
機器學習KNN演算法
轉載請註明作者和出處:http://blog.csdn.net/c406495762 執行平臺: Windows Python版本: Python3.x IDE: Sublime text3
一 簡單k-近鄰演算法
本文將從k-鄰近演算法的思想開始講起,使用python3一步一步編寫程式碼進行實戰訓練。並且,我也提供了相應的資料集,對程式碼進行了詳細的註釋。除此之外,本文也對sklearn實現k-鄰近演算法的方法進行了講解。實戰例項:電影類別分類、約會網站配對效果判定、手寫數字識別。
如果對於程式碼理解不夠的,可以結合本文,觀看由南京航空航天大學碩士:深度眸,為大家免費錄製的視訊:
1.1 k-近鄰法簡介
k近鄰法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一種基本分類與迴歸方法。它的工作原理是:存在一個樣本資料集合,也稱作為訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一個數據與所屬分類的對應關係。輸入沒有標籤的新資料後,將新的資料的每個特徵與樣本集中資料對應的特徵進行比較,然後演算法提取樣本最相似資料(最近鄰)的分類標籤。一般來說,我們只選擇樣本資料集中前k個最相似的資料,這就是k-近鄰演算法中k的出處,通常k是不大於20的整數。最後,選擇k個最相似資料中出現次數最多的分類,作為新資料的分類。
舉個簡單的例子,我們可以使用k-近鄰演算法分類一個電影是愛情片還是動作片。
| 電影名稱 | 打鬥鏡頭 | 接吻鏡頭 | 電影型別 |
|---|---|---|---|
| 電影1 | 1 | 101 | 愛情片 |
| 電影2 | 5 | 89 | 愛情片 |
| 電影3 | 108 | 5 | 動作片 |
| 電影4 | 115 | 8 | 動作片 |
表1.1就是我們已有的資料集合,也就是訓練樣本集。這個資料集有兩個特徵,即打鬥鏡頭數和接吻鏡頭數。除此之外,我們也知道每個電影的所屬型別,即分類標籤。用肉眼粗略地觀察,接吻鏡頭多的,是愛情片。打鬥鏡頭多的,是動作片。以我們多年的看片經驗,這個分類還算合理。如果現在給我一部電影,你告訴我這個電影打鬥鏡頭數和接吻鏡頭數。不告訴我這個電影型別,我可以根據你給我的資訊進行判斷,這個電影是屬於愛情片還是動作片。而k-近鄰演算法也可以像我們人一樣做到這一點,不同的地方在於,我們的經驗更”牛逼”,而k-鄰近演算法是靠已有的資料。比如,你告訴我這個電影打鬥鏡頭數為2,接吻鏡頭數為102,我的經驗會告訴你這個是愛情片,k-近鄰演算法也會告訴你這個是愛情片。你又告訴我另一個電影打鬥鏡頭數為49,接吻鏡頭數為51,我”邪惡”的經驗可能會告訴你,這有可能是個”愛情動作片”,畫面太美,我不敢想象。 (如果說,你不知道”愛情動作片”是什麼?請評論留言與我聯絡,我需要你這樣像我一樣純潔的朋友。) 但是k-近鄰演算法不會告訴你這些,因為在它的眼裡,電影型別只有愛情片和動作片,它會提取樣本集中特徵最相似資料(最鄰近)的分類標籤,得到的結果可能是愛情片,也可能是動作片,但絕不會是”愛情動作片”。當然,這些取決於資料集的大小以及最近鄰的判斷標準等因素。
1.2 距離度量
我們已經知道k-近鄰演算法根據特徵比較,然後提取樣本集中特徵最相似資料(最鄰近)的分類標籤。那麼,如何進行比較呢?比如,我們還是以表1.1為例,怎麼判斷紅色圓點標記的電影所屬的類別呢?如圖1.1所示。
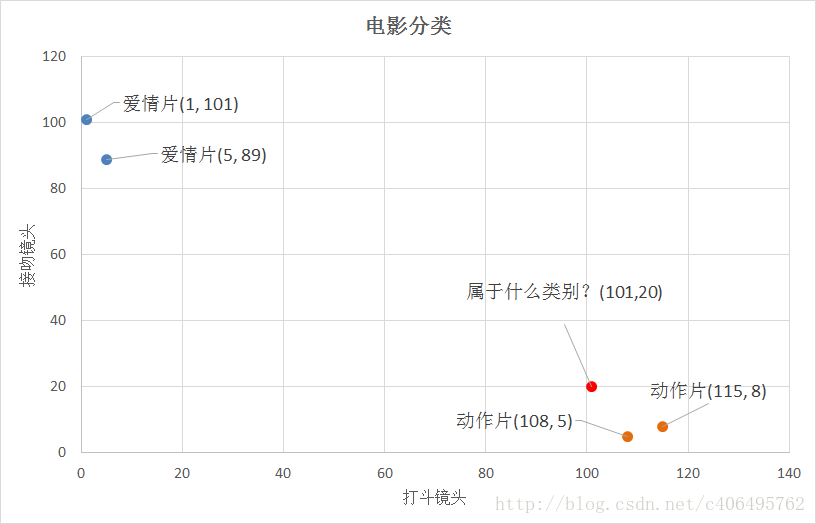 圖1.1 電影分類
圖1.1 電影分類
我們可以從散點圖大致推斷,這個紅色圓點標記的電影可能屬於動作片,因為距離已知的那兩個動作片的圓點更近。k-近鄰演算法用什麼方法進行判斷呢?沒錯,就是距離度量。這個電影分類的例子有2個特徵,也就是在2維實數向量空間,可以使用我們高中學過的兩點距離公式計算距離,如圖1.2所示。
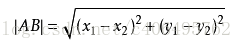 圖1.2 兩點距離公式
圖1.2 兩點距離公式
通過計算,我們可以得到如下結果:
- (101,20)->動作片(108,5)的距離約為16.55
- (101,20)->動作片(115,8)的距離約為18.44
- (101,20)->愛情片(5,89)的距離約為118.22
- (101,20)->愛情片(1,101)的距離約為128.69
通過計算可知,紅色圓點標記的電影到動作片 (108,5)的距離最近,為16.55。如果演算法直接根據這個結果,判斷該紅色圓點標記的電影為動作片,這個演算法就是最近鄰演算法,而非k-近鄰演算法。那麼k-鄰近演算法是什麼呢?k-近鄰演算法步驟如下:
- 計算已知類別資料集中的點與當前點之間的距離;
- 按照距離遞增次序排序;
- 選取與當前點距離最小的k個點;
