
效能監控之JMeter分散式壓測輕量日誌解決方案
文章目錄
引言
在前文中我們已經介紹了使用JMeter非GUI模式進行壓測的時候,我們可以使用InfluxDB+Grafana進行實時效能測試結果監控,也可以用
並不是所有的HTTP請求失敗都是500引起的,有時候也可能是200,響應斷言只是檢查響應資料是否存在給定的字串,如果不滿足那麼就是請求失敗。但是這段時間我們實際的響應資料是什麼?要知道在效能測試期間除錯應用可是非常重要的。 我們經常使用阿里雲或者物理機叢集來壓測,即使我們將響應資料記錄在日誌裡面,我們也可能無法立即獲取資料。我們只能等待壓測結束去ssh/ftp訪問主機去檢查日誌。我們不能像效能測試結果一樣使用InfluxDB收集這些大量的非結構文字資料。因為InfluxDB作為時序資料庫並不是為檢索文字設計的。
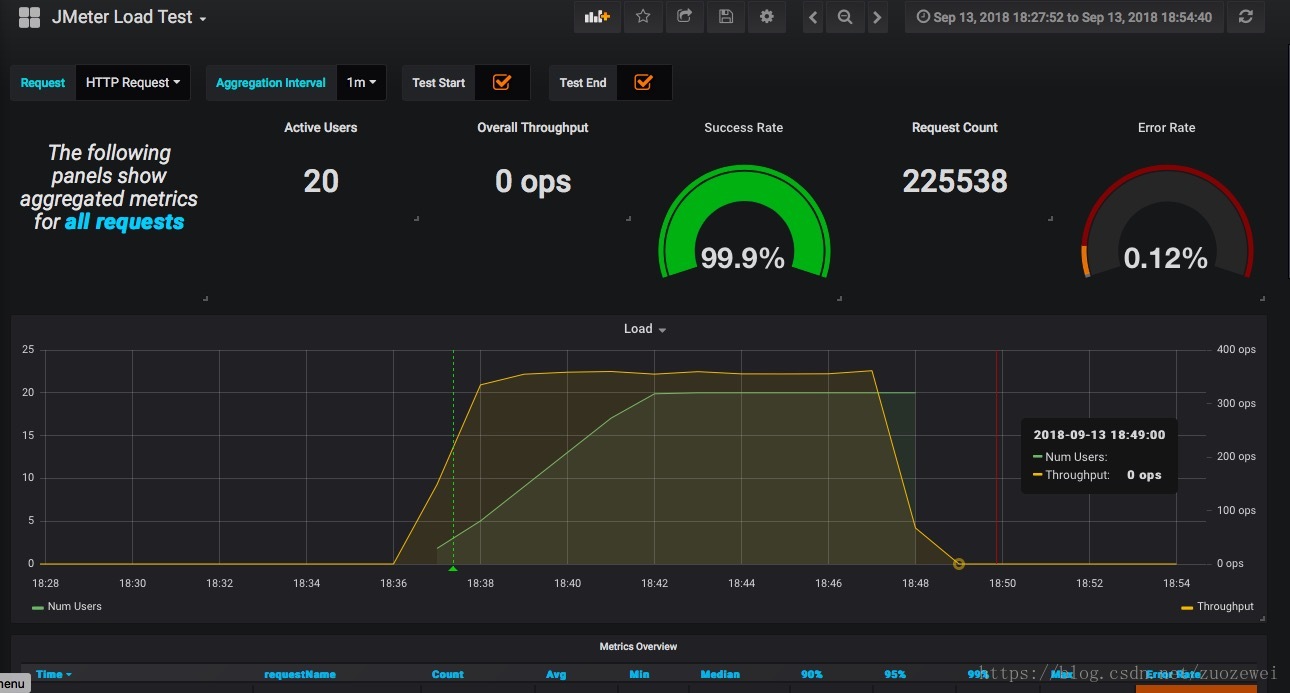
其中一個簡單的輕量日誌解決方案就是使用ElasticSearch+FileBeats+Kibana去收集分析錯誤響應資料。
背景
Filebeat
Filebeat是ELK協議棧的新成員,一個輕量級開源日誌檔案資料蒐集器,用GO語言實現。 Filebeat安裝在伺服器上做為代理監視日誌目錄或者特定的日誌檔案,要麼將日誌轉發到Logstash進行解析,要麼直接傳送到ElasticSearch進行索引。 Filebeat文件完善,配置簡單,天然支援ELK,為Apache,Nginx,System,MySQL等服務產生的日誌提供預設配置,採集,分析和展示一條龍。
如下所示,Filebeat的配置簡單易懂
filebeat:
spool_size: 1024 # 最大可以攢夠 1024 條資料一起傳送出去
idle_timeout: "5s" # 否則每 5 秒鐘也得傳送一次
