大資料學習筆記之Hadoop-HDFS
HDFS的Shell操作
- 基本語法
bin/hadoop fs 具體命令 OR bin/hdfs dfs 具體命令
dfs是fs的實現類。 - 命令大全
bin/hadoop fs [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] <localsrc> ... <dst>] [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] <path> ...] [-cp [-f] [-p] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] <path> ...] [-expunge] [-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getmerge [-nl] <src> <localdst>] [-help [cmd ...]] [-ls [-d] [-h] [-R] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-usage [cmd ...]]
- 常用命令實操
(0)啟動Hadoop叢集(方便後續的測試)
sbin/start-dfs.sh
sbin/start-yarn.sh
(1)-help:輸出這個命令引數
hadoop fs -help rm
(2)-ls: 顯示目錄資訊
hadoop fs -ls /
(3)-mkdir:在HDFS上建立目錄
hadoop fs -mkdir -p /sanguo/shuguo
(4)-moveFromLocal:從本地剪下貼上到HDFS
touch kongming.txt hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
(5)-appendToFile:追加一個檔案到已經存在的檔案末尾
touch liubei.txt
vi liubei.txt
輸入
san gu mao lu
hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
(6)-cat:顯示檔案內容
hadoop fs -cat /sanguo/shuguo/kongming.txt
(7)-chgrp 、-chmod、-chown:Linux檔案系統中的用法一樣,修改檔案所屬許可權
hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt hadoop fs -chown root:root /sanguo/shuguo/kongming.txt
(8)-copyFromLocal:從本地檔案系統中拷貝檔案到HDFS路徑去
hadoop fs -copyFromLocal README.txt /
(9)-copyToLocal:從HDFS拷貝到本地
hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
(10)-cp :從HDFS的一個路徑拷貝到HDFS的另一個路徑
hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
(11)-mv:在HDFS目錄中移動檔案
hadoop fs -mv /zhuge.txt /sanguo/shuguo/
(12)-get:等同於copyToLocal,就是從HDFS下載檔案到本地
hadoop fs -get /sanguo/shuguo/kongming.txt ./
(13)-getmerge:合併下載多個檔案,比如HDFS的目錄 /user/root/test下有多檔案:log.1, log.2,log.3,…
hadoop fs -getmerge /user/root/test/* ./zaiyiqi.txt
(14)-put:等同於copyFromLocal
hadoop fs -put ./zaiyiqi.txt /user/root/test/
(15)-tail:顯示一個檔案的末尾
hadoop fs -tail /sanguo/shuguo/kongming.txt
(16)-rm:刪除檔案或資料夾
hadoop fs -rm /user/root/test/jinlian2.txt
(17)-rmdir:刪除空目錄
hadoop fs -mkdir /test
hadoop fs -rmdir /test
(18)-du統計資料夾的大小資訊
hadoop fs -du -s -h /user/root/test
2.7 K /user/root/test
hadoop fs -du -h /user/root/test
1.3 K /user/root/test/README.txt
15 /user/root/test/jinlian.txt
1.4 K /user/root/test/zaiyiqi.txt
(19)-setrep:設定HDFS中檔案的副本數量
hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
HDFS常用API操作
maven依賴
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
log4j
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
測試引數優先順序
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 獲取檔案系統
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 上傳檔案
fs.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));
// 3 關閉資源
fs.close();
System.out.println("over");
}
將hdfs-site.xml拷貝到專案的根目錄下並將配置檔案修改為如下配置,將副本調整為1
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
引數優先順序排序:(1)客戶端程式碼中設定的值 >(2)ClassPath下的使用者自定義配置檔案 >(3)然後是伺服器的預設配置
HDFS檔案下載
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 執行下載操作
// boolean delSrc 指是否將原檔案刪除
// Path src 指要下載的檔案路徑
// Path dst 指將檔案下載到的路徑
// boolean useRawLocalFileSystem 是否開啟檔案校驗
fs.copyToLocalFile(false, new Path("/banzhang.txt"), new Path("e:/banhua.txt"), true);
// 3 關閉資源
fs.close();
}
