
ElasticSearch概述及Linux下的單機ElasticSearch安裝
這兩天在專案中要涉及到ElasticSearch的使用,就上網去搜索了一些這方面的資料,發現elasticSearch的安裝分為單機和叢集兩種方式。在本例中,我們重點介紹單機下的ElasticSearch的安裝,親測可用,記錄下來與各位同仁分享。
一、ElasticSearch概述
ElasticSearch是一個基於Lucene的搜尋伺服器。它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。Elasticsearch是用Java開發的,並作為Apache許可條款下的開放原始碼釋出,是當前流行的企業級搜尋引擎。設計用於雲端計算中,能夠達到實時搜尋,穩定,可靠,快速,安裝使用方便。
我們建立一個網站或應用程式,並要新增搜尋功能,令我們受打擊的是:搜尋工作是很難的。我們希望我們的搜尋解決方案要快,我們希望有一個零配置和一個完全免費的搜尋模式,我們希望能夠簡單地使用JSON通過HTTP的索引資料,我們希望我們的搜尋伺服器始終可用,我們希望能夠一臺開始並擴充套件到數百,我們要實時搜尋,我們要簡單的多租戶,我們希望建立一個雲的解決方案。Elasticsearch旨在解決所有這些問題和更多的問題。【百度百科】
幾個重要的核心概念
1、接近實時
ElasticSearch是一個接近實時的搜尋平臺,這就是說,從索引這個文件到這個文件能夠被搜尋到有一個輕微的延遲。
2、叢集和節點
一個叢集就是由一個或者多個節點組織在一起,它們共同的持有你整個的資料,通俗的來說就是一個或者多個伺服器,即組成叢集,而每個獨立的伺服器即是一個節點,一般在叢集中會有一個主節點,剩下的即為從節點,主節點和從節點共同負責參與資料的儲存和管理。
3、索引(index)
一個索引就是一個擁有幾分相似特徵的文件的集合。舉個例子,相信各位肯定有過在圖書館找書的經歷,每本書上都會貼著一個索引,而我們可以將每本書中的每一頁看作是文件,這樣的話看,索引就是一系列文件的集合。一個索引由一個名字來標識,並且當我們要對對應於這個索引中的文件進行索引,進行搜尋、更新和刪除的時候,都會用到這個名字。當然了,在叢集中,你可以根據自己的想法定義任意多的索引。
4、型別(type)
在一個索引中,你可以定義一種或者多種型別。一個型別是一個索引的一個邏輯上的分類/分割槽,其語義完全由你來定。通常來說,會為具有一組共同欄位的文件定義一個型別。再拿上述的例子,我們可以將書中的文字定義為一個數據型別,而為書中的資料定義為另外一個數據型別。
5、文件(document)
一個文件是一個可被索引的基礎資訊單元。文件是以JSON格式來表示,而JSON是一個到處存在的網際網路資料互動格式。
6、分片和複製
一個索引可以儲存超出單個結點硬體限制的大量資料。比如,一個具有10億文件的索引佔據1TB的磁碟空間,而任一節點都沒有這樣大的磁碟空間;或者單個節點處理搜尋請求,響應太慢。