registry_file: "registry" # 檔案讀取位置記錄檔案,會放在當前工作目錄下。
config_dir: "path/to/configs/contains/many/yaml" # 如果配置過長,可以通過目錄載入方式拆分配置
prospectors: # 有相同配置引數的可以歸類為一個 prospector
-
fields:
log_source: "sample" # 類似logstash的 add_fields,此處的"log_source"用來標識該日誌來源於哪個專案
paths:
- /var/log/system.log # 指明讀取檔案的位置
- /var/log/wifi.log
include_lines: ["^ERR", "^WARN"] # 只發送包含這些字樣的日誌
exclude_lines: ["^OK"] # 不傳送包含這些字樣的日誌
-
document_type: "apache" # 定義寫入ES時的 _type 值
ignore_older: "24h" # 超過24小時沒更新內容的檔案不再監聽。
scan_frequency: "10s" # 每10秒鐘掃描一次目錄,更新萬用字元匹配上的檔案列表
tail_files: false # 是否從檔案末尾開始讀取
harvester_buffer_size: 16384 # 實際讀取檔案時,每次讀取16384位元組
backoff: "1s" # 每1秒檢測一次檔案是否有新的一行內容需要讀取
paths:
- "/var/log/apache/*" # 可以使用萬用字元
exclude_files: ["/var/log/apache/error.log"]
-
input_type: "stdin" # 除了 "log",還有 "stdin"