- 確定前k個點所在類別的出現頻率;
- 返回前k個點所出現頻率最高的類別作為當前點的預測分類。
比如,現在我這個k值取3,那麼在電影例子中,按距離依次排序的三個點分別是動作片(108,5)、動作片(115,8)、愛情片(5,89)。在這三個點中,動作片出現的頻率為三分之二,愛情片出現的頻率為三分之一,所以該紅色圓點標記的電影為動作片。這個判別過程就是k-近鄰演算法。
1.3 Python3程式碼實現
我們已經知道了k-近鄰演算法的原理,那麼接下來就是使用Python3實現該演算法,依然以電影分類為例。
1.3.1 準備資料集
對於表1.1中的資料,我們可以使用numpy直接建立,程式碼如下:
# -*- coding: UTF-8 -*-
import numpy as np
"""
函式說明:建立資料集
Parameters:
無
Returns:
group - 資料集
labels - 分類標籤
Modify:
2017-07-13
"""
defcreateDataSet():
#四組二維特徵
group = np.array([[1,101],[5,89],[108,5],[115,8]])
#四組特徵的標籤
labels = ['愛情片','愛情片','動作片','動作片']
return group, labels
if __name__ == '__main__':
#建立資料集
group, labels = createDataSet()
#列印資料集
print(group)
print(labels)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
執行結果,如圖1.3所示:
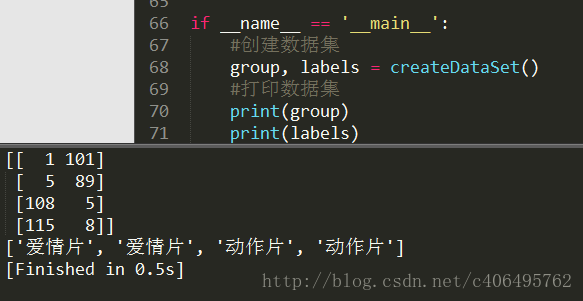 圖1.3 執行結果
圖1.3 執行結果
1.3.2 k-近鄰演算法
根據兩點距離公式,計算距離,選擇距離最小的前k個點,並返回分類結果。
# -*- coding: UTF-8 -*-
import numpy as np
import operator
"""
函式說明:kNN演算法,分類器
Parameters:
inX - 用於分類的資料(測試集)
dataSet - 用於訓練的資料(訓練集)
labes - 分類標籤
k - kNN演算法引數,選擇距離最小的k個點
Returns:
sortedClassCount[0][0] - 分類結果
Modify:
2017-07-13
"""
defclassify0(inX, dataSet, labels, k):
#numpy函式shape[0]返回dataSet的行數
dataSetSize = dataSet.shape[0]
#在列向量方向上重複inX共1次(橫向),行向量方向上重複inX共dataSetSize次(縱向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二維特徵相減後平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#開方,計算出距離
distances = sqDistances**0.5
#返回distances中元素從小到大排序後的索引值
sortedDistIndices = distances.argsort()
#定一個記錄類別次數的字典
classCount = {}
for i in range(k):
#取出前k個元素的類別
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定鍵的值,如果值不在字典中返回預設值。
#計算類別次數
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替換python2中的iteritems()
#key=operator.itemgetter(1)根據字典的值進行排序
#key=operator.itemgetter(0)根據字典的鍵進行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次數最多的類別,即所要分類的類別
return sortedClassCount[0][0]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
1.3.3 整體程式碼
這裡預測紅色圓點標記的電影(101,20)的類別,K-NN的k值為3。建立kNN_test01.py檔案,編寫程式碼如下:
# -*- coding: UTF-8 -*-
import numpy as np
import operator
"""
函式說明:建立資料集
Parameters:
無
Returns:
group - 資料集
labels - 分類標籤
Modify:
2017-07-13
"""
defcreateDataSet():
#四組二維特徵
group = np.array([[1,101],[5,89],[108,5],[115,8]])
#四組特徵的標籤
labels = ['愛情片','愛情片','動作片','動作片']
return group, labels
"""
函式說明:kNN演算法,分類器
Parameters:
inX - 用於分類的資料(測試集)
dataSet - 用於訓練的資料(訓練集)
labes - 分類標籤
k - kNN演算法引數,選擇距離最小的k個點
Returns:
sortedClassCount[0][0] - 分類結果
Modify:
2017-07-13
"""
defclassify0(inX, dataSet, labels, k):
#numpy函式shape[0]返回dataSet的行數
dataSetSize = dataSet.shape[0]
#在列向量方向上重複inX共1次(橫向),行向量方向上重複inX共dataSetSize次(縱向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二維特徵相減後平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#開方,計算出距離
distances = sqDistances**0.5
#返回distances中元素從小到大排序後的索引值
sortedDistIndices = distances.argsort()
#定一個記錄類別次數的字典
classCount = {}
for i in range(k):
#取出前k個元素的類別
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定鍵的值,如果值不在字典中返回預設值。
#計算類別次數
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替換python2中的iteritems()
#key=operator.itemgetter(1)根據字典的值進行排序
#key=operator.itemgetter(0)根據字典的鍵進行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次數最多的類別,即所要分類的類別
return sortedClassCount[0][0]
if __name__ == '__main__':
#建立資料集
group, labels = createDataSet()
#測試集
test = [101,20]
#kNN分類
test_class = classify0(test, group, labels, 3)
#列印分類結果
print(test_class)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
執行結果,如圖1.4所示:
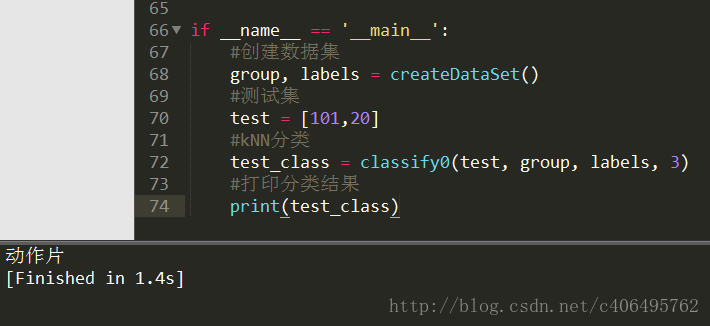 圖1.4 執行結果
圖1.4 執行結果
可以看到,分類結果根據我們的”經驗”,是正確的,儘管這種分類比較耗時,用時1.4s。
到這裡,也許有人早已經發現,電影例子中的特徵是2維的,這樣的距離度量可以用兩 點距離公式計算,但是如果是更高維的呢?對,沒錯。我們可以用歐氏距離(也稱歐幾里德度量),如圖1.5所示。我們高中所學的兩點距離公式就是歐氏距離在二維空間上的公式,也就是歐氏距離的n的值為2的情況。
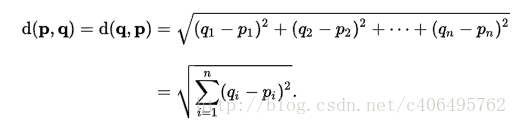 圖1.5 歐氏距離公式
圖1.5 歐氏距離公式
看到這裡,有人可能會問:“分類器何種情況下會出錯?”或者“答案是否總是正確的?”答案是否定的,分類器並不會得到百分百正確的結果,我們可以使用多種方法檢測分類器的正確率。此外分類器的效能也會受到多種因素的影響,如分類器設定和資料集等。不同的演算法在不同資料集上的表現可能完全不同。為了測試分類器的效果,我們可以使用已知答案的資料,當然答案不能告訴分類器,檢驗分類器給出的結果是否符合預期結果。通過大量的測試資料,我們可以得到分類器的錯誤率-分類器給出錯誤結果的次數除以測試執行的總數。錯誤率是常用的評估方法,主要用於評估分類器在某個資料集上的執行效果。完美分類器的錯誤率為0,最差分類器的錯誤率是1.0。同時,我們也不難發現,k-近鄰演算法沒有進行資料的訓練,直接使用未知的資料與已知的資料進行比較,得到結果。因此,可以說k-鄰近演算法不具有顯式的學習過程。
二 k-近鄰演算法實戰之約會網站配對效果判定
上一小結學習了簡單的k-近鄰演算法的實現方法,但是這並不是完整的k-近鄰演算法流程,k-近鄰演算法的一般流程:
- 收集資料:可以使用爬蟲進行資料的收集,也可以使用第三方提供的免費或收費的資料。一般來講,資料放在txt文字檔案中,按照一定的格式進行儲存,便於解析及處理。
- 準備資料:使用Python解析、預處理資料。
- 分析資料:可以使用很多方法對資料進行分析,例如使用Matplotlib將資料視覺化。
- 測試演算法:計算錯誤率。
- 使用演算法:錯誤率在可接受範圍內,就可以執行k-近鄰演算法進行分類。
已經瞭解了k-近鄰演算法的一般流程,下面開始進入實戰內容。
2.1 實戰背景
海倫女士一直使用線上約會網站尋找適合自己的約會物件。儘管約會網站會推薦不同的任選,但她並不是喜歡每一個人。經過一番總結,她發現自己交往過的人可以進行如下分類:
- 不喜歡的人
- 魅力一般的人
- 極具魅力的人
海倫收集約會資料已經有了一段時間,她把這些資料存放在文字檔案datingTestSet.txt中,每個樣本資料佔據一行,總共有1000行。
海倫收集的樣本資料主要包含以下3種特徵:
- 每年獲得的飛行常客里程數
- 玩視訊遊戲所消耗時間百分比
- 每週消費的冰淇淋公升數
這裡不得不吐槽一句,海倫是個小吃貨啊,冰淇淋公斤數都影響自己擇偶標準。開啟txt文字檔案,資料格式如圖2.1所示。
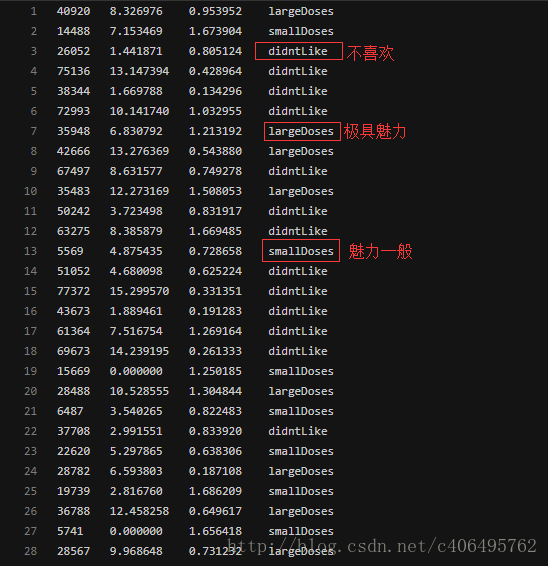 圖2.1 datingTestSet.txt格式
圖2.1 datingTestSet.txt格式
2.2 準備資料:資料解析
在將上述特徵資料輸入到分類器前,必須將待處理的資料的格式改變為分類器可以接收的格式。分類器接收的資料是什麼格式的?從上小結已經知道,要將資料分類兩部分,即特徵矩陣和對應的分類標籤向量。在kNN_test02.py檔案中建立名為file2matrix的函式,以此來處理輸入格式問題。 將datingTestSet.txt放到與kNN_test02.py相同目錄下,編寫程式碼如下:
# -*- coding: UTF-8 -*-
import numpy as np
"""
函式說明:開啟並解析檔案,對資料進行分類:1代表不喜歡,2代表魅力一般,3代表極具魅力
Parameters:
filename - 檔名
Returns:
returnMat - 特徵矩陣
classLabelVector - 分類Label向量
Modify:
2017-03-24
"""
deffile2matrix(filename):
#開啟檔案
fr = open(filename)
#讀取檔案所有內容
arrayOLines = fr.readlines()
#得到檔案行數
numberOfLines = len(arrayOLines)
#返回的NumPy矩陣,解析完成的資料:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3))
#返回的分類標籤向量
classLabelVector = []
#行的索引值
index = 0
for line in arrayOLines:
#s.strip(rm),當rm空時,預設刪除空白符(包括'\n','\r','\t',' ')
line = line.strip()
#使用s.split(str="",num=string,cout(str))將字串根據'\t'分隔符進行切片。
listFromLine = line.split('\t')
#將資料前三列提取出來,存放到returnMat的NumPy矩陣中,也就是特徵矩陣
returnMat[index,:] = listFromLine[0:3]
#根據文字中標記的喜歡的程度進行分類,1代表不喜歡,2代表魅力一般,3代表極具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
"""
函式說明:main函式
Parameters:
無
Returns:
無
Modify:
2017-03-24
"""
if __name__ == '__main__':
#開啟的檔名
filename = "datingTestSet.txt"
#開啟並處理資料
datingDataMat, datingLabels = file2matrix(filename)
print(datingDataMat)
print(datingLabels)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
執行上述程式碼,得到的資料解析結果如圖2.2所示。
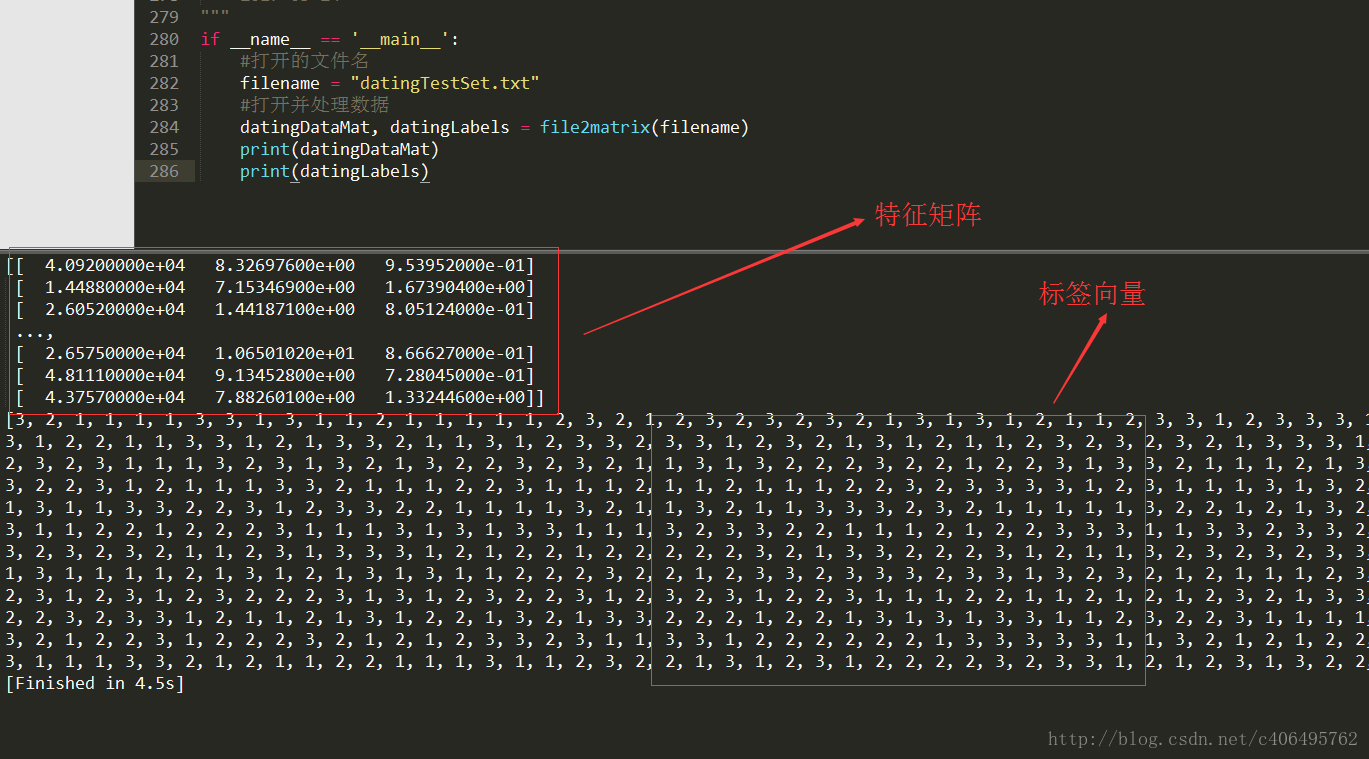 圖2.2 資料解析結果
圖2.2 資料解析結果
可以看到,我們已經順利匯入資料,並對資料進行解析,格式化為分類器需要的資料格式。接著我們需要了解資料的真正含義。可以通過友好、直觀的圖形化的方式觀察資料。