為了解決這個問題,Elasticsearch提供了將索引劃分成多份的能力,這些份就叫做分片。當你建立一個索引的時候,你可以指定你想要的分片的數量。每個分片本身也是一個功能完善並且獨立的“索引”,這個“索引”可以被放置到叢集中的任何節點上。
分片的重要性的原因:
允許你水平分割/擴充套件你的內容容量
允許你在分片(潛在地,位於多個節點上)之上進行分散式的、並行的操作,進而提高效能/吞吐量
在一個網路/雲的環境裡,失敗隨時都可能發生,在某個分片/節點不知怎麼的就處於離線狀態,或者由於任何原因消失了,這種情況下,有一個故障轉移機制是非常有用並且是強烈推薦的。為此目的,Elasticsearch允許你建立分片的一份或多份拷貝,這些拷貝叫做複製分片,或者直接叫複製。
複製的重要性的原因:
在分片/節點失敗的情況下,提供了高可用性。因為這個原因,注意到複製分片從不與原/主要(original/primary)分片置於同一節點上是非常重要的。
擴充套件你的搜尋量/吞吐量,因為搜尋可以在所有的複製上並行執行
總之,每個索引可以被分成多個分片。一個索引也可以被複制0次(意思是沒有複製)或多次。一旦複製了,每個索引就有了主分片(作為複製源的原來的分片)和複製分片(主分片的拷貝)之別。分片和複製的數量可以在索引建立的時候指定。在索引建立之後,你可以在任何時候動態地改變複製的數量,但是你事後不能改變分片的數量。
預設情況下,Elasticsearch中的每個索引被分片5個主分片和1個複製,這意味著,如果你的叢集中至少有兩個節點,你的索引將會有5個主分片和另外5個複製分片(1個完全拷貝),這樣的話每個索引總共就有10個分片。
二、Linux下的單機ElasticSearch安裝
準備工作:
作業系統:Centos 7 IP:192.168..18.228
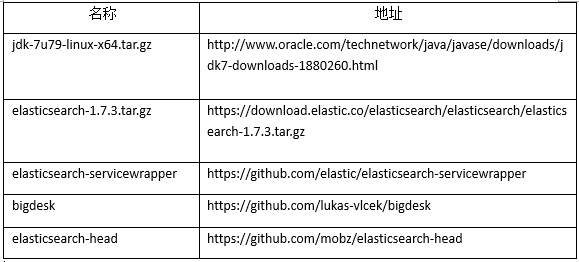
1、安裝JDK,並且設定環境變數和使之生效(略,這一步可以去參照我之前的博文“hadoop+hive的安裝配置”裡寫的很詳細),如圖所示,jdk安裝成功:

2、新增新的使用者,在本例中新增的使用者名稱為es:
[[email protected] ~] useradd es
[[email protected] ~] passwd es
切換到es使用者下:
3、建立新的資料夾,並將之後的所有的檔案放到這個資料夾,如圖:

4、將下載好的elasticsearch-1.7.3.tar.gz複製到3中新建的資料夾下,並解壓:
如何上傳呢?請參照我之前的博文“hadoop+hive的安裝配置”,用scp命令將elasticsearch-1.7.3.tar.gz從本地上傳到3中新建的資料夾下。
解壓:
tar -zxvf elasticsearch-1.7.3.tar.gz
解壓後,並賦予普通使用者es,如下圖:

5、進入elasticsearch的bin目錄下,啟動elassticsearch指令碼,如下圖:

啟動成功後如下圖所示:
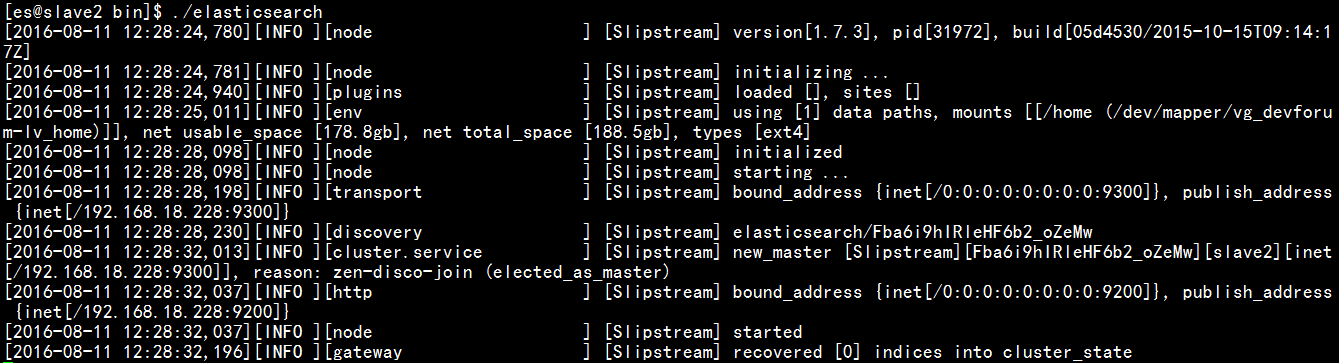
也可以用如下命令進行後臺啟動:

6、測試
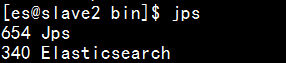
