
CS229 6.12 Neurons Networks from self-taught learning to deep network
self-taught learning 在特徵提取方面完全是用的無監督的方法,對於有標記的資料,可以結合有監督學習來對上述方法得到的引數進行微調,從而得到一個更加準確的引數a。
在self-taught learning中,首先用 無標記資料訓練一個sparse autoencoder,這樣用對於原始輸入x,經過sparse autoencoder得到隱層特徵a:

這樣對於分類問題,目標是預測樣本的類別標號  。現在的標註資料集
。現在的標註資料集 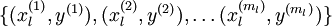 ,包含
,包含 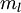 個標註樣本。此前已經說明,可以利用稀疏自編碼器獲得的特徵
個標註樣本。此前已經說明,可以利用稀疏自編碼器獲得的特徵 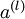 來替代原始特徵。這樣就可獲得訓練資料集
來替代原始特徵。這樣就可獲得訓練資料集 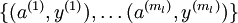
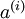 到類標號
到類標號 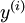 的 logistic 分類器。為說明這一過程,用下圖描述 logistic 迴歸單元(橘黃色)。
的 logistic 分類器。為說明這一過程,用下圖描述 logistic 迴歸單元(橘黃色)。

把上述兩個步驟結合結合起來,便得到:

該模型的引數通過兩個步驟訓練獲得:在該網路的第一層,將輸入  對映至隱藏單元啟用量
對映至隱藏單元啟用量 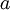 的權值
的權值 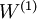 可以通過稀疏自編碼器訓練過程獲得。在第二層,將隱藏單元 對映至輸出 的權值
可以通過稀疏自編碼器訓練過程獲得。在第二層,將隱藏單元 對映至輸出 的權值 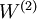 可以通過 logistic 迴歸或 softmax 迴歸訓練獲得。
可以通過 logistic 迴歸或 softmax 迴歸訓練獲得。
這個最終分類器整體上顯然是一個大的神經網路。因此,在訓練獲得模型最初引數(利用自動編碼器訓練第一層,利用 logistic/softmax 迴歸訓練第二層)之後,我們可以進一步修正模型引數,進而降低訓練誤差。具體來說,我們可以對引數進行微調(fun-tuning)
上的訓練誤差。
使用微調時,初始的非監督特徵學習步驟(也就是自動編碼器和logistic分類器訓練)有時候被稱為預訓練。微調的作用在於,已標註資料集也可以用來修正權值 ,這樣可以對隱藏單元所提取的特徵 做進一步調整。
需要注意的是:通常僅在有大量已標註訓練資料的情況下使用微調。在這樣的情況下,微調能顯著提升分類器效能。然而,如果有大量未標註資料集(用於非監督特徵學習/預訓練),卻只有相對較少的已標註訓練集,微調的作用非常有限。
之前所提到的network一般是三層,下面講逐漸考慮多層的網路,通過加深網路層數,我們可以計算更多複雜的輸入特徵。因為每一個隱藏層可以對上一層的輸出進行非線性變換,因此深度神經網路擁有比“淺層”網路更加優異的表達能力(例如可以學習到更加複雜的函式關係)。
注意神經網路應該使用非線性的啟用函式,因為線性啟用函式的表達能力有限,多層線性函式的組合得到的仍然是線性的表達能力,因此啟用函式是線性情況下,加深網路層數然並卵,並不會增加表達能力。
加深網路的優點:
一、網路每加深一層得到的表達能力將是之前的指數倍,比如說用k層神經網路能學習到的函式(且每層網路節點個數時多項式的)如果要用k-1層神經網路來學習,則這k-1層神經網路節點的個數必須是k的指數倍的龐大數字。
二、不同層的網路學習到的特徵是由最底層到最高層慢慢上升的。比如在影象的學習中,第一個隱含層層網路可能學習的是邊緣特徵,第二隱含層就學習到的是輪廓,後面的就會更高階有可能是影象目標中的一個部位,也就是是底層隱含層學習底層特徵,高層隱含層學習高層特徵。
之前研究者們主要使用的學習演算法是:隨機初始化深度網路的權重,然後使用有監督的目標函式在有標籤的訓練集 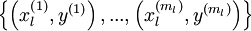 上進行訓練。
上進行訓練。
這樣有一些缺點:
一、資料獲取問題,使用上面提到的方法,我們需要依賴於有標籤的資料才能進行訓練。然而有標籤的資料通常是稀缺的,因此對於許多問題,我們很難獲得足夠多的樣本來擬合一個複雜模型的引數。例如,考慮到深度網路具有強大的表達能力,在不充足的資料上進行訓練將會導致過擬合
二、使用監督學習方法來對淺層網路(只有一個隱藏層)進行訓練通常能夠使引數收斂到合理的範圍內。但是當用這種方法來訓練深度網路的時候,並不能取得很好的效果。比如使用監督學習方法訓練神經網路時,通常會涉及到求解一個高度非凸的優化問題(例如最小化訓練誤差 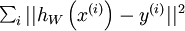 ,其中引數
,其中引數 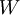 是要優化的引數。對深度網路而言,這種非凸優化問題的搜尋區域中充斥著大量“壞”的區域性極值,因而使用梯度下降法(或者像共軛梯度下降法,L-BFGS等方法)效果並不好。
是要優化的引數。對深度網路而言,這種非凸優化問題的搜尋區域中充斥著大量“壞”的區域性極值,因而使用梯度下降法(或者像共軛梯度下降法,L-BFGS等方法)效果並不好。
三、梯度擴散(gradient diffuse),梯度下降法(以及相關的L-BFGS演算法等)在使用隨機初始化權重的深度網路上效果不好的技術原因是:梯度會變得非常小,當使用反向傳播方法計算導數的時候,隨著網路的深度的增加,反向傳播的梯度(從輸出層到網路的最初幾層)的幅度值會急劇地減小。結果就造成了整體的損失函式相對於最初幾層的權重的導數非常小。這樣,當使用梯度下降法的時候,最初幾層的權重變化非常緩慢,以至於它們不能夠從樣本中進行有效的學習。這種問題通常被稱為“gradient diffuse”.
梯度擴散導致的問題是:當神經網路中的最後幾層含有足夠數量神經元的時候,可能單獨這幾層就足以對有標籤資料進行建模,而不用最初幾層的幫助。因此,對所有層都使用隨機初始化的方法訓練得到的整個網路的效能將會與訓練得到的淺層網路(僅由深度網路的最後幾層組成的淺層網路)的效能相似。
最後補充下,現在隨著深度學習的發展,pre-training 變得不再那麼重要,因為學者們發現只要資料量足夠多,最後深度學習都能給出一個較優的解,並且一些非全連線網路比如LSTM或者CNN等也很難進行pre-training。