multiline: # 多行合併
pattern: '^[[:space:]]'
negate: false
match: after
output.elasticsearch:
hosts: ["127.0.0.1:9200"] # The elasticsearch host
Filebeat 傳送的日誌,會包含以下欄位:
- beat.hostname:beat執行的主機名
- beat.name:shipper配置段設定的name,如果沒設定,等於beat.hostname
- @timestamp:讀取到該行內容的時間
- type 通過:document_type設定的內容
- input_type:來自"log"還是"stdin"
- source:具體的檔名全路徑
- offset:該行日誌的起始偏移量
- message:日誌內容
- fields:新增的其他固定欄位都存在這個物件裡面
Elasticsearch
Elasticsearch是一個開源的高擴充套件的分散式全文檢索引擎,它可以近乎實時的儲存、檢索資料;本身擴充套件性很好,可以擴充套件到上百臺伺服器。Elasticsearch強在全文搜尋,InfluxDB擅長時序資料,所以還是具體需求具體分析。如果需要儲存日誌並經常查詢的,Elasticsearch比較合適,比如我們的JMeter log。如果只依賴日誌做狀態展示,偶爾查詢,InfluxDB比較合適。
Kibana
Kibana 是一個開源的分析和視覺化平臺,旨在與 Elasticsearch 合作。Kibana 提供搜尋、檢視和與儲存在 Elasticsearch 索引中的資料進行互動的功能。使用者可以輕鬆地執行高階資料分析,並在各種圖表、表格和地圖中視覺化資料。Fibana在圖表展示上沒有Grafana美觀,但Kibana從Elasticsearch中檢索日誌非常方便。
