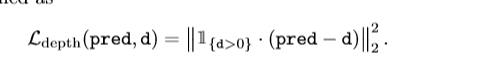Self-Supervised Sparse-to-Dense:Self-Supervised Depth Completion from LiDAR and Monocular Camera
阿新 • • 發佈:2018-12-09
Abstract
深度補全主要面臨的三個挑戰:在稀疏深度輸入中的不規則空間模式,處理多感測器模式的困難,以及缺乏密集畫素級真實深度標籤。在本文中提出了深度迴歸模型學習直接將稀疏深度直接對映到密集深度,同時提出了一個自我監督訓練框架,僅僅顏色序列和稀疏深度影象,不需要稠密深度標籤。
Introduction
本篇文章提出了兩個貢獻:
(1)提出一個網路結構可以學習從稀疏深度(如果彩色影象可以用)直接對映到稠密深度
(2)提出一個自我監督框架用於訓練深度補全網路。
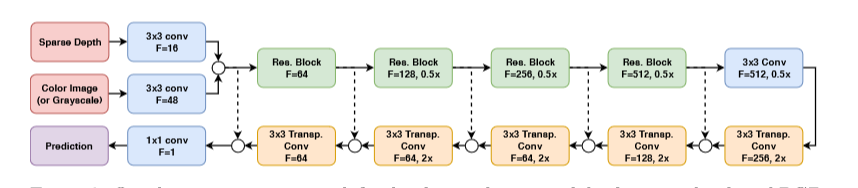
網路結構
將深度補全問題看成一個深度迴歸學習問題
所提出的網路遵循編碼器 - 解碼器範例。
編碼器由一系列卷積組成,這些卷積具有增加的濾波器組以對特徵空間解析度進行下采樣。 另一方面,解碼器具有反轉結構,具有轉置的卷積以對空間解析度進行上取樣
自監督訓練框架
現有的深度補全工作都是基於密集註釋地面真實值來訓練,然而稠密的地面真實值並不存在。
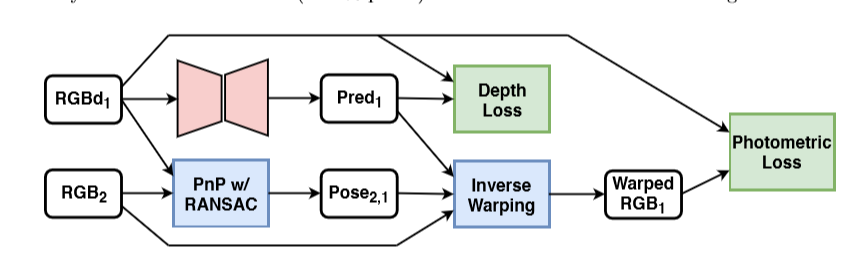 圖2 自監督訓練框架
基於模型的自監督訓練框架,僅需要顏色同步的序列或灰度影象和稀疏深度影象。不需要額外的資訊。
圖2 自監督訓練框架
基於模型的自監督訓練框架,僅需要顏色同步的序列或灰度影象和稀疏深度影象。不需要額外的資訊。
稀疏深度監督
深度損失函式