
遷移學習演算法之TrAdaBoost
1.問題定義
傳統的機器學習的模型都是建立在訓練資料和測試資料服從相同的資料分佈的基礎上。典型的比如有監督學習,我們可以在訓練資料上面訓練得到一個分類器,用於測試資料。但是在許多的情況下,這種同分布的假設並不滿足,有時候我們的訓練資料會過期,而重新去標註新的資料又是十分昂貴的。這個時候如果丟棄訓練資料又是十分可惜的,所以我們就想利用這些不同分佈的訓練資料,訓練出一個分類器,在我們的測試資料上可以取得不錯的分類效果。
定義問題模型如下:設為源樣例空間,
為輔助樣例空間。源樣例空間也就是我們的目標空間,就是想要去分類的樣例空間。設Y={0,1}為類別空間,這裡簡化了多分類問題為二分類問題討論,這樣我們的訓練資料也就是
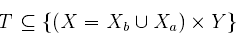
測試資料:
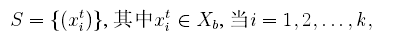
其中測試資料是未標註的,我們可以將訓練資料劃分為兩個資料集:
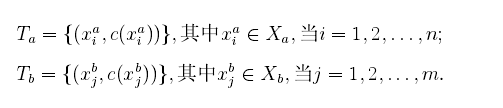
其中代表樣本資料x的真實所屬的類別,
和
的區別在於
和測試資料S是同分布的,
和測試資料是不同分佈的,現在的任務就是給定很少的源資料
和大量的輔助資料
訓練出一個分類器在測試資料S上的分類誤差最小。這裡假設利用已有的資料
不足以訓練出一個泛化能力很強的分類器。
2.TrAdaBoost演算法
我們利用AdaBoost演算法的思想原理來解決這個問題,起初給訓練資料T中的每一個樣例都賦予一個權重,當一個源域中的樣本被錯誤的分類之後,我們認為這個樣本是很難分類的,於是乎可以加大這個樣本的權重,這樣在下一次的訓練中這個樣本所佔的比重就更大了,這一點和基本的AdaBoost演算法的思想是一樣的。如果輔助資料集中的一個樣本被錯誤的分類了,我們認為這個樣本對於目標資料是很不同的,我們就降低這個資料在樣本中所佔的權重,降低這個樣本在分類器中所佔的比重,下面給出TradaBoost演算法的具體流程:


可以看到,在每一輪的迭代中,如果一個輔助訓練資料被誤分類,那麼這個資料可能和源訓練資料是矛盾的,那麼我們就可以降低這個資料的權重。具體來說,就是給資料乘上一個,其中
的值在0到1之間,所以在下一輪的迭代中,被誤分類的樣本就會比上一輪少影響分類模型一些,在若干次以後,輔助資料中符合源資料的那些資料會擁有更高的權重,而那些不符合源資料的權重會降低。極端的一個情況就是,輔助資料被全部忽略,訓練資料就是源資料Tb,這樣這時候的演算法就成了AdaBoost演算法了。在計算錯誤率的時候,當計算得到的錯誤率大於0.5的話,需要將其重置為0.5。
可以看到,TrAdaBoost演算法在源資料和輔助資料具有很多的相似性的時候可以取得很好效果,但是演算法也有不足,當開始的時候輔助資料中的樣本如果噪聲比較多,迭代次數控制的不好,這樣都會加大訓練分類器的難度。