
《Hadoop3.1》叢集搭建指南
Hadoop3.1 叢集搭建指南
前言
本實驗基於Hadoop3.1 和 jdk1.8安裝,主要涉及內容是linux網路設定,主機設定,ssh遠端登陸設定,
用的作業系統是Centos6.8。
一:LINUX基本配置
步驟:(注:#代表超級使用者下使用)
1 建立單個使用者用於Hadoop叢集搭建
#:useradd username
再鍵入密碼就行了
2 修改sudoers檔案,使在Hadoop下可以使用sudo操作
在root下修改:#:/etc/sudoers 新增如下
3 修改主機名
# vi /etc/sysconfig/network

4 linux網路配置
# vi /etc/sysconfig/network-scripts/ifcfg-eth0

5 修改hosts檔案
# vi /etc/hosts

注:以上都是一臺主機的操作,如果進行叢集需要在hosts檔案新增節點主機IP和主機名
二:安裝JDK
1 解壓jdk
# tar -zxvf jdkname
2 配置環境變數
# vi /etc/profile 新增
export JAVA_HOME=/usr/java/jdk1.8.0_161
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
# source /etc/profile
(溫馨提示:如果你的centos預裝了jdk ,java -version會顯示預裝的版本,例如我安裝的明明是jdk1.8
他顯示1.7的

解決:
檢視安裝的版本
# rpm -qa | grep java

刪除預裝的版本(我的裡預裝的是這兩個)
# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64
# rpm -e --nodeps java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64
再次檢查發現只剩一個了

此時再java -version就會報錯,說沒有該命令

解決:輸入
# source /etc/profile 成功解決。)
三 :安裝hadoop3.1
叢集規劃
| 主機名 | 角色 | IP | 賬戶 | 密碼 | CPU | 記憶體 |
| master | NameNode JobTracker |
192.168.58.131 | root | 111111 | 4vCPU | 12GB |
| slave1 | DataNode TaskTracker |
192.168.58.132 | root | 111111 | 4vCPU | 12GB |
| slave2 | DataNode TaskTracker |
192.168.58.133 | root | 111111 | 4vCPU | 12GB |
1 解壓
# tar -zxvf hadoop-3.1.1.tar.gz
假設解壓的檔案目錄在:/usr/hadoop下
2 修改配置檔案
# vi /usr/hadoop/etc/hadoop/core-site.xml
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:///usr/hadoop/tmp</value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/hdfs-site.xml
| <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///usr/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/hadoop/hdfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>slave1:9001</value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/workers
| slave1 slave2 |
# vi /usr/hadoop/etc/hadoop/mapred-site.xml
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/hadoop/etc/hadoop, /usr/hadoop/share/hadoop/common/*, /usr/hadoop/share/hadoop/common/lib/*, /usr/hadoop/share/hadoop/hdfs/*, /usr/hadoop/share/hadoop/hdfs/lib/*, /usr/hadoop/share/hadoop/mapreduce/*, /usr/hadoop/share/hadoop/mapreduce/lib/*, /usr/hadoop/share/hadoop/yarn/*, /usr/hadoop/share/hadoop/yarn/lib/* </value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/yarn-site.xml
| <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandle</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8040</value> </property> </configuration> |
# vi /usr/hadoop/etc/hadoop/hadoop-env.sh
| export JAVA_HOME=/usr/java/jdk1.8.0_161 # source /opt/hadoop-3.1.0/etc/hadoop/hadoop-env.sh |
# vi /usr/hadoop/etc/hadoop/start-yarn.sh
| export YARN_RESOURCEMANAGER_USER=root export HADOOP_SECURE_DN_USER=root export YARN_NODEMANAGER_USER=root |
# vi /usr/hadoop/etc/hadoop/stop-yarn.sh
| export YARN_RESOURCEMANAGER_USER=root export HADOOP_SECURE_DN_USER=root export YARN_NODEMANAGER_USER=root |
# vi /usr/hadoop/etc/hadoop/start-dfs.sh
| export HDFS_NAMENODE_SECURE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
# vi /usr/hadoop/etc/hadoop/stop-dfs.sh
| export HDFS_NAMENODE_SECURE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root |
3 克隆slave1和slave2
(注:centos6.8克隆後自動分配ip地址,ifconfig檢視ip地址,修改ifcfg-eth0檔案)
①:修改,點選克隆slave1的網路介面卡如下

②:修改內容如下
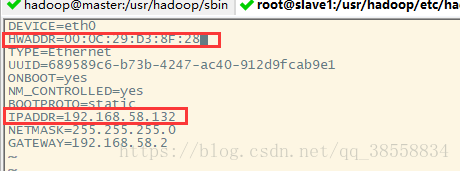
slave2同上。
每個結點都執行
| # vi /etc/profile export HADOOP_HOME=/usr/hadoop export PATH=$PATH:$HADOOP_HOME/bin # source /etc/profile # source /usr/hadoop/etc/hadoop/hadoop-env.sh |
在master結點修改hadoop-env.sh
| # vi /usr/hadoop/etc/hadoop/hadoop-env.sh export HDFS_NAMENODE_SECURE_USER=root export HDFS_DATANODE_SECURE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root # source /usr/hadoop/etc/hadoop/hadoop-env.sh |
4 配置ssh免密登入
在每個主機上都執行:ssh-keygen,提示直接鍵入y和enter
在master結點上執行:
ssh-copy-id 192.168.58.132
ssh-copy-id 192.168.58.132
格式化叢集
hdfs namenode -format
格式化成功