整體架構
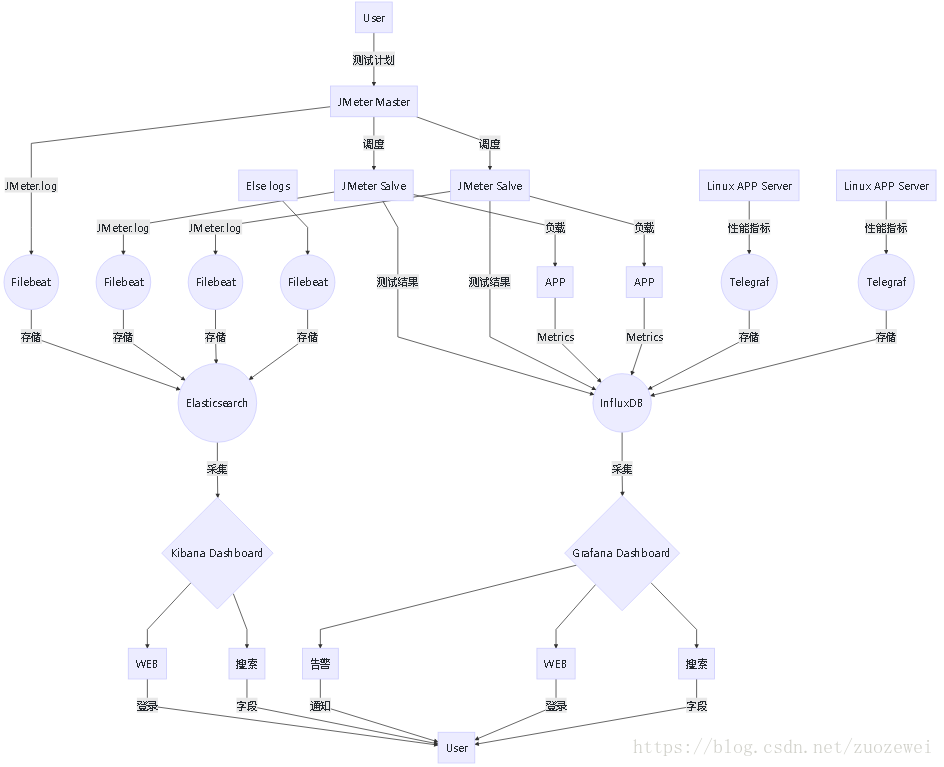
日誌採集架構
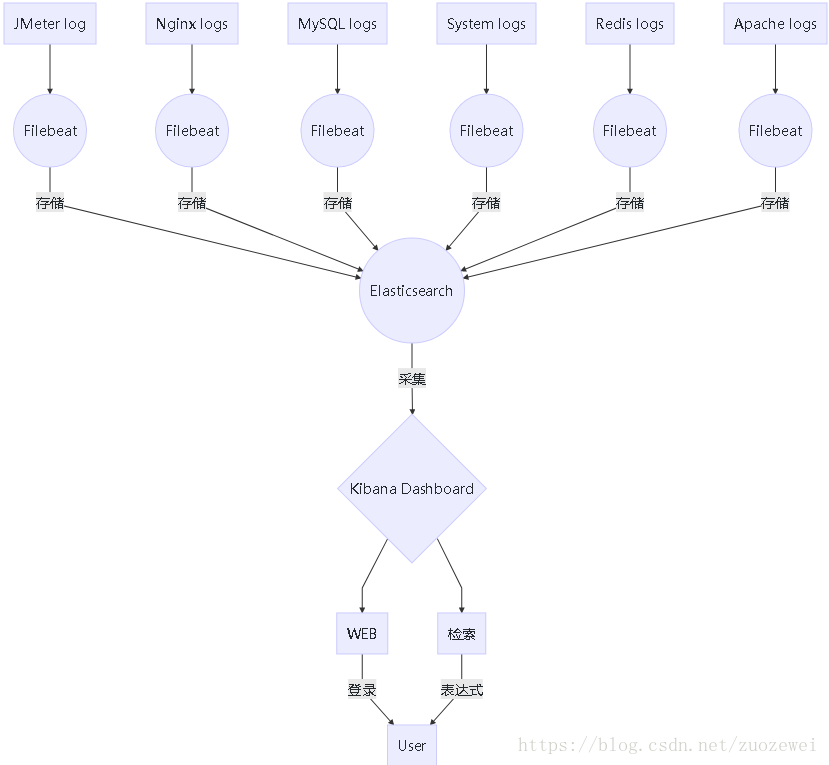
安裝及配置
下載及配置ElasticSearch
可以直接參考官網的教程,此處就不重複造輪子了
官網教程地址:https://www.elastic.co/downloads/elasticsearch
安裝完成後,確認可以通過使用http://elasticsearch-host-ip:9200訪問elasticsearch
下載及配置Kibana
參考官網教程: https://www.elastic.co/downloads/kibana
更新 config/kibana.yml配置檔案以獲取elasticsearch資料
執行kibana.bat/.sh確保可以使用http://kibana-host-ip:5601訪問kibana主頁
下載及配置FileBeat
參考官網教程 https://www.elastic.co/downloads/beats/filebeat
我們需要為每個壓力機部署一個FileBeat節點,FileBeat主要負責收集日誌資料,併發送給elasticsearch儲存。
更新filebeat.yml檔案
filebeat.inputs:
- type: log
enabled: true
paths:
- D:\BaiduNetdiskDownload\jmeter\apache-jmeter-4.0\bin\jmeter.log
multiline.pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2}