2.3 分析資料:資料視覺化
在kNN_test02.py檔案中編寫名為showdatas的函式,用來將資料視覺化。編寫程式碼如下:
# -*- coding: UTF-8 -*-
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
import numpy as np
"""
函式說明:開啟並解析檔案,對資料進行分類:1代表不喜歡,2代表魅力一般,3代表極具魅力
Parameters:
filename - 檔名
Returns:
returnMat - 特徵矩陣
classLabelVector - 分類Label向量
Modify:
2017-03-24
"""
deffile2matrix(filename):
#開啟檔案
fr = open(filename)
#讀取檔案所有內容
arrayOLines = fr.readlines()
#得到檔案行數
numberOfLines = len(arrayOLines)
#返回的NumPy矩陣,解析完成的資料:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3))
#返回的分類標籤向量
classLabelVector = []
#行的索引值
index = 0
for line in arrayOLines:
#s.strip(rm),當rm空時,預設刪除空白符(包括'\n','\r','\t',' ')
line = line.strip()
#使用s.split(str="",num=string,cout(str))將字串根據'\t'分隔符進行切片。
listFromLine = line.split('\t')
#將資料前三列提取出來,存放到returnMat的NumPy矩陣中,也就是特徵矩陣
returnMat[index,:] = listFromLine[0:3]
#根據文字中標記的喜歡的程度進行分類,1代表不喜歡,2代表魅力一般,3代表極具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
"""
函式說明:視覺化資料
Parameters:
datingDataMat - 特徵矩陣
datingLabels - 分類Label
Returns:
無
Modify:
2017-03-24
"""
defshowdatas(datingDataMat, datingLabels):
#設定漢字格式
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
#將fig畫布分隔成1行1列,不共享x軸和y軸,fig畫布的大小為(13,8)
#當nrow=2,nclos=2時,代表fig畫布被分為四個區域,axs[0][0]表示第一行第一個區域
fig, axs = plt.subplots(nrows=2, ncols=2,sharex=False, sharey=False, figsize=(13,8))
numberOfLabels = len(datingLabels)
LabelsColors = []
for i in datingLabels:
if i == 1:
LabelsColors.append('black')
if i == 2:
LabelsColors.append('orange')
if i == 3:
LabelsColors.append('red')
#畫出散點圖,以datingDataMat矩陣的第一(飛行常客例程)、第二列(玩遊戲)資料畫散點資料,散點大小為15,透明度為0.5
axs[0][0].scatter(x=datingDataMat[:,0], y=datingDataMat[:,1], color=LabelsColors,s=15, alpha=.5)
#設定標題,x軸label,y軸label
axs0_title_text = axs[0][0].set_title(u'每年獲得的飛行常客里程數與玩視訊遊戲所消耗時間佔比',FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年獲得的飛行常客里程數',FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩視訊遊戲所消耗時間佔',FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')
#畫出散點圖,以datingDataMat矩陣的第一(飛行常客例程)、第三列(冰激凌)資料畫散點資料,散點大小為15,透明度為0.5