啟動叢集
start-all.sh
如果namenode沒有啟動則輸入:./hadoop-daemon.sh namenode start
jps
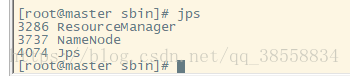
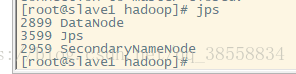
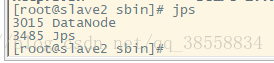
通過網頁訪問:
192.168.58.131:8088/
192.168.58.131:9870/
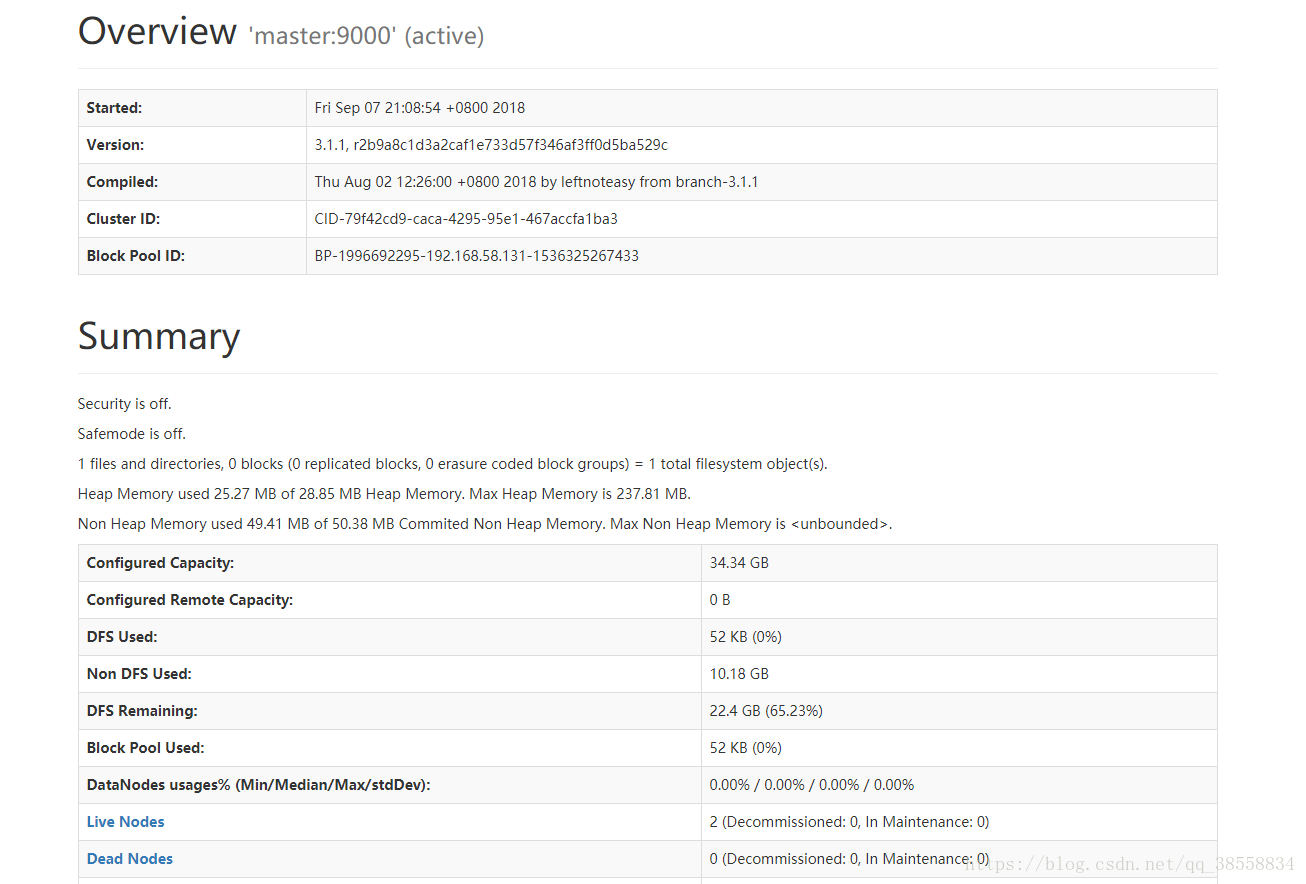
(注意:有的瀏覽器進不去192.168.58.131:9870,例如QQ瀏覽器就不行,也許我沒更新的原因,改用Chrome就好了。)