HDFS 資料夾刪除
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 執行刪除
fs.delete(new Path("/0508/"), true);
// 3 關閉資源
fs.close();
}
資料夾刪除
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 執行刪除
fs.delete(new Path("/0508/"), true);
// 3 關閉資源
fs.close();
}
HDFS 檔名更改
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 修改檔名稱
fs.rename(new Path("/banzhang.txt"), new Path("/banhua.txt"));
// 3 關閉資源
fs.close();
}
HDFS檔案詳情檢視
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException{
// 1獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 獲取檔案詳情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
// 輸出詳情
// 檔名稱
System.out.println(status.getPath().getName());
// 長度
System.out.println(status.getLen());
// 許可權
System.out.println(status.getPermission());
// 分組
System.out.println(status.getGroup());
// 獲取儲存的塊資訊
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 獲取塊儲存的主機節點
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("-----------班長的分割線----------");
}
// 3 關閉資源
fs.close();
}
HDFS 檔案和資料夾判斷
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案配置資訊
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 判斷是檔案還是資料夾
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// 如果是檔案
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 關閉資源
fs.close();
}
HDFS的IO流操作
HDFS檔案上傳
- 需求:把本地e盤上的banhua.txt檔案上傳到HDFS根目錄
2.編寫程式碼
@Test
public void putFileToHDFS() throws IOException, InterruptedException, URISyntaxException {
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 建立輸入流
FileInputStream fis = new FileInputStream(new File("e:/banhua.txt"));
// 3 獲取輸出流
FSDataOutputStream fos = fs.create(new Path("/banhua.txt"));
// 4 流對拷
IOUtils.copyBytes(fis, fos, configuration);
// 5 關閉資源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
HDFS的檔案下載
- 需求:從HDFS上下載banhua.txt檔案到本地e盤上
- 編寫程式碼
// 檔案下載
@Test
public void getFileFromHDFS() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 獲取輸入流
FSDataInputStream fis = fs.open(new Path("/banhua.txt"));
// 3 獲取輸出流
FileOutputStream fos = new FileOutputStream(new File("e:/banhua.txt"));
// 4 流的對拷
IOUtils.copyBytes(fis, fos, configuration);
// 5 關閉資源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
fs.close();
}
HDFS定位檔案讀取
1.需求:分塊讀取HDFS上的大檔案,比如根目錄下的/hadoop-2.7.2.tar.gz
2.編寫程式碼
(1)下載第一塊
@Test
public void readFileSeek1() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 獲取輸入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));
// 3 建立輸出流
FileOutputStream fos = new FileOutputStream(new File("e:/hadoop-2.7.2.tar.gz.part1"));
// 4 流的拷貝
byte[] buf = new byte[1024];
for(int i =0 ; i < 1024 * 128; i++){
fis.read(buf);
fos.write(buf);
}
// 5關閉資源
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
fs.close();
}
(2)下載第二塊
@Test
public void readFileSeek2() throws IOException, InterruptedException, URISyntaxException{
// 1 獲取檔案系統
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:9000"), configuration, "root");
// 2 開啟輸入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.7.2.tar.gz"));
// 3 定位輸入資料位置
fis.seek(1024*1024*128);
// 4 建立輸出流
FileOutputStream fos = new FileOutputStream(new File("e:/hadoop-2.7.2.tar.gz.part2"));
// 5 流的對拷
