
hadoop2.8.4+spark2.3.1叢集搭建
1、安裝虛擬機器和linux系統(本文示例Ubuntu16.04 x86_64系統)(此處略過,詳見《安裝linux虛擬機器》)
為了更好使用,記得安裝virtual box的增強功能
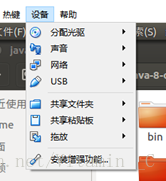
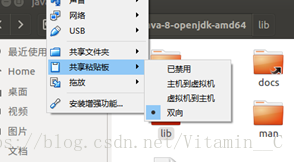
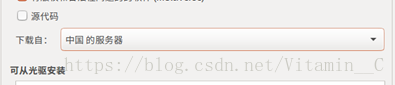
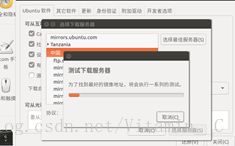
2、選擇軟體和更新,選擇中國軟體源,最優伺服器

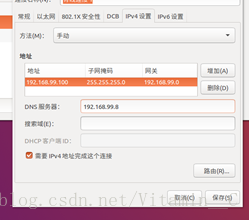
3、固定本地的ip地址
修改如上右圖所示的網路,將其固定稱為區域網固定ip(因為dhcp服務,每次登陸可能ip地址會變動,所以必須將本地ip固定)
因為ip網段給的是192.168.99.0/24,所以我將固定ip地址為 master:192.168.99.100,data1:192.168.99.101,data2:192.168.99.102
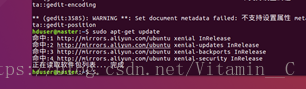
4、修改hosts檔案,新增master 、data1、 data2的本地地址

5、更新apt-get 軟體索引
$sudo apt-get update
6、使用apt-get安裝vim,java,ssh,openssl
$ sudo apt-get install vim
$ sudo apt-get install default-jdk
$ sudo apt-get install ssh
$ sudo apt-get install openssl
7、檢視java版本已經安裝路徑
$ java -version

$ update-alternatives –display java #(檢視安裝路徑)

8、配置ssh免密登入
#生成金鑰檔案
$ ssh-keygen -t rsa -P "" -f~/.ssh/id_rsa
金鑰檔案:/home/hduser/.ssh/id_rsa.pub(注意自己的使用者組名稱)
檢視金鑰檔案
$ ls ~/.ssh/
將產生的key放置到許可證檔案中
$ cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
登入master檢視是否配置成功
$ ssh master
如果不需要密碼登入即為成功(第一次登入需要輸入yes),退出 $ exit
9、下載並安裝hadoop,Scala,spark
注:第一次使用火狐時,需要改主頁,如:www.baidu.com

