即為new_beam中概率最大的beam_size個路徑
beam = new_beam[:beam_size]
return beam
np.random.seed(1111)
y_test = softmax(np.random.random([20, 6]))
beam_chosen = beam_decode(y_test, beam_size=100)
for beam_string, beam_score in beam_chosen[:20]:
print(remove_blank(beam_string), beam_score)執行結果如下:
[1, 3, 5, 1, 5, 3, 4, 3, 4, 5, 3, 1, 3] -29.261797539205567
[1, 3, 5, 1, 5, 3, 4, 3, 3, 5, 3, 1, 3] -29.279020152518033
[1, 3, 5, 1, 5, 3, 4, 2, 3, 4, 5, 3, 1, 3] -29.300726142201842
[1, 5, 1, 5, 3, 4, 3, 4, 5, 3, 1, 3] -29.310307014773972
[1, 3, 5, 1, 5, 3, 4, 2, 3, 3, 5, 3, 1, 3] -29.31794875551431
[1, 5, 1, 5, 3, 4, 3, 3, 5, 3, 1, 3] -29.327529628086438
[1, 3, 5, 1, 5, 4, 3, 4, 5, 3, 1, 3] -29.331572723457334
[1, 3, 5, 5, 1, 5, 3, 4, 3, 4, 5, 3, 1, 3] -29.33263180992451
[1, 3, 5, 4, 1, 5, 3, 4, 3, 4, 5, 3, 1, 3] -29.334649090836038
[1, 3, 5, 1, 5, 3, 4, 3, 4, 5, 3, 1, 3] -29.33969505198154
[1, 3, 5, 2, 1, 5, 3, 4, 3, 4, 5, 3, 1, 3] -29.339823066915415
[1, 3, 5, 1, 5, 4, 3, 3, 5, 3, 1, 3] -29.3487953367698
[1, 5, 1, 5, 3, 4, 2, 3, 4, 5, 3, 1, 3] -29.349235617770248
[1, 3, 5, 5, 1, 5, 3, 4, 3, 3, 5, 3, 1, 3] -29.349854423236977
[1, 3, 5, 1, 5, 3, 4, 3, 4, 5, 3, 3] -29.350803198551016
[1, 3, 5, 4, 1, 5, 3, 4, 3, 3, 5, 3, 1, 3] -29.351871704148504
[1, 3, 5, 1, 5, 3, 4, 3, 3, 5, 3, 1, 3] -29.356917665294006
[1, 3, 5, 2, 1, 5, 3, 4, 3, 3, 5, 3, 1, 3] -29.35704568022788
[1, 3, 5, 1, 5, 3, 4, 5, 4, 5, 3, 1, 3] -29.363802591012263
[1, 5, 1, 5, 3, 4, 2, 3, 3, 5, 3, 1, 3] -29.366458231082714
Process finished with exit code 0可以看到log形式的score連加的結果都是負數,這是因為logx,當x屬於0到1之間時logx為負的。
字首束搜尋(Prefix Beam Search):
束搜尋(Beam Search)存在的一個問題是,在儲存的 top N 條路徑中,可能存在多條實際上是同一結果(經過去重複、去 blank 操作後的)。這減少了搜尋結果的多樣性。字首束搜尋(Prefix Beam Search)方法,可以在搜尋過程中不斷的合併相同的字首。
probabilityWithBlank和probabilityNoBlank分別代表最後一個字元是空格和最後一個字元不是空格的概率。
如:
當t=2時,many-to-one map後為[1]的序列有三種:[1,0],[0,1],[1,1],其中[1,0]是尾部帶blank的情況,[0,1]和[1,1]是尾部不帶blank的情況,那麼假設t=3時label為1,那麼新的序列就有以下幾種情況。
[1,0]+[1]=[1,0,1]->[1,0,1]
[0,1]+[1]=[0,1,1]->[1]
[1,1]+[1]=[1,1,1]->[1]
後兩者是新的尾部不為blank的序列,可見尾部不為blank在新序列產生的時候是可以算作一種情況的,這就是為什麼要分為blank和尾部不為blank的情況。
程式碼實現:
import numpy as np
from collections import defaultdict
ninf = float("-inf")
# 求每一列(即每個時刻)中最大值對應的softmax值
def softmax(logits):
# 注意這裡求e的次方時,次方數減去max_value其實不影響結果,因為最後可以化簡成教科書上softmax的定義
# 次方數加入減max_value是因為e的x次方與x的極限(x趨於無窮)為無窮,很容易溢位,所以為了計算時不溢位,就加入減max_value項
# 次方數減去max_value後,e的該次方數總是在0到1範圍內。
max_value = np.max(logits, axis=1, keepdims=True)
exp = np.exp(logits - max_value)
exp_sum = np.sum(exp, axis=1, keepdims=True)
dist = exp / exp_sum
return dist
def remove_blank(labels, blank=0):
new_labels = []
# 合併相同的標籤
previous = None
for l in labels:
if l != previous:
new_labels.append(l)
previous = l
# 刪除blank
new_labels = [l for l in new_labels if l != blank]
return new_labels
def insert_blank(labels, blank=0):
new_labels = [blank]
for l in labels:
new_labels += [l, blank]
return new_labels
def _logsumexp(a, b):
'''
np.log(np.exp(a) + np.exp(b))
'''
if a < b:
a, b = b, a
if b == ninf:
return a
else:
return a + np.log(1 + np.exp(b - a))
def logsumexp(*args):
'''
from scipy.special import logsumexp
logsumexp(args)
'''
res = args[0]
for e in args[1:]:
res = _logsumexp(res, e)
return res
def prefix_beam_decode(y, beam_size=10, blank=0):
T, V = y.shape
log_y = np.log(y)
# 最後一個字元是blank與最後一個字元為non-blank兩種情況
beam = [(tuple(), (0, ninf))]
# 對於每一個時刻t
for t in range(T):
# 當我使用普通的字典時,用法一般是dict={},新增元素的只需要dict[element] =value即可,呼叫的時候也是如此
# dict[element] = xxx,但前提是element字典裡,如果不在字典裡就會報錯
# defaultdict的作用是在於,當字典裡的key不存在但被查詢時,返回的不是keyError而是一個預設值
# dict =defaultdict( factory_function)
# 這個factory_function可以是list、set、str等等,作用是當key不存在時,返回的是工廠函式的預設值
# 這裡就是(ninf, ninf)是預設值
new_beam = defaultdict(lambda: (ninf, ninf))
# 對於beam中的每一項
for prefix, (p_b, p_nb) in beam:
for i in range(V):
# beam的每一項都加上時刻t中的每一項
p = log_y[t, i]
# 如果i中的這項是blank
if i == blank:
# 將這項直接加入路徑中
new_p_b, new_p_nb = new_beam[prefix]
new_p_b = logsumexp(new_p_b, p_b + p, p_nb + p)
new_beam[prefix] = (new_p_b, new_p_nb)
continue
# 如果i中的這一項不是blank
else:
end_t = prefix[-1] if prefix else None
# 判斷之前beam項中的最後一個元素和i的元素是不是一樣
new_prefix = prefix + (i,)
new_p_b, new_p_nb = new_beam[new_prefix]
# 如果不一樣,則將i這項加入路徑中
if i != end_t:
new_p_nb = logsumexp(new_p_nb, p_b + p, p_nb + p)
else:
new_p_nb = logsumexp(new_p_nb, p_b + p)
new_beam[new_prefix] = (new_p_b, new_p_nb)
# 如果一樣,保留現有的路徑,但是概率上要加上新的這個i項的概率
if i == end_t:
new_p_b, new_p_nb = new_beam[prefix]
new_p_nb = logsumexp(new_p_nb, p_nb + p)
new_beam[prefix] = (new_p_b, new_p_nb)
# 給新的beam排序並取前beam_size個
beam = sorted(new_beam.items(), key=lambda x: logsumexp(*x[1]), reverse=True)
beam = beam[:beam_size]
return beam
np.random.seed(1111)
y_test = softmax(np.random.random([20, 6]))
beam_test = prefix_beam_decode(y_test, beam_size=100)
for beam_string, beam_score in beam_test[:20]:
print(remove_blank(beam_string), beam_score)執行結果如下:
[1, 5, 4, 1, 3, 4, 5, 2, 3] (-18.189863809114193, -17.613677981426175)
[1, 5, 4, 5, 3, 4, 5, 2, 3] (-18.19636512622969, -17.621013424585406)
[1, 5, 4, 1, 3, 4, 5, 1, 3] (-18.31701896033153, -17.666629973270073)
[1, 5, 4, 5, 3, 4, 5, 1, 3] (-18.323388267369936, -17.674125139073176)
[1, 5, 4, 1, 3, 4, 3, 2, 3] (-18.415808498759556, -17.862744326248826)
[1, 5, 4, 1, 3, 4, 3, 5, 3] (-18.36642276663863, -17.898463479112884)
[1, 5, 4, 5, 3, 4, 3, 2, 3] (-18.42224294936932, -17.870025672291458)
[1, 5, 4, 5, 3, 4, 3, 5, 3] (-18.37219911390019, -17.905130493229173)
[1, 5, 4, 1, 3, 4, 5, 4, 3] (-18.457066311773847, -17.880630315602037)
[1, 5, 4, 5, 3, 4, 5, 4, 3] (-18.462614293487096, -17.88759583852546)
[1, 5, 4, 1, 3, 4, 5, 3, 2] (-18.458941701567706, -17.951422824358747)
[1, 5, 4, 5, 3, 4, 5, 3, 2] (-18.464527031120184, -17.958629487208658)
[1, 5, 4, 1, 3, 4, 3, 1, 3] (-18.540857550725587, -17.92058991009369)
[1, 5, 4, 5, 3, 4, 3, 1, 3] (-18.547146092248852, -17.928030266681613)
[1, 5, 4, 1, 3, 4, 5, 3, 2, 3] (-19.325467801462263, -17.6892032244089)
[1, 5, 4, 5, 3, 4, 5, 3, 2, 3] (-19.328748799764973, -17.694105969982637)
[1, 5, 4, 1, 3, 4, 5, 3, 4] (-18.79699026165903, -17.945090229238392)
[1, 5, 4, 5, 3, 4, 5, 3, 4] (-18.80358553427324, -17.95258394264377)
[1, 5, 4, 3, 4, 3, 5, 2, 3] (-19.18153184608281, -17.859420073785095)
[1, 5, 4, 1, 3, 4, 5, 2, 3, 2] (-19.4393492963852, -17.884502168470895)
Process finished with exit code 0