axs[0][1].scatter(x=datingDataMat[:,0], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#設定標題,x軸label,y軸label
axs1_title_text = axs[0][1].set_title(u'每年獲得的飛行常客里程數與每週消費的冰激淋公升數',FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年獲得的飛行常客里程數',FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每週消費的冰激淋公升數',FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')
#畫出散點圖,以datingDataMat矩陣的第二(玩遊戲)、第三列(冰激凌)資料畫散點資料,散點大小為15,透明度為0.5
axs[1][0].scatter(x=datingDataMat[:,1], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#設定標題,x軸label,y軸label
axs2_title_text = axs[1][0].set_title(u'玩視訊遊戲所消耗時間佔比與每週消費的冰激淋公升數',FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩視訊遊戲所消耗時間佔比',FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每週消費的冰激淋公升數',FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
#設定圖例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
#新增圖例
axs[0][0].legend(handles=[didntLike,smallDoses,largeDoses])
axs[0][1].legend(handles=[didntLike,smallDoses,largeDoses])
axs[1][0].legend(handles=[didntLike,smallDoses,largeDoses])
#顯示圖片
plt.show()
"""
函式說明:main函式
Parameters:
無
Returns:
無
Modify:
2017-03-24
"""
if __name__ == '__main__':
#開啟的檔名
filename = "datingTestSet.txt"
#開啟並處理資料
datingDataMat, datingLabels = file2matrix(filename)
showdatas(datingDataMat, datingLabels)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
執行上述程式碼,可以看到視覺化結果如圖2.3所示。
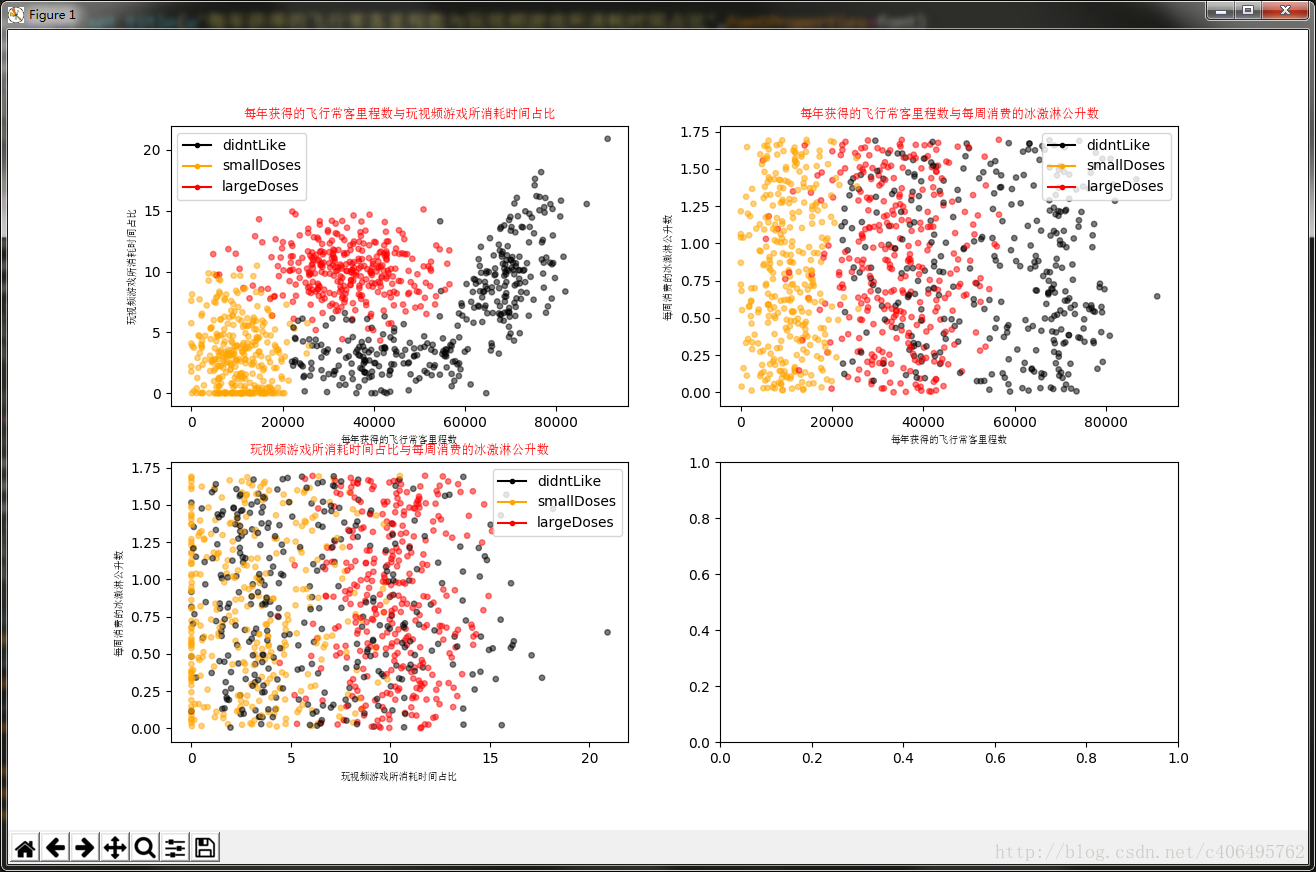 圖2.3 資料視覺化結果
點選檢視大圖
圖2.3 資料視覺化結果
點選檢視大圖
通過資料可以很直觀的發現數據的規律,比如以玩遊戲所消耗時間佔比與每年獲得的飛行常客里程數,只考慮這二維的特徵資訊,給我的感覺就是海倫喜歡有生活質量的男人。為什麼這麼說呢?每年獲得的飛行常客里程數表明,海倫喜歡能享受飛行常客獎勵計劃的男人,但是不能經常坐飛機,疲於奔波,滿世界飛。同時,這個男人也要玩視訊遊戲,並且佔一定時間比例。能到處飛,又能經常玩遊戲的男人是什麼樣的男人?很顯然,有生活質量,並且生活悠閒的人。我的分析,僅僅是通過視覺化的資料總結的個人看法。我想,每個人的感受應該也是不盡相同。
2.4 準備資料:資料歸一化
表2.1給出了四組樣本,如果想要計算樣本3和樣本4之間的距離,可以使用尤拉公式計算。
| 樣本 | 玩遊戲所耗時間百分比 | 每年獲得的飛行常用里程數 | 每週消費的冰淇淋公升數 | 樣本分類 |
|---|---|---|---|---|
| 1 | 0.8 | 400 | 0.5 | 1 |
| 2 | 12 | 134000 | 0.9 | 3 |
| 3 | 0 | 20000 | 1.1 | 2 |
| 4 | 67 | 32000 | 0.1 | 2 |
計算方法如圖2.4所示。
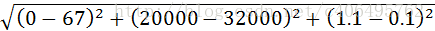 圖2.4 計算公式
圖2.4 計算公式
我們很容易發現,上面方程中數字差值最大的屬性對計算結果的影響最大,也就是說,每年獲取的飛行常客里程數對於計算結果的影響將遠遠大於表2.1中其他兩個特徵-玩視訊遊戲所耗時間佔比和每週消費冰淇淋公斤數的影響。而產生這種現象的唯一原因,僅僅是因為飛行常客里程數遠大於其他特徵值。但海倫認為這三種特徵是同等重要的,因此作為三個等權重的特徵之一,飛行常客里程數並不應該如此嚴重地影響到計算結果。
