
k近鄰演算法(k-nearest neighbor)和python 實現
阿新 • • 發佈:2018-12-09
1、k近鄰演算法
k近鄰學習是一種常見的監督學習方法,其工作機制非常簡單:給定測試樣本,基於某種距離度量找出訓練集中與其最靠近的k個訓練樣本,然後基於這K個"鄰居"的資訊來進行預測。
通常,在分類任務中可使用"投票法",即選擇這K個樣本中出現最多的類別標記作為預測結果;在迴歸任務中可使用"平均法”,即將這K個樣本的實際值輸出標記的平均值作為預測結果,還可以基於距離遠近進行加權平均或加權投票。距離越近的樣本權重越大。
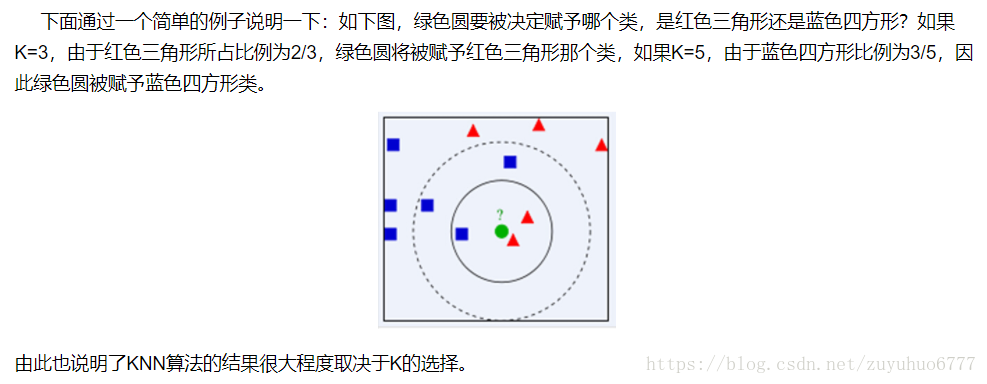

同時,KNN通過依據k個物件中佔優的類別進行決策,而不是單一的物件類別決策。這兩點就是KNN演算法的優勢。
接下來對KNN演算法的思想總結一下:就是在訓練集中資料和標籤已知的情況下,輸入測試資料,將測試資料的特徵與訓練集中對應的特徵進行相互比較,找到訓練集中與之最為相似的前K個數據,則該測試資料對應的類別就是K個數據中出現次數最多的那個分類,其演算法的描述為:
1)計算測試資料與各個訓練資料之間的距離;
2)按照距離的遞增關係進行排序;
3)選取距離最小的K個點;
4)確定前K個點所在類別的出現頻率;
5)返回前K個點中出現頻率最高的類別作為測試資料的預測分類。
二、python 實現
from __future__ import print_function from sklearn import datasets from sklearn.cross_validation import train_test_split from sklearn.neighbors import KNeighborsClassifier iris = datasets.load_iris() iris_X = iris.data iris_y = iris.target #print(iris_X[:2, :]) #print(iris_y) X_train, X_test, y_train, y_test = train_test_split( iris_X, iris_y, test_size=0.3) knn = KNeighborsClassifier() knn.fit(X_train, y_train) #訓練 #print(knn.predict(X_test)) #print(y_test) a=knn.score(X_test,y_test) print(a)
執行結果是:a=0.9777
3、KNN演算法中超引數的搜尋
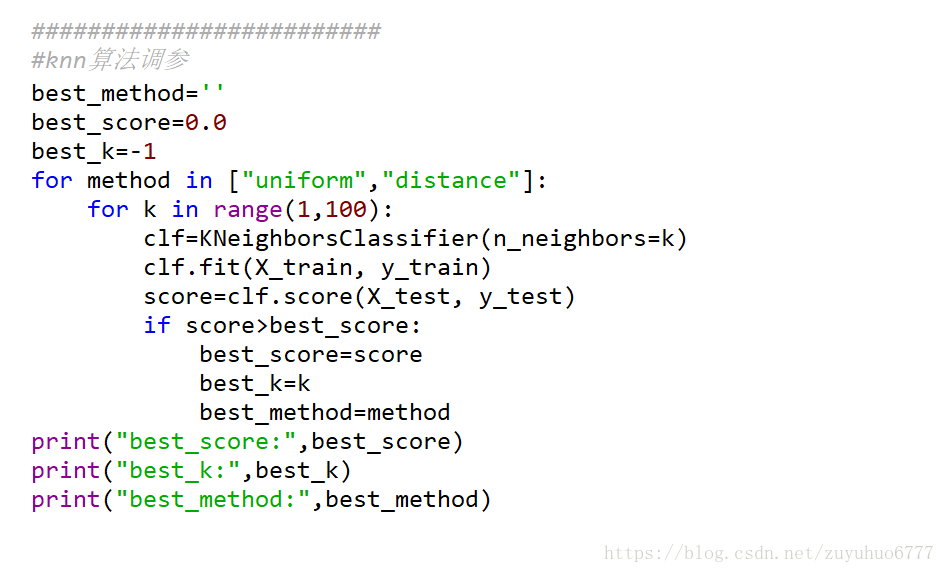
補充1:
為了進一步理解knn演算法的本質,用python 將其實現了一下,而不僅僅是在sklearn包中呼叫
from sklearn.neighbors import KNeighborsClassifer
knn=KNeighborsClassifer來實現。
Python程式碼如下,且有解釋:
from numpy import * import operator def createDataSet(): group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels=['A','A','B','B'] return group,labels #from sklearn.neighbors import KNeighborsClassifer #knn=KNeighborsClassifer def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0]#行 diffMat = tile(inX, (dataSetSize,1)) - dataSet#dataSetSize*1 sqDiffMat = diffMat**2#平方 sqDistances = sqDiffMat.sum(axis=1)#x軸方向求和 distances = sqDistances**0.5#開根號 sortedDistIndicies = distances.argsort()#從小到大排序,返回索引值 classCount={} for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #返回指定鍵值,none返回0,value為出現的個數 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) #dict.items() :以列表返回可遍歷的(鍵、值)元組陣列 #key=operator.itemgetter(1) 以第二個數字排序 #reverse=True 相反的方向 return sortedClassCount[0][0]
之後再輸入:
group,labels=createDataSet();
print(classify0([0,0],group,labels,3))
預測成功,完成分類
有問題,歡迎留言,一起討論。