IOUtils.copyBytes(fis, fos, configuration);
// 6 關閉資源
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
}
(3)合併檔案
在Window命令視窗中進入到目錄E:\,然後執行如下命令,對資料進行合併
type hadoop-2.7.2.tar.gz.part2 >> hadoop-2.7.2.tar.gz.part1
合併完成後,將hadoop-2.7.2.tar.gz.part1重新命名為hadoop-2.7.2.tar.gz。解壓發現該tar包非常完整。
CheckPoint時間設定
(1)通常情況下,SecondaryNameNode每隔一小時執行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分鐘檢查一次操作次數,3當操作次數達到1百萬時,SecondaryNameNode執行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作動作次數</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分鐘檢查一次操作次數</description>
</property >
NameNode故障處理
NameNode故障後,可以採用如下兩種方法恢復資料。
方法一:將SecondaryNameNode中資料拷貝到NameNode儲存資料的目錄;
- kill -9 NameNode程序
- 刪除NameNode儲存的資料(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
- 拷貝SecondaryNameNode中資料到原NameNode儲存資料目錄
scp -r [email protected]:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/
- 重新啟動NameNode
[[email protected] hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
方法二:使用-importCheckpoint選項啟動NameNode守護程序,從而將SecondaryNameNode中資料拷貝到NameNode目錄中。
- 修改hdfs-site.xml
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
- kill -9 NameNode程序
- 刪除NameNode儲存的資料(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[[email protected] hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*
- 如果SecondaryNameNode不和NameNode在一個主機節點上,需要將SecondaryNameNode儲存資料的目錄拷貝到NameNode儲存資料的平級目錄,並刪除in_use.lock檔案
[[email protected] dfs]$ scp -r [email protected]:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary ./
[[email protected] namesecondary]$ rm -rf in_use.lock
[[email protected] dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[[email protected] dfs]$ ls
data name namesecondary
- 匯入檢查點資料(等待一會ctrl+c結束掉)
[[email protected] hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint
- 啟動NameNode
[[email protected] hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
NameNode多目錄配置
- NameNode的本地目錄可以配置成多個,且每個目錄存放內容相同,增加了可靠性
- 具體配置如下
(1)在hdfs-site.xml檔案中增加如下內容
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
(2)停止叢集,刪除data和logs中所有資料。
[[email protected] hadoop-2.7.2]$ rm -rf data/ logs/
[[email protected] hadoop-2.7.2]$ rm -rf data/ logs/
[[email protected] hadoop-2.7.2]$ rm -rf data/ logs/
(3)格式化叢集並啟動。
[[email protected] hadoop-2.7.2]$ bin/hdfs namenode –format
[[email protected] hadoop-2.7.2]$ sbin/start-dfs.sh
(4)檢視結果
[[email protected] dfs]$ ll
總用量 12
drwx------. 3 root root 4096 12月 11 08:03 data
drwxrwxr-x. 3 root root 4096 12月 11 08:03 name1
drwxrwxr-x. 3 root root 4096 12月 11 08:03 name2
掉線實現引數設定
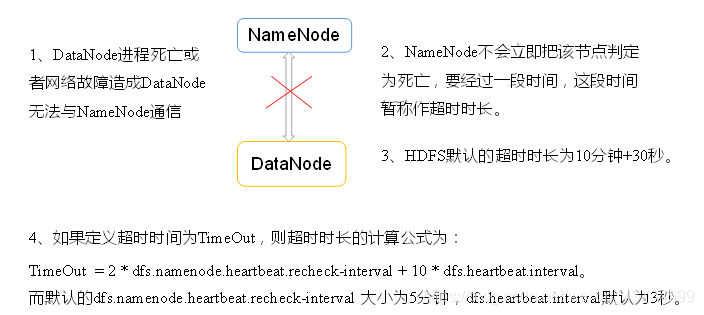
需要注意的是hdfs-site.xml 配置檔案中的heartbeat.recheck.interval的單位為毫秒,dfs.heartbeat.interval的單位為秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
服役新節點
- 需求
隨著公司業務的增長,資料量越來越大,原有的資料節點的容量已經不能滿足儲存資料的需求,需要在原有叢集基礎上動態新增新的資料節點。 - 環境準備
(1)在hadoop104主機上再克隆一臺hadoop105主機
(2)修改IP地址和主機名稱
(3)刪除原來HDFS檔案系統留存的檔案(/opt/module/hadoop-2.7.2/data和log)
(4)source一下配置檔案
[[email protected] hadoop-2.7.2]$ source /etc/profile
- 服役新節點具體步驟
(1)直接啟動DataNode,即可關聯到叢集
[[email protected] hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
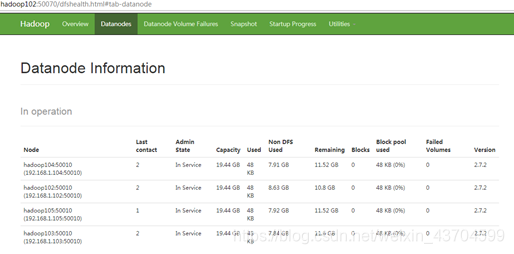