(1)可以通過jps檢視,如圖:
(2)用如下方法檢視:下圖中192.168.18.228有時可以換做是localhost,(另外是否要將elascticsearch下的config下的elasticsearch.yml中的network處替換成192.168.18.228,我未驗證,若未出現下圖所示,請將yml的network處替換成192.168.18.228,囧)
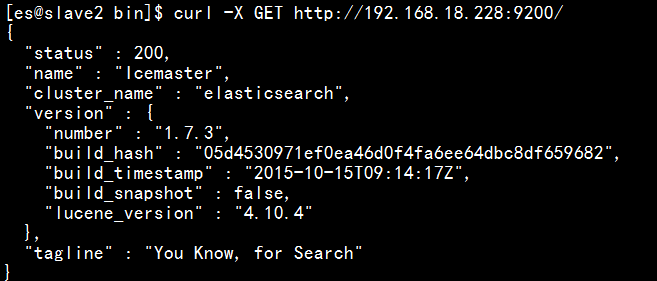
若出現上圖,即為elasticsearch安裝成功。
7、安裝外掛elasticsearch-servicewrapper方便管理elasticsearch服務:
附:
./elasticsearch console ——-前臺執行
./elasticsearch start ——-後臺執行
./elasticsearch install——-新增到系統自動啟動
./elasticsearch remove——-取消隨系統自動啟動
8、後面的兩種外掛head和bigdesk是針對叢集管理的,我在本例中只是單機安裝,所以就沒必要安裝這兩款外掛了,有需要的可以參考以下的連結:
或者更多的連結可以參考學習交流:
本文同時參考了以下的連結:
相關推薦
ElasticSearch概述及Linux下的單機ElasticSearch安裝
這兩天在專案中要涉及到ElasticSearch的使用,就上網去搜索了一些這方面的資料,發現elasticSearch的安裝分為單機和叢集兩種方式。在本例中,我們重點介紹單機下的ElasticSearch的安裝,親測可用,記錄下來與各位同仁分享。 一、Elas
elasticsearch+Kibana在linux下的詳細安裝步驟
elasticsearch-6.4.2.tar.gz安裝介紹(單機版) 步驟1:安裝包下載拷貝至伺服器上。(啟動命令 進入檔案的bin目錄 ./elasticsearch 加上-d 後臺執行) 注意點:es不允許root使用者啟動,所以要新建另外一個使用者啟動es。Es預
Linux下單機安裝部署kafka及代碼實現
{} edt serial integer exc height 復制 有一個 images 技術交流群:233513714 這幾天研究了kafka的安裝及使用,在網上找了很多教程但是均以失敗告終,直到最後想起網絡方面的問題最終才安裝部署成功,下面就介紹一下kaf
Linux下rz/sz安裝及使用方法
文件選擇 登錄 class onf track 運行 使用方法 con rec 新搞的雲服務器用SecureCRT不支持上傳和下載,沒有找到rz命令。記錄一下如何安裝rz/sz命令的方法。 一、工具說明 在SecureCR
linux下vsftpd的安裝及配置
transfer rem mon wrap attack comment ftpd 用戶 user 1. 安裝 執行 yum -y install vsftpd 註:(1)可通過 rpm -qa|grep vsftpd 檢查是否已安裝 vsftpd .
