
k最近鄰演算法(K-Nearest Neighbor)理解與python實現
阿新 • • 發佈:2019-02-13
numpy 模組參考教程:http://old.sebug.net/paper/books/scipydoc/index.html
一:什麼是KNN演算法?
kNN演算法全稱是k-最近鄰演算法(K-Nearest Neighbor)
kNN演算法的核心思想是如果一個樣本在特徵空間中的k個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的特性。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
下邊舉例說明:
使用方法:進入kNN.py檔案所在的目錄,輸入Python,依次輸入
import kNN
group,labels = kNN.createDataSet()
kNN.classify0([0,0],group,lables,3)
一:什麼是KNN演算法?
kNN演算法全稱是k-最近鄰演算法(K-Nearest Neighbor)
kNN演算法的核心思想是如果一個樣本在特徵空間中的k個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的特性。該方法在確定分類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
下邊舉例說明:
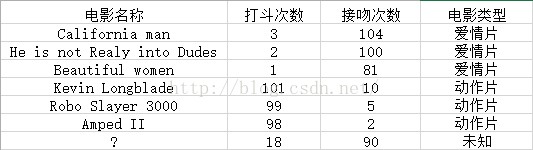
即使不知道未知電影屬於哪種型別,我們也可以通過某種方法計算出來,如下圖

現在我們得到了樣本集中與未知電影的距離,按照距離的遞增順序,可以找到k個距離最近的電影,假定k=3,則三個最靠近的電影是和he is not realy into Dudes,Beautiful women, California man kNN演算法按照距離最近的三部電影型別決定未知電影型別,這三部都是愛情片,所以未知電影的型別也為愛情片
二:KNN演算法的一般流程
step.1---初始化距離為最大值
step.2---計算未知樣本和每個訓練樣本的距離
step.3---得到目前K個最臨近樣本中的最大距離maxdist
step.4---如果dist小於maxdist,則將該訓練樣本作為K-最近鄰樣本
step.5---重複步驟2、3、4,直到未知樣本和所有訓練樣本的距離都算完
step.6---統計K-最近鄰樣本中每個類標號出現的次數
step.7---選擇出現頻率最大的類標號作為未知樣本的類標號
三、KNN演算法的Python程式碼實現
#encoding:utf-8 from numpy import * import operator def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group,labels def classify0(inX,dataSet,labels,k): #返回“陣列”的行數,如果shape[1]返回的則是陣列的列數 dataSetSize = dataSet.shape[0] #兩個“陣列”相減,得到新的陣列 diffMat = tile(inX,(dataSetSize,1))- dataSet #求平方 sqDiffMat = diffMat **2 #求和,返回的是一維陣列 sqDistances = sqDiffMat.sum(axis=1) #開方,即測試點到其餘各個點的距離 distances = sqDistances **0.5 #排序,返回值是原陣列從小到大排序的下標值 sortedDistIndicies = distances.argsort() #定義一個空的字典 classCount = {} for i in range(k): #返回距離最近的k個點所對應的標籤值 voteIlabel = labels[sortedDistIndicies[i]] #存放到字典中 classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 #排序 classCount.iteritems() 輸出鍵值對 key代表排序的關鍵字 True代表降序 sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True) #返回距離最小的點對應的標籤 return sortedClassCount[0][0]
使用方法:進入kNN.py檔案所在的目錄,輸入Python,依次輸入
import kNN
group,labels = kNN.createDataSet()
kNN.classify0([0,0],group,lables,3)
在實際使用中,有幾個問題是值得注意的:
1、K值的選取,選多大合適呢?
2、計算兩者間距離,用哪種距離會更好呢(歐幾里得距離等等幾個)?
3、計算量太大怎麼辦?
4、假設樣本中,型別分佈非常不均,比如動作片電影有200部,但是愛情片電影只有20部,這樣計算起來,即使不是動作片電影,也會因為動作片樣本太多,導致k個最近鄰居里有不少動作片電影,這樣該怎麼辦呢?
沒有萬能的演算法模型,只有最優的演算法,要懂得合適利用演算法。