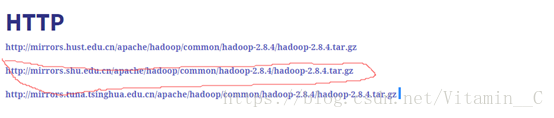
滑鼠右鍵,複製連結地址

滑鼠右鍵,複製連結地址
任選一個滑鼠右鍵,複製當前連結
檢視下載檔案
$ ls ~/
接下來的指令將不細說,百度可查
解壓包
$ tar zxvf hadoop-2.8.4.tar.gz
$ tar xvf scala-2.12.6.tgz
$ tar xvf spark-2.3.1-bin-hadoop2.7.tgz
移動包
$ sudo mv hadoop-2.8.4 /usr/local/hadoop
$ sudo mv spark-2.3.1-bin-hadoop2.7/usr/local/spark
$ sudo mv scala-2.12.6 /usr/local/scala
給/usr/local許可權
$ sudo chown -R hduser:hduser /usr/lcoal
10、修改使用者環境變數和配置檔案
$ vim ~/.bashrc
輸入i 進入插入模式
輸入
#Hadoop Variables
exportJAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPPED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HODOOP_HOME
export CLASSPATH=$CLASSPATH:/usr/local/hadoop/lib/*:.
export YARN_HOME=$HADOOP_HOME
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
exportHADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
exportHADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
#Hadoop Variables
#SCALA Variables
export PATH=${JAVA_HOME}/bin:${PATH}
exportHADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
export PATH=$PATH:$SCALA_HOME/sbin
#SCALA Variables
#SPARK Variables
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
exportSPARK_DIST_CLASSPATH=/usr/local/hadoop/bin/hadoop
exportPYTHONPATH=$SPARK_HOME/python/:$SPARK_HOME/python/lib/py4j-0.10.6-src.zip:$PYTHONPATH
#SPARK Variables
重新整理使用者變數
$ source ~/.bashrc
修改hadoop配置檔案 ,配置檔案目錄/usr/lcoal/hadoop/etc/hadoop
切換目錄
$ cd /usr/local/hadoop
$ cd ./etc/hadoop/
編輯hadoop-env.sh
JAVA_HOME=${JAVA_HOME}>>>>>JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
編輯core-site.xml
<configuration>
<!--配置namenode的地址-->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop執行時產生檔案的儲存目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/tmp</value>
</property>
</configuration>
修改hdfs-site.xml
<!--指定hdfs的副本數-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--設定hdfs的許可權-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!--secondary name node web 監聽埠 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!--name node web 監聽埠 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!--NN所使用的元資料儲存-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<!--存放 edit 檔案-->
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/edits</value>
</property>
<!--secondary namenode 節點儲存 checkpoint 檔案目錄-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/checkpoints</value>
</property>
<!--secondary namenode 節點儲存 edits 檔案目錄-->
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/checkpoints/edits</value>
</property>
</configuration>
datanode節點(data1、data2)設定
<configuration>
<!--指定hdfs的副本數-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--設定hdfs的許可權-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- secondary name node web 監聽埠 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- name node web 監聽埠 -->
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- DN所使用的元資料儲存-->
<property>
<name>dfs.datanode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
<!--存放 edit 檔案-->
<property>
<name>dfs.datanode.edits.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/edits</value>
</property>
</configuration>
配置mapred-site.xml
<configuration>
<!-- 指定mr執行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
</property>
<!--歷史服務的web埠地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<!--歷史服務的埠地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!--Uber執行模式-->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>false</value>
</property>
<!--是job執行時的臨時資料夾-->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>hdfs://master:9000/tmp/hadoop-yarn/staging</value>
<description>The staging dir used while submittingjobs.</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<!--MR JobHistory Server管理的日誌的存放位置-->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>512</value>
<description>每個Map任務的實體記憶體限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
<description>每個Reduce任務的實體記憶體限制</description>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1024</value>
<description>MR ApplicationMaster佔用的記憶體量</description>
</property>
</configuration>
配置slaves
刪除localhost
新增
data1
data2
配置yarn-site.xml
<configuration>
<!-- Site specific YARN configurationproperties -->
<!-- 指定nodeManager元件在哪個機子上跑 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.shuffleHandler</value>
</property>
<!-- 指定resourcemanager元件在哪個機子上跑 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!--resourcemanager web地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<!--啟用日誌聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--在HDFS上聚集的日誌最多儲存多長時間-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<property>
<discription>單個任務可申請最少記憶體,預設1024MB</discription>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>64</value>
</property>
<property>
<discription>單個任務可申請最大記憶體,預設8192MB</discription>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1920</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<discription>每個節點可用記憶體,單位MB</discription>
<value>2048</value>
</property>
<property>
<description>Ratio between virtualmemory to physical memory when
setting memory limits for containers.Container allocations are
expressed in terms of physical memory, andvirtual memory usage
is allowed to exceed this allocation bythis ratio.
</description>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
</configuration>
注:注意鍵值對閉合,以節點1G記憶體,磁碟足夠大配置
修改spark 配置檔案 配置檔案目錄:/usr/local/spark/conf
轉換目錄
cd /usr/local/spark
cd ./conf/
配置spark-env.sh
exportSPARK_DIST_CLASSPATH=/usr/local/hadoop/bin/hadoop
exportJAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
exportHADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_HOME=/usr/local/spark
export SPARK_MASTER_IP=192.168.99.100#注意地址
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_INSTANCES=2
11、複製data1,data2節點
關閉master虛擬機器
複製-> data1->完全複製
複製->data2->完全複製
複製完成後進行網路修改,如之前所示,
將data1的ip改成192.169.99.101
將data1的主機名改成data1
將data2的ip改成192.168.99.102
將data2的主機名改成data2
將data的記憶體設定為1G或者2G
12、格式化namenode
在master節點使用指令
$ hdfs namenode -format
13、啟動hadoop
在master節點輸入
$ start-all.sh
將spark目錄裡jars裡面的jar包上傳到hdfs,並在配置檔案中新增此資訊
$ hadoop dfs -mkdir – p/user/spark_conf/spark_jars/
$ hadoop dfs -put /usr/local/spark/jars/*/user/spark_conf/spark_jars/
在/usr/local/spark/spark-defaults.conf
spark.yarn.archive=hdfs:///user/spark_conf/spark_jars/
14、啟動spark
$ spark-shell --master yarn
或者
$ pyspark --master yarn
15、到此為止,叢集就算搭建完成了,希望大家多多瞭解linux指令和hadoop原理之後再進行程式設計和任務提交執行,這樣更能去理解叢集的工作過程,事半功倍。