在處理這種不同取值範圍的特徵值時,我們通常採用的方法是將數值歸一化,如將取值範圍處理為0到1或者-1到1之間。下面的公式可以將任意取值範圍的特徵值轉化為0到1區間內的值:
newValue = (oldValue - min) / (max - min)- 1
其中min和max分別是資料集中的最小特徵值和最大特徵值。雖然改變數值取值範圍增加了分類器的複雜度,但為了得到準確結果,我們必須這樣做。在kNN_test02.py檔案中編寫名為autoNorm的函式,用該函式自動將資料歸一化。程式碼如下:
# -*- coding: UTF-8 -*-
import numpy as np
"""
函式說明:開啟並解析檔案,對資料進行分類:1代表不喜歡,2代表魅力一般,3代表極具魅力
Parameters:
filename - 檔名
Returns:
returnMat - 特徵矩陣
classLabelVector - 分類Label向量
Modify:
2017-03-24
"""
deffile2matrix(filename):
#開啟檔案
fr = open(filename)
#讀取檔案所有內容
arrayOLines = fr.readlines()
#得到檔案行數
numberOfLines = len(arrayOLines)
#返回的NumPy矩陣,解析完成的資料:numberOfLines行,3列
returnMat = np.zeros((numberOfLines,3))
#返回的分類標籤向量
classLabelVector = []
#行的索引值
index = 0
for line in arrayOLines:
#s.strip(rm),當rm空時,預設刪除空白符(包括'\n','\r','\t',' ')
line = line.strip()
#使用s.split(str="",num=string,cout(str))將字串根據'\t'分隔符進行切片。
listFromLine = line.split('\t')
#將資料前三列提取出來,存放到returnMat的NumPy矩陣中,也就是特徵矩陣
returnMat[index,:] = listFromLine[0:3]
#根據文字中標記的喜歡的程度進行分類,1代表不喜歡,2代表魅力一般,3代表極具魅力
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index += 1
return returnMat, classLabelVector
"""
函式說明:對資料進行歸一化
Parameters:
dataSet - 特徵矩陣
Returns:
normDataSet - 歸一化後的特徵矩陣
ranges - 資料範圍
minVals - 資料最小值
Modify:
2017-03-24
"""
defautoNorm
相關推薦
機器學習——KNN演算法以及案例預測入住位置
ķ最近鄰
KNN分類演算法其核心思想是假定所有的資料物件都對應於Ñ維空間中的點,如果一個數據物件在特徵空間中的ķ個最相鄰物件中的大多數屬於某一個類別,則該物件也屬於這個類別,並具有這個類別上樣本的特性.KNN方法在進行類別決策時,只與極少量的相鄰樣本有關。
定義:如果一個樣本在特徵空間中的ķ
機器學習 KNN演算法原理
K近鄰(K-nearst neighbors,KNN)是一種基本的機器學習演算法,所謂k近鄰,就是k個最近的鄰居的意思,說的是每個樣本都可以用它最接近的k個鄰居來代表。比如:判斷一個人的人品,只需要觀察與他來往最密切的幾個人的人品好壞就可以得出,即“近朱者赤,近墨者黑”;KNN演算法既可以應用於分類應用中,也
機器學習KNN演算法
轉載請註明作者和出處:http://blog.csdn.net/c406495762
執行平臺: Windows
Python版本:
吳裕雄 python 機器學習-KNN演算法(1)
import numpy as np
import operator as op
from os import listdir
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat
[機器學習]kNN演算法python實現(例項:數字識別)
# 使用好任何機器學習演算法的前提是選好Featuresfrom numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
data
機器學習 -- kNN演算法
K近鄰演算法
什麼是K近鄰演算法
