
【Youtube機器速成學習筆記】 入門總結
機器學習一些常用概念
什麼是機器學習
用已知資料去預測推算未知事情
標籤
標籤是我們要預測的事物,即簡單線性迴歸中的 y 變數。標籤可以是小麥未來的價格、圖片中顯示的動物品種、音訊剪輯的含義或任何事物。
特徵
特徵是輸入變數,即簡單線性迴歸中的 x 變數。簡單的機器學習專案可能會使用單個特徵,而比較複雜的機器學習專案可能會使用數百萬個特徵,按如下方式指定:
在垃圾郵件檢測器示例中,特徵可能包括:
- 電子郵件文字中的字詞
- 發件人的地址
- 傳送電子郵件的時段
- 電子郵件中包含“一種奇怪的把戲”這樣的短語。
樣本
樣本是指資料的特定例項:x。(我們採用粗體 x 表示它是一個向量。)我們將樣本分為以下兩類:
- 有標籤樣本
- 無標籤樣本
有標籤樣本同時包含特徵和標籤。即:
labeled examples: {features, label}: (x, y)
我們使用有標籤樣本來訓練模型。在我們的垃圾郵件檢測器示例中,有標籤樣本是使用者明確標記為“垃圾郵件”或“非垃圾郵件”的各個電子郵件。
例如,下表顯示了從包含加利福尼亞州房價資訊的資料集中抽取的 5 個有標籤樣本:
| housingMedianAge(特徵) | totalRooms(特徵) | totalBedrooms(特徵) | medianHouseValue(標籤) |
|---|---|---|---|
| 15 | 5612 | 1283 | 66900 |
| 19 | 7650 | 1901 | 80100 |
| 17 | 720 | 174 | 85700 |
| 14 | 1501 | 337 | 73400 |
| 20 | 1454 | 326 | 65500 |
無標籤樣本包含特徵,但不包含標籤。即:
unlabeled examples: {features, ?}: (x, ?)
在使用有標籤樣本訓練了我們的模型之後,我們會使用該模型來預測無標籤樣本的標籤。在垃圾郵件檢測器示例中,無標籤樣本是使用者尚未新增標籤的新電子郵件。
模型
模型定義了特徵與標籤之間的關係。例如,垃圾郵件檢測模型可能會將某些特徵與“垃圾郵件”緊密聯絡起來。我們來重點介紹一下模型生命週期的兩個階段:
訓練表示建立或學習模型。也就是說,您向模型展示有標籤樣本,讓模型逐漸學習特徵與標籤之間的關係。
推斷表示將訓練後的模型應用於無標籤樣本。也就是說,您使用訓練後的模型來做出有用的預測 (
y')。例如,在推斷期間,您可以針對新的無標籤樣本預測medianHouseValue。
迴歸與分類
迴歸模型可預測連續值。例如,迴歸模型做出的預測可回答如下問題:
加利福尼亞州一棟房產的價值是多少?
使用者點選此廣告的概率是多少?
分類模型可預測離散值。例如,分類模型做出的預測可回答如下問題:
某個指定電子郵件是垃圾郵件還是非垃圾郵件?
這是一張狗、貓還是倉鼠圖片?
