
Python 和字元編碼
阿新 • • 發佈:2019-01-28
Python 2.* 的程式設計師肯定遇到過這樣那樣的字元編碼問題:
- 為什麼從網站上爬取的html 在本地顯示的就不正常?
- 為什麼會顯示 UnicodeEncodeError: 'ascii' codec can't encode character 這樣的錯誤
- python 中encode(),decode() 方法如何使用?
一、從編碼的歷史談起
1.1 ASCII 碼錶
現代計算機起源於英語為母語的美國,所以最初美國工程師在字元編碼中首先考慮的是自己母語的使用方便,即26個英文字母(大小寫),0-9數字和常用字元的編碼。在1963年頒佈了ASCII (American Standard Code for Information Interchange)字元編碼表,如下所示: [caption id="" align="aligncenter" width="715"]
for ii in xrange(0,128) print chr(ii)+'\t'1.2 GB2312 中文字元編碼
>>> ("你好").decode('gb2312').encode('gb2312')
'\xc4\xe3\xba\xc3'
>>>decode() 是將str 字串轉化為unicode 字串;
encode() 是將unicode 字串轉化為str 字串;
以GB2312 為代表的區域性字元編碼方法還是存在著通用性的問題。- 因為不同國家指定了不同的字元編碼方法,相同的0/1 字串在不同的字元編碼方法中很可能對應不同的字元。那麼開啟一個檔案,首先得知道它的編碼方法才行。
- 為全世界語言字元進行統一的字元編碼(或者制定一套各地域字元編碼方法的轉換規則),兩個位元組肯定是不夠的,那麼需要更多位元組來儲存字元麼?
1.3 unicode
unicode 可以看做一個終極的字元編碼方法,它給出了地球上常用字元的二進位制對映,而且所有的二進位制字串唯一地表示一個字元。當然unicode 也向下相容ASCII,下面給出了一些字元所對應的二進位制、十六進位制值。字元 十六進位制 二進位制
I 49 01001001
J 4A 01001010
日 65e5 01101001 11100101
ᅱ FFD6 11111111 11010110
♀ 2640 00100110 01000000
♬ 266C 00100110 01101100
關於unicode 問題:如果計算機讀到一個位元組,如何判斷這個位元組是新的字元的開始,還是一個未讀完字元的繼續呢?這個問題在ASCII 碼錶和GB2312 中是不存在的,因為所有字元都是固定長度。那麼unicode 可不可以也使用最大的長度字元的位元組數來表示呢?當然可以,比如最大unicode 用四個位元組可以儲存,那麼所有的字元都佔用四個位元組,但問題就是需要的儲存空間變得很大。比如unicode 對應字元的儲存如下(這麼多0 是不是浪費了很多儲存空間呢?):
I 00000049
J 0000004A
日 000065e5
ᅱ 0000FFD6
♀ 00002640
♬ 0000266C字元 十六進位制 二進位制 首位編碼
I 49 01001001 11001001
J 4A 01001010 11001010
日 65e5 01101001 11100101 10000001 01010011 01100101
ᅱ FFD6 11111111 11010110 10000011 01111111 01010110
♀ 2640 00100110 01000000 11001100 01000000
♬ 266C 00100110 01101100 10010011 000110111.4 UTF-8
該UTF-8 出場了,簡單地說,UTF-8 是unicode 在計算機中的一種實現方式。和我們上節提到的首位編碼類似,也是一種變長編碼,每個字元佔1-4 個位元組。UTF-8 將位元組分為數值位和標識位,數值位真正儲存字元編碼數值,標識位表示這個位元組是屬於哪個字元的、或者該字元佔多少個位元組。UTF-8 編碼方法的: 單位元組,首位為標識位0;多位元組字元首位元組標誌位1··10開頭,字元佔多少位元組則有多少1,其他位元組標識位10開頭;- 單位元組字元: 0xxxxxxx (以0 開頭標誌位,數值位用x 表示)
- 雙位元組字元: 110xxxxx 10xxxxxx
- 三位元組字元: 1110xxxx 10xxxxxx 10xxxxxx
- 四位元組字元: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8二進位制 unicode二進位制
0xxxxxxx 00-7F
110xxxxx 10xxxxxx 0080-07FF
1110xxxx 10xxxxxx 10xxxxxx 0800-FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 00010000-10FFF>>> (u"你").encode('utf-8')
'\xe4\xbd\xa0'
>>> (u"你")
u'\u4f60'字元 unicode十六進位制 unicode二進位制 UTF-8二進位制 UTF-8十六進位制
你 4f60 01001111 01100000 11100100 10111101 10100000 e4bd60二、檔案和終端編碼格式