何謂K近鄰演算法,即K-Nearest Neighbor algorithm,簡稱KNN演算法。單從名字來猜想,可以簡單的認為:K個最近的鄰居。當K=1時,演算法便成了尋找最近的那個鄰居。
用官方的話來說,所
機器學習-KNN演算法
一、演算法介紹
KNN演算法中文名稱叫做K近鄰演算法,是眾多機器學習演算法裡面最基礎入門的演算法。它是一個有監督的機器學習演算法,既可以用來做分類任務也可以用來做迴歸任務。KNN演算法的核心思想是未標記的樣本的類別,由距離他最近的K個鄰居投票來決定。下面我們來看個例子加深理解一下:
如上圖所描述張三
機器學習的演算法knn,貝葉斯,決策樹
sklearn資料集與估計器
資料集劃分
機器學習一般的資料集會劃分為兩個部分:
訓練資料:用於訓練,構建模型
測試資料:在模型檢驗時使用,用於評估模型是否有效
資料集劃分API
sklearn.model_selection.train_test_split
機器學習實戰第二章——學習KNN演算法,讀書筆記
K近鄰演算法(簡稱KNN)學習是一種常用的監督學習方法,給定測試樣本,基於某種距離度量找出訓練集中與其最靠近的k個訓練樣本,然後基於這k個“鄰居”的資訊來進行預測。通常在分類任務中可以使用“投票法”,即
機器學習經典演算法詳解及Python實現--K近鄰(KNN)演算法
轉載http://blog.csdn.net/suipingsp/article/details/41964713
(一)KNN依然是一種監督學習演算法
KNN(K Nearest Neighbors,K近鄰 )演算法是機器學習所有演算法中理論最簡單,最好理解的。KNN
機器學習-KNN分類演算法Iris例項
概念
python知識點
KNN例項
# -*- coding: utf-8 -*-
"""
Created on Sat Mar 5 09:55:02 2016
@au
機器學習系列演算法1:KNN
思路:空間上距離相近的點具有相似的特徵屬性。
執行流程:
•1. 從訓練集合中獲取K個離待預測樣本距離最近的樣本資料; •2. 根據獲取得到的K個樣本資料來預測當前待預測樣本的目標屬性值
三要素:K值選擇/距離度量(歐式距離)/決策選擇(平均值/
機器學習經典演算法之KNN
一、前言
KNN 的英文叫 K-Nearest Neighbor,應該算是資料探勘演算法中最簡單的一種。
先用一個例子體會下。
/*請尊重作者勞動成果,轉載請標明原文連結:*/
/* https://www.cnblogs.com/jpcflyer/p/11111817.html * /
假設,我們想對電
機器學習-KNN分類器
pos show sha key borde 不同 簡單的 測試 solid 1. K-近鄰(k-Nearest Neighbors,KNN)的原理
通過測量不同特征值之間的距離來衡量相似度的方法進行分類。
2. KNN算法過程
訓練樣本集:樣本集中每個特征值都
機器學習-KNN算法
訓練集 nbsp 線性分類 但是 測試 優點 http 進行 inf 原理
KNN算法,又叫K近鄰算法。就是在訓練集中數據和標簽已知的情況下,輸入測試數據,將測試數據的特征與訓練集中對應的特征進行相互比較,找到訓練集中與之最為相似的前K個數據,則該測試數據對應的類別就是K個
機器學習——KNN
load -s 創建 數據 sklearn lac bsp otl 訓練數據 導入類庫
1 import numpy as np
2 from sklearn.neighbors import KNeighborsClassifier
3 from sklearn.
機器學習開源演算法庫
C++計算機視覺
CCV —基於C語言/提供快取/核心的機器視覺庫,新穎的機器視覺庫
OpenCV—它提供C++, C, Python, Java 以及 MATLAB介面,並支援Windows, Linux, Android and Mac OS作業系統。
吳恩達機器學習 - PCA演算法降維 吳恩達機器學習 - PCA演算法降維
原
吳恩達機器學習 - PCA演算法降維
2018年06月25日 13:08:17
離殤灬孤狼
閱讀數:152
更多
給找機器學習/演算法崗工作的同學們的一些建議
轉自:https://bbs.pku.edu.cn/v2/post-read.php?bid=99&threadid=16510824
本人是數院統計專業畢業,在某大公司做演算法方面的工作,面試過不少人。
有不少學弟學妹找我諮詢過機器學習/演算法方
【機器學習經典演算法梳理】一.線性迴歸
【機器學習經典演算法梳理】是一個專門梳理幾大經典機器學習演算法的部落格。我在這個系列部落格中,爭取用最簡練的語言、較簡潔的數學公式,和清晰成體系的提綱,來盡我所能,對於演算法進行詳盡的梳理。【機器學習經典演算法梳理】系列部落格對於機器學習演算法的梳理,將從“基本思想”、“基本形式”、“過程推導”、“