(2)在hadoop105上上傳檔案
[[email protected] hadoop-2.7.2]$ hadoop fs -put /opt/module/hadoop-2.7.2/LICENSE.txt /
(3)如果資料不均衡,可以用命令實現叢集的再平衡
[[email protected] sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
退役舊資料節點
新增白名單
新增到白名單的主機節點,都允許訪問NameNode,不在白名單的主機節點,都會被退出。
配置白名單的具體步驟如下:
(1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目錄下建立dfs.hosts檔案
[[email protected] hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[[email protected] hadoop]$ touch dfs.hosts
[[email protected] hadoop]$ vi dfs.hosts
新增如下主機名稱(不新增hadoop105)
hadoop102
hadoop103
hadoop104
(2)在NameNode的hdfs-site.xml配置檔案中增加dfs.hosts屬性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
(3)配置檔案分發
[[email protected] hadoop]$ xsync hdfs-site.xml
(4)重新整理NameNode
[[email protected] hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
(5)更新ResourceManager節點
[[email protected] hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:17:11 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
(6)在web瀏覽器上檢視
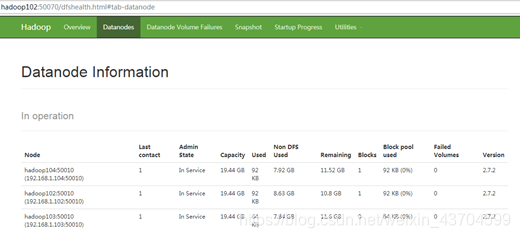
(7)如果資料不均衡,可以用命令實現叢集的再平衡
[[email protected] sbin]$ ./start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
黑名單退役
在黑名單上面的主機都會被強制退出。
1.在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目錄下建立dfs.hosts.exclude檔案
[[email protected] hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[[email protected] hadoop]$ touch dfs.hosts.exclude
[[email protected] hadoop]$ vi dfs.hosts.exclude
新增如下主機名稱(要退役的節點)
hadoop105
2.在NameNode的hdfs-site.xml配置檔案中增加dfs.hosts.exclude屬性
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value>
</property>
3.重新整理NameNode、重新整理ResourceManager
[[email protected] hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
[[email protected] hadoop-2.7.2]$ yarn rmadmin -refreshNodes
17/06/24 14:55:56 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8033
- 檢查Web瀏覽器,退役節點的狀態為decommission in progress(退役中),說明資料節點正在複製塊到其他節點

- 等待退役節點狀態為decommissioned(所有塊已經複製完成),停止該節點及節點資源管理器。注意:如果副本數是3,服役的節點小於等於3,是不能退役成功的,需要修改副本數後才能退役

[[email protected] hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
[[email protected] hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager
如果資料不均衡,可以用命令實現叢集的再平衡
[[email protected] hadoop-2.7.2]$ sbin/start-balancer.sh
starting balancer, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-balancer-hadoop102.out
Time Stamp Iteration# Bytes Already Moved Bytes Left To Move Bytes Being Moved
注意:不允許白名單和黑名單中同時出現同一個主機名稱。
回收站
開啟回收站功能,可以將刪除的檔案在不超時的情況下,恢復原資料,起到防止誤刪除、備份等作用。
- 回收站引數設定及工作機制
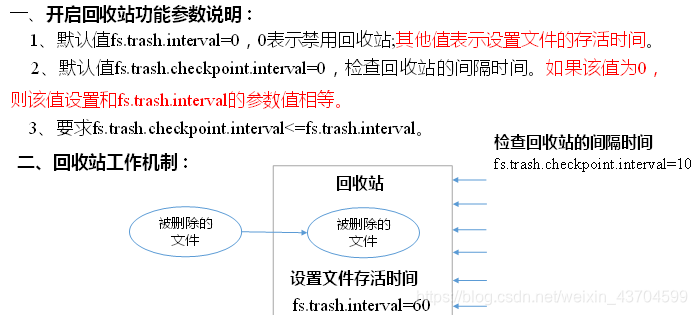
- 啟用回收站
修改core-site.xml,配置垃圾回收時間為1分鐘。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
- 查看回收站
回收站在叢集中的路徑:/user/root/.Trash/…. - 修改訪問垃圾回收站使用者名稱稱
[core-site.xml]
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
- 通過程式刪除的檔案不會經過回收站,需要呼叫moveToTrash()才進入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
- 恢復回收站資料
[[email protected] hadoop-2.7.2]$ hadoop fs -mv
/user/root/.Trash/Current/user/root/input /user/root/input
- 清空回收站
[[email protected] hadoop-2.7.2]$ hadoop fs -expunge
快照管理

(1)開啟/禁用指定目錄的快照功能
[[email protected] hadoop-2.7.2]$ hdfs dfsadmin -allowSnapshot /user/root/input