所有的文字檔案在計算機中儲存的都是一串有限長度的二進位制串,只有使用合理的編碼方式才能正確地顯示檔案,但檔案本身又是如何告訴編輯器它是如何編碼的呢?2.1 py 檔案的字元編碼
實際上如果檔案本身不申明,編輯器是不知道一個檔案所採用的編碼方法的。所以編輯器有一個預設的開啟方式,比如記事本(notepad)和notepad++ 都預設用ASCII 開啟檔案。作為Python 初學者可能會遇到下面的一個問題: 故障1:新建一個test.py 檔案,用記事本預設開啟,輸入下面內容:import os
print "你" >>python test.py
File "test.py", line 2
SyntaxError: Non-ASCII character '\xc4' in file test.py on line 3, but no encoding
declared; see http://python.org/dev/peps/pep-0263/ for details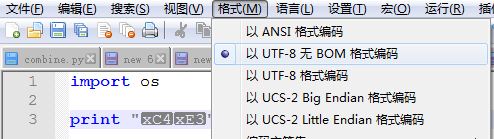 寫過Python 程式的都知道,為了避免py 檔案內的編碼問題,需要在檔案首做一個申明:
寫過Python 程式的都知道,為了避免py 檔案內的編碼問題,需要在檔案首做一個申明:
#_*_encoding:utf-8_*_2.2 python 與檔案的字元編碼
除了py 檔案本身要儲存為UTF-8 格式,以避免出現py 檔案出現的非ASCII 字元無法被正確的識別。當py 訪問其他檔案,將資料寫入檔案時也需要注意字元編碼。 故障2:Python2 預設編碼是ASCII 碼>>> example = u'你好'
>>> str(example)
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
str(example)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1:
ordinal not in range(128)
>>> example = u'你好'
>>> open('temp.txt','w').write(example)
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
open('temp.txt','w').write(example)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1:
ordinal not in range(128)>>> unicode('abcdef' + chr(255))
Traceback (most recent call last):
...
UnicodeDecodeError: 'ascii' codec can't decode byte 0xff in position 6:
ordinal not in range(128)2.3 終端編碼
上linux 作業系統課程的時候,我們被教導到:一切都是檔案,終端作為一種裝置也是檔案,當需要輸出內容到終端時,實際上也是按照終端對應的字元編碼顯示相應的內容。 故障3:如果你在windows 終端cmd.exe 執行下面程式碼(需要安裝requests 包)。import os,sys
import requests
ss = requests.Session()
res = ss.get("http://www.hust.edu.cn/")
con = res.content
print con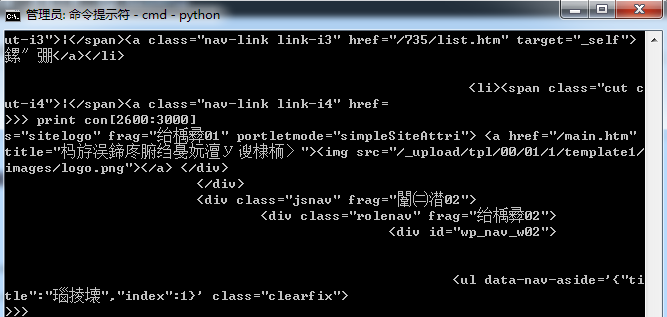 但如果你進一步將con 中內容寫入到檔案或者在linux 下執行這段程式碼,可能則沒有亂碼的問題。問題出在哪裡呢?原因是因為頁面內容是UTF-8 編碼(可以在頁面原始碼<meta charset="utf-8">中看到 ),而windows 命令提示符cmd 中卻使用的是mbcs 字元編碼。可以通過下面的命令檢視該終端的字元編碼
但如果你進一步將con 中內容寫入到檔案或者在linux 下執行這段程式碼,可能則沒有亂碼的問題。問題出在哪裡呢?原因是因為頁面內容是UTF-8 編碼(可以在頁面原始碼<meta charset="utf-8">中看到 ),而windows 命令提示符cmd 中卻使用的是mbcs 字元編碼。可以通過下面的命令檢視該終端的字元編碼
print sys.getfilesystemencoding()export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
export LANGUAGE=en_US.UTF-82.4 str 和unicode
計算機儲存的資料,以及從檔案中讀取的資料都可以理解為str 字串,str 字串是需要字元編碼才能夠被計算機所理解,而unicode 字串採用統一的字元編碼方法。為節省空間等原因計算機並不會直接儲存unicode 型別。但在Python2 處理字元資料時,建議全部轉化為unicode。 但如果不知道str 字串編碼型別,按照Python2 預設的ASCII 碼轉換出現大於128 的位元組的錯誤怎麼辦(UnicodeEncodeError: 'ascii' codec can't encode characters)?