Linux下rsync的安裝及簡單使用
roc ack blog 應用 保持 image 常用 yum afa 一、RSYNC安裝源碼安裝:到rsync官網下載rsync源碼安裝包,上傳到服務器上,或者wget下載。解壓rsync源碼安裝包進入解壓後的目錄,執行 ./configure --prefix=/usr
Linux下Mysql的安裝及執行(詳解)
1、組及使用者建立: sudo groupadd mysql #新增組 sudo useradd -r -g mysql mysql #新增所建立組下的使用者 2、官方下載網址 wget http://downloads.mysql.com/archives/get/file/mysql-5
Linux下使用ElasticSearch教程(一)
一:ElasticSearch在Linux下安裝簡單總結. 1.本次安裝的版本是ES6.3.2.版本.下載到壓縮包.解壓後直接來到當前的解壓目錄. cd config &n
Linux下的MySQL安裝及解除安裝
1.1 檢視mysql的安裝路徑: [[email protected] ~]# whereis mysql mysql: /usr/bin/mysql /usr/lib/mysql/usr/share/mysql /usr/share/man/man1
【轉載】linux下的samba安裝及配置
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Linux下eclipse的安裝及配置
Eclipse for Ubuntu: Eclipse這款免費的IDE至今還有不少人在用,由於win10系統太耗費CPU資源,加之一直對Linux非常感興趣,想在Linux系統下玩玩,安裝配置過程中也踩了一些坑
Linux下Opencv的安裝及配置使用
OpenCV是提供原始碼的,所以從這個角度來說,是不區分32或64位的。但是,OpenCV裡面也會有一些已經編譯好了的庫或執行檔案,那麼這個是要區分32或64位的。 一、安裝 1 安裝cmake及一些依賴庫 sudo apt-get install cmake sudo apt-get
Kafka學習筆記(1)----Kafka的簡介和Linux下單機安裝
1. Kafka簡介 Kafka is a distributed,partitioned,replicated commit logservice。它提供了類似於JMS的特性,但是在設計實現上完全不同,此外它並不是JMS規範的實現。kafka對訊息儲存時根據Topic進行歸類,傳送訊息者成為Produ
linux下測試elasticsearch的步驟,圖文解析
自己在測試時候遇到的問題這裡都寫了,真的是一模一樣,一篇好文! 1、外網訪問9200埠 系統centos7.0安裝elasticsearch後本機可以訪問127.0.0.1:9200,但不能訪問【公網IP:9200】如何解決? 修改配置檔
Nginx介紹及linux下的安裝
是什麼? 高效能HTTP伺服器/反向代理伺服器。 用途? HTTP伺服器,做靜態資源(靜態網頁,圖片等)伺服器。 虛擬主機,實現一臺伺服器虛擬多個小網站。 反向代理、負載均衡,多臺伺服器叢集需要Nginx做反向代理,使伺服器之間負載均衡。 安裝? 1.安裝環境及依賴包
centos 7( linux )下搭建elasticsearch踩坑記
目錄 概述 環境準備 elasticsearch配置 啟動踩坑記 彩蛋 概述 公司最近在做全文檢索的專案,發現elasticsearch踩了不少坑,百度點進去又是坑,在此記錄一下自己的
Linux下原始碼包安裝Swoole及基本使用
下載Swoole PECL擴充套件原始碼包:http://pecl.php.net/package/swoole 關於PHP版本依賴選擇: 下載好放到/usr/local/src下,解壓縮: tar -zxvf swoole-2.2.0.tgz 準備擴充套件安裝編譯環境:
Spark本地安裝及Linux下偽分散式搭建
title: Spark本地安裝及Linux下偽分散式搭建 date: 2018-12-01 12:34:35 tags: Spark categories: 大資料 toc: true 個人github部落格:Josonlee’s Blog 文章目錄
Linux下mongoDB的安裝及解除安裝
軟體包 MongoDB在自己的倉庫中提供官方支援的軟體包,該倉庫包含下列包: 包名 描述 mongodb-org 一個集合包,它將自動安裝下面列出的四個元件包 mongodb-org-server 該包中包含mongod守護程式,關聯的ini
linux下通過yum安裝svn及配置
1.環境 centos6.4 2.安裝svn yum -y install subversion 3.配置 建立版本庫目錄 mkdir /www/svndata svnserve -d -r /www/svndata 4.建立版本庫 建立一個新的Subversio