[[email protected] hadoop-2.7.2]$ hdfs dfsadmin -disallowSnapshot
/user/root/input
(2)對目錄建立快照
[[email protected] hadoop-2.7.2]$ hdfs dfs -createSnapshot /user/root/input
通過web訪問hdfs://hadoop102:50070/user/root/input/.snapshot/s…..// 快照和原始檔使用相同資料
[[email protected] hadoop-2.7.2]$ hdfs dfs -lsr /user/root/input/.snapshot/
(3)指定名稱建立快照
[[email protected] hadoop-2.7.2]$ hdfs dfs -createSnapshot /user/root/input miao170508
(4)重新命名快照
[[email protected] hadoop-2.7.2]$ hdfs dfs -renameSnapshot /user/root/input/ miao170508 root170508
(5)列出當前使用者所有可快照目錄
[[email protected] hadoop-2.7.2]$ hdfs lsSnapshottableDir
(6)比較兩個快照目錄的不同之處
[[email protected] hadoop-2.7.2]$ hdfs snapshotDiff
/user/root/input/ . .snapshot/root170508
(7)恢復快照
[[email protected] hadoop-2.7.2]$ hdfs dfs -cp
/user/root/input/.snapshot/s20170708-134303.027 /user
HDFS HA高可用
HA概述
1)所謂HA(High Available),即高可用(7*24小時不中斷服務)。
2)實現高可用最關鍵的策略是消除單點故障。HA嚴格來說應該分成各個元件的HA機制:HDFS的HA和YARN的HA。
3)Hadoop2.0之前,在HDFS叢集中NameNode存在單點故障(SPOF)。
4)NameNode主要在以下兩個方面影響HDFS叢集
NameNode機器發生意外,如宕機,叢集將無法使用,直到管理員重啟
NameNode機器需要升級,包括軟體、硬體升級,此時叢集也將無法使用
HDFS HA功能通過配置Active/Standby兩個NameNodes實現在叢集中對NameNode的熱備來解決上述問題。如果出現故障,如機器崩潰或機器需要升級維護,這時可通過此種方式將NameNode很快的切換到另外一臺機器。
HDFS-HA叢集配置
環境準備:
- 修改IP
- 修改主機名及主機名和IP地址的對映
- 關閉防火牆
- ssh免密登入
- 安裝JDK,配置環境變數等
規劃叢集:

配置Zookeeper叢集:
- 叢集規劃
在hadoop102、hadoop103和hadoop104三個節點上部署Zookeeper。 - 解壓安裝
(1)解壓Zookeeper安裝包到/opt/module/目錄下
[[email protected] software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
(2)在/opt/module/zookeeper-3.4.10/這個目錄下建立zkData
mkdir -p zkData
(3)重新命名/opt/module/zookeeper-3.4.10/conf這個目錄下的zoo_sample.cfg為zoo.cfg
mv zoo_sample.cfg zoo.cfg
- 配置zoo.cfg檔案
(1)具體配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(2)配置引數解讀
Server.A=B:C:D。
A是一個數字,表示這個是第幾號伺服器;
B是這個伺服器的IP地址;
C是這個伺服器與叢集中的Leader伺服器交換資訊的埠;
D是萬一叢集中的Leader伺服器掛了,需要一個埠來重新進行選舉,選出一個新的Leader,而這個埠就是用來執行選舉時伺服器相互通訊的埠。
叢集模式下配置一個檔案myid,這個檔案在dataDir目錄下,這個檔案裡面有一個數據就是A的值,Zookeeper啟動時讀取此檔案,拿到裡面的資料與zoo.cfg裡面的配置資訊比較從而判斷到底是哪個server。
4. 叢集操作
(1)在/opt/module/zookeeper-3.4.10/zkData目錄下建立一個myid的檔案
touch myid
新增myid檔案,注意一定要在linux裡面建立,在notepad++裡面很可能亂碼
(2)編輯myid檔案
vi myid
在檔案中新增與server對應的編號:如2
(3)拷貝配置好的zookeeper到其他機器上
scp -r zookeeper-3.4.10/ [email protected]:/opt/app/
scp -r zookeeper-3.4.10/ [email protected]:/opt/app/
並分別修改myid檔案中內容為3、4
(4)分別啟動zookeeper
[[email protected] zookeeper-3.4.10]# bin/zkServer.sh start
[[email protected] zookeeper-3.4.10]# bin/zkServer.sh start
[[email protected] zookeeper-3.4.10]# bin/zkServer.sh start
(5)檢視狀態
[[email protected] zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[[email protected] zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
[[email protected] zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
配置HDFS-HA叢集:
- 官方地址:http://hadoop.apache.org/
- 在opt目錄下建立一個ha資料夾
mkdir ha
- 將/opt/app/下的 hadoop-2.7.2拷貝到/opt/ha目錄下
cp -r hadoop-2.7.2/ /opt/ha/
export JAVA_HOME=/opt/module/jdk1.8.0_144
- 配置core-site.xml
<configuration>
<!-- 把兩個NameNode)的地址組裝成一個叢集mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop執行時產生檔案的儲存目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/ha/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