multiline.negate: true
multiline.match: after
output.elasticsearch:
hosts: ["127.0.0.1:9200"]
預設情況下,FileBeat將日誌檔案中的每一行記錄為單獨的日誌條目。有時JMeter異常可能跨越多行。所以我們需要使用多行模式配置filebeat.yml。
JMeter.log每個日誌條目都帶有其時間戳(yyyy-MM-dd)。所以,我們可以將模式配置為從時間戳開始擷取,如果沒有時間戳,FileBeat可以根據配置將該行附加到上一行。
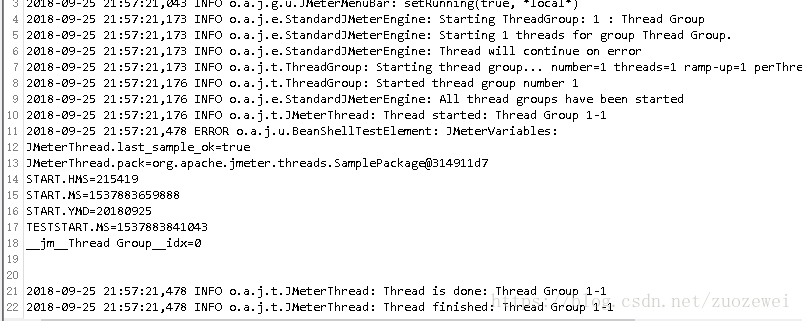
啟動FileBeat後將開始監視日誌檔案,每當更新日誌檔案時,資料將被髮送到ElasticSearch儲存。
JMeter日誌採集
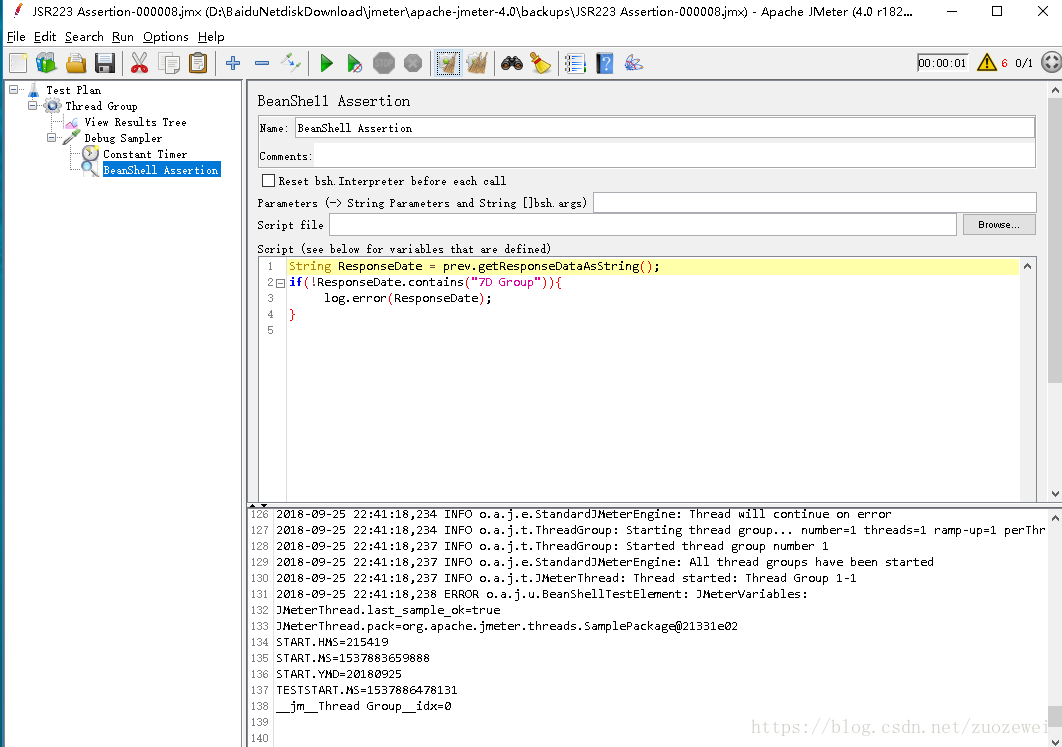
我們建立了一個非常簡單的測試,如下所示,只有有Debug Sampler,使用BeanShell Assertion監聽在發生任何錯誤時在日誌檔案中寫入返回資料。
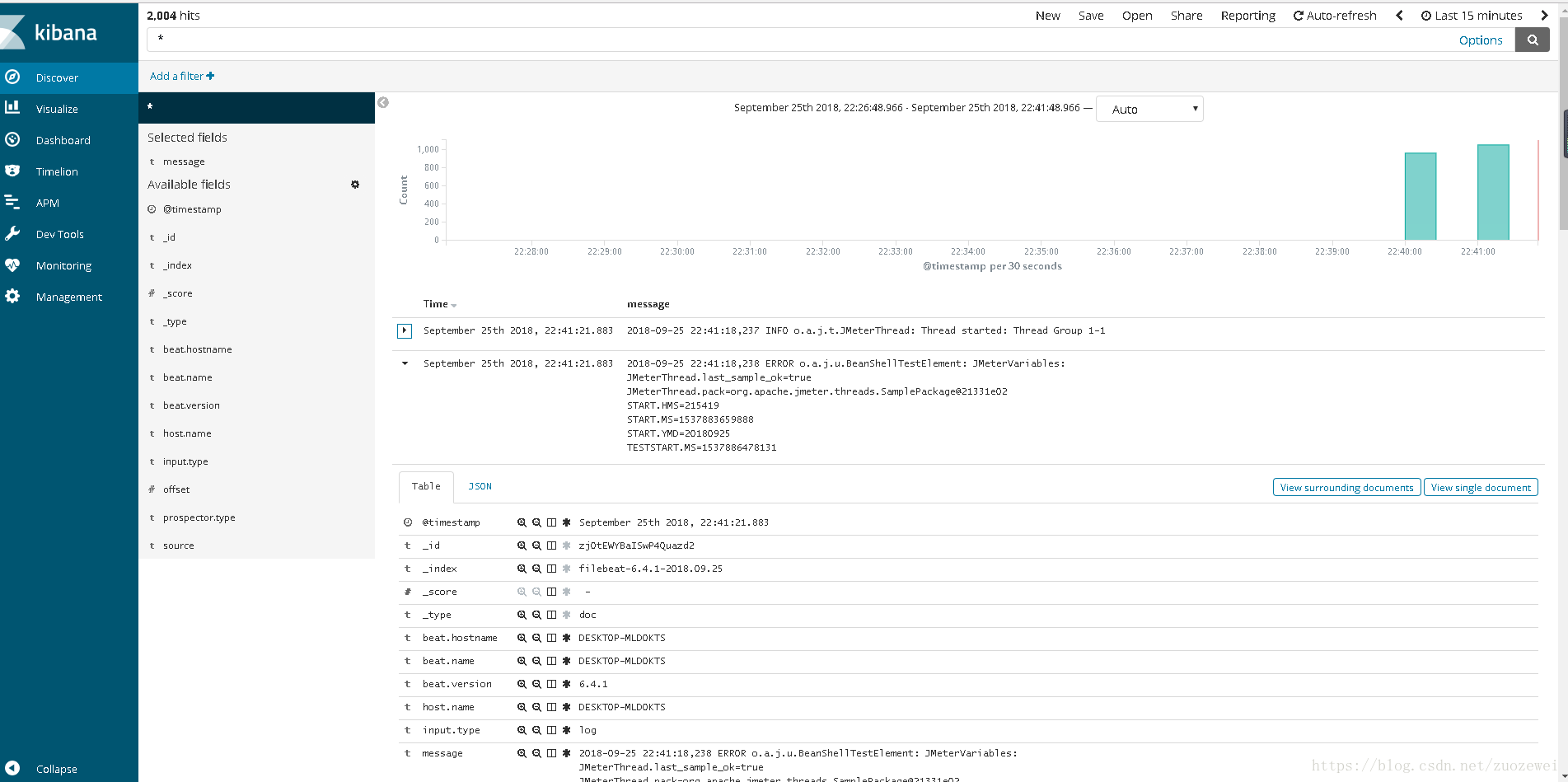
壓測開始後,FileBeat將開始收集從日誌檔案中的資訊,並轉發到ElasticSearch儲存,我們可以通過Kibana檢索詳細日誌。
如果我們點選小箭頭展開細節,下面的訊息部分將顯示我們感興趣的日誌詳細內容。

小結
除了實時效能測試結果和實時效能資料外,我們還能夠實時收集失敗請求的響應資料。當我們在長時間執行的分散式負載測試時,上述設定非常有用。當請求事務突然失敗時,此設定可幫助我們檢查響應資料以便了解應用的情況和測試工具行為。
本文只拋磚引玉,大家有興趣的話,可以參照教程深入實踐。