有兩種方法:一是用特定的數值(magic number)替代錯誤的位元組;二是乾脆忽略錯誤位元組
>>> unicode('\x80abc', errors='replace')
u'\ufffdabc'
>>> unicode('\x80abc', errors='ignore')
u'abc'
>>> '你'+u'你' Traceback (most recent call last): File "<pyshell#0>", line 1, in <module> '你'+u'你' UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 0: ordinal not in range(128)看下面的例子比較str 和unicode 字串,python2 按照預設的ASCII 碼解碼為unicode 過程中發現無法識別的位元組,然後就返回不相等(False),並丟擲一個異常。
>>> if '你' == u'你':
... print True
>>>
>>> '你' == u'你'
__main__:1: UnicodeWarning: Unicode equal comparison failed to convert both argu
ments to Unicode - interpreting them as being unequal
False
>>>'你'.decode('gb2312') == u'你':
True
>>> reload(sys)
sys.setdefaultencoding('utf-8')2.5 _*_encoding:utf-8_*_ 和 reload(sys) sys.setdefaultencoding('utf-8')
有了上面一節的基礎,我們大概知道了#_*_encoding:utf-8_*_reload(sys)
sys.setdefaultencoding('utf-8')#_*_encoding:utf-8_*_
import os
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
sym1 =u'♀'+'你'
sym2 = '你'.decode('utf-8').encode('gb2312')
ff = open('temp.txt','w')
ff.write(sym1)
ff.write(sym2)
ff.close()
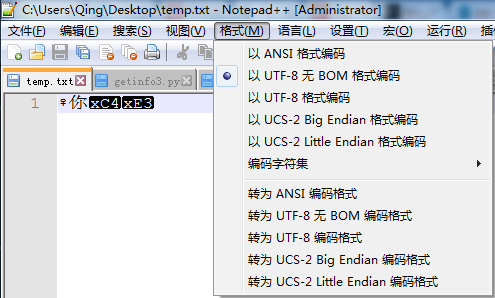 不難看出,'♀' 和' 你' 顯示都沒有問題,但後一個'你' 就因為使用的是GB2312 編碼,寫入檔案後,前兩個字元都是UTF-8 編碼,後一個字元GB2312 編碼,用UTF-8 格式開啟時,最後一個編碼肯定就顯示不正常了。
當然,上面只是一個例子,很多時候你不會在程式中寫出這麼buggy 的程式碼,但是很多時候用python 處理一些非UTF-8 編碼的檔案或者資料時,就會因為你強制申明str 為UTF-8 編碼導致很多問題,比如讀取非UTF-8 編碼的Oracle 的資料庫,修改、新增非UTF-8 編碼的檔案時,就會產生很多字元編碼混亂。因此也有人建議python2 程式設計師在處理str 時能夠顯示地使用特定合適的字元編碼,而不是預設地使用UTF-8。
Python3 只有unicode 字串,而沒有str 字串,上面所遇到的字元編碼的坑不再有了。
所以—— Bravo~ 學Python3 去吧,騷年!
不難看出,'♀' 和' 你' 顯示都沒有問題,但後一個'你' 就因為使用的是GB2312 編碼,寫入檔案後,前兩個字元都是UTF-8 編碼,後一個字元GB2312 編碼,用UTF-8 格式開啟時,最後一個編碼肯定就顯示不正常了。
當然,上面只是一個例子,很多時候你不會在程式中寫出這麼buggy 的程式碼,但是很多時候用python 處理一些非UTF-8 編碼的檔案或者資料時,就會因為你強制申明str 為UTF-8 編碼導致很多問題,比如讀取非UTF-8 編碼的Oracle 的資料庫,修改、新增非UTF-8 編碼的檔案時,就會產生很多字元編碼混亂。因此也有人建議python2 程式設計師在處理str 時能夠顯示地使用特定合適的字元編碼,而不是預設地使用UTF-8。
Python3 只有unicode 字串,而沒有str 字串,上面所遇到的字元編碼的坑不再有了。
所以—— Bravo~ 學Python3 去吧,騷年!
參考文章:
檢視原文:http://blog.foool.net/2016/07/python-%e5%92%8c%e5%ad%97%e7%ac%a6%e7%bc%96%e7%a0%81/