- 配置hdfs-site.xml
<configuration>
<!-- 完全分散式叢集名稱 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 叢集中NameNode節點都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通訊地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop102:9000</value>
</property>
<!-- nn2的RPC通訊地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop103:9000</value>
</property>
<!-- nn1的http通訊地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop102:50070</value>
</property>
<!-- nn2的http通訊地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop103:50070</value>
</property>
<!-- 指定NameNode元資料在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value>
</property>
<!-- 配置隔離機制,即同一時刻只能有一臺伺服器對外響應 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔離機制時需要ssh無祕鑰登入-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/root/.ssh/id_rsa</value>
</property>
<!-- 宣告journalnode伺服器儲存目錄-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/ha/hadoop-2.7.2/data/jn</value>
</property>
<!-- 關閉許可權檢查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 訪問代理類:client,mycluster,active配置失敗自動切換實現方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
- 拷貝配置好的hadoop環境到其他節點
啟動HDFS-HA叢集:
8. 在各個JournalNode節點上,輸入以下命令啟動journalnode服務
sbin/hadoop-daemon.sh start journalnode
- 在[nn1]上,對其進行格式化,並啟動
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
- 在[nn2]上,同步nn1的元資料資訊
bin/hdfs namenode -bootstrapStandby
- 啟動[nn2]
sbin/hadoop-daemon.sh start namenode
- 檢視web頁面顯示

13. 在[nn1]上,啟動所有datanode
sbin/hadoop-daemons.sh start datanode
- 將[nn1]切換為Active
bin/hdfs haadmin -transitionToActive nn1
- 檢視是否Active
bin/hdfs haadmin -getServiceState nn1
配置HDFS-HA自動故障轉移:
- 具體配置
(1)在hdfs-site.xml中增加
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(2)在core-site.xml檔案中增加
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
- 啟動
(1)關閉所有HDFS服務:
sbin/stop-dfs.sh
(2)啟動Zookeeper叢集:
bin/zkServer.sh start
(3)初始化HA在Zookeeper中狀態:
bin/hdfs zkfc -formatZK
(4)啟動HDFS服務:
sbin/start-dfs.sh
- 驗證
(1)將Active NameNode程序kill
kill -9 namenode的程序id
(2)將Active NameNode機器斷開網路
service network stop
YARN-HA配置:
- 具體配置
(1)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--啟用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--宣告兩臺resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop102</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop103</value>
</property>
<!--指定zookeeper叢集的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
<!--啟用自動恢復-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的狀態資訊儲存在zookeeper叢集-->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
(2)同步更新其他節點的配置資訊
2. 啟動hdfs
(1)在各個JournalNode節點上,輸入以下命令啟動journalnode服務:
sbin/hadoop-daemon.sh start journalnode
(2)在[nn1]上,對其進行格式化,並啟動:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
(3)在[nn2]上,同步nn1的元資料資訊:
bin/hdfs namenode -bootstrapStandby
(4)啟動[nn2]:
sbin/hadoop-daemon.sh start namenode
(5)啟動所有DataNode
sbin/hadoop-daemons.sh start datanode
(6)將[nn1]切換為Active
bin/hdfs haadmin -transitionToActive nn1
- 啟動YARN
(1)在hadoop102中執行:
sbin/start-yarn.sh
(2)在hadoop103中執行:
sbin/yarn-daemon.sh start resourcemanager
(3)檢視服務狀態
bin/yarn rmadmin -getServiceState rm1