訓練模型表示通過有標籤樣本來學習(確定)所有權重和偏差的理想值。在監督式學習中,機器學習演算法通過以下方式構建模型:檢查多個樣本並嘗試找出可最大限度地減少損失的模型;這一過程稱為經驗風險最小化。
損失是對糟糕預測的懲罰。也就是說,損失是一個數值,表示對於單個樣本而言模型預測的準確程度。如果模型的預測完全準確,則損失為零,否則損失會較大。訓練模型的目標是從所有樣本中找到一組平均損失“較小”的權重和偏差。例如,圖 3 左側顯示的是損失較大的模型,右側顯示的是損失較小的模型。關於此圖,請注意以下幾點:
- 紅色箭頭表示損失。
- 藍線表示預測。
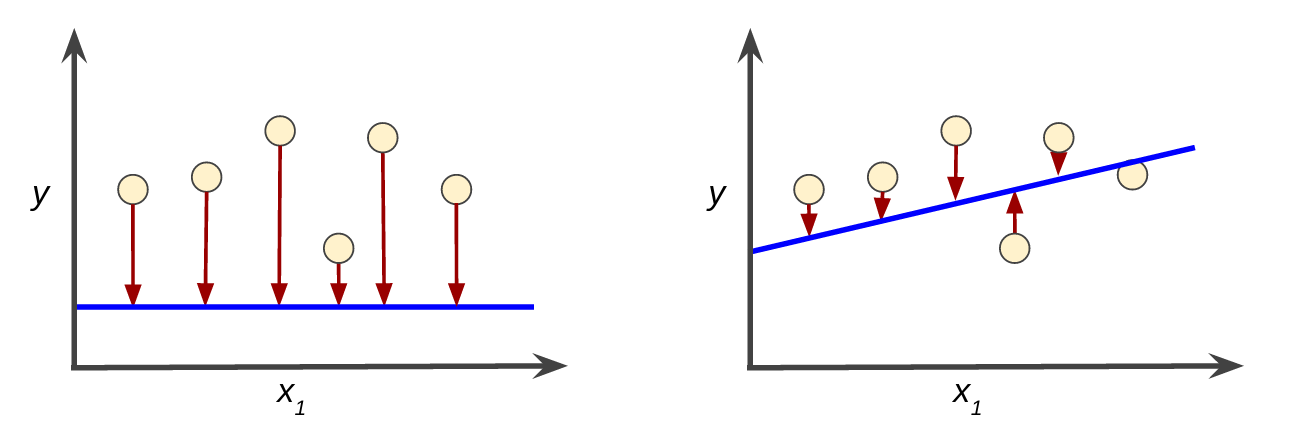
圖 3. 左側模型的損失較大;右側模型的損失較小。
請注意,左側曲線圖中的紅色箭頭比右側曲線圖中的對應紅色箭頭長得多。顯然,相較於左側曲線圖中的藍線,右側曲線圖中的藍線代表的是預測效果更好的模型。
您可能想知道自己能否建立一個數學函式(損失函式),以有意義的方式彙總各個損失。
平方損失:一種常見的損失函式
接下來我們要看的線性迴歸模型使用的是一種稱為平方損失(又稱為 L2 損失)的損失函式。單個樣本的平方損失如下:
= the square of the difference between the label and the prediction = (observation - prediction( x)) 2 = (y - y') 2均方誤差 (MSE) 指的是每個樣本的平均平方損失。要計算 MSE,請求出各個樣本的所有平方損失之和,然後除以樣本數量:
MSE=1N∑(x,y)∈D(y−prediction(x))2其中:
- (x,y) 指的是樣本,其中
- x 指的是模型進行預測時使用的特徵集(例如,溫度、年齡和交配成功率)。
- y 指的是樣本的標籤(例如,每分鐘的鳴叫次數)。
- prediction(x) 指的是權重和偏差與特徵集 x 結合的函式。
- D 指的是包含多個有標籤樣本(即 (x,y))的資料集。
- N 指的是 D 中的樣本數量。
雖然 MSE 常用於機器學習,但它既不是唯一實用的損失函式,也不是適用於所有情形的最佳損失函式。
【簡單一個程式帶你進入機器學習】
例如:給你一些特徵值,讓你預測所屬標籤(猜測蘋果橘子)
機器學習簡單步驟
步驟1:首先去採集資料(採集標籤所具有的特徵值)
步驟2:根據這些資料訓練你的分類器採用決策樹演算法
程式碼如下:
from sklearn import tree
features = [[140,1],[130,1],[150,0],[170,0]]
labels = [0,0,1,1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(features,labels)
print clf.predict([[150,0]])