
Spark:Driver和Job,Stage概念
Driver Program, Job和Stage是Spark中的幾個基本概念。Spark官方文件中對於這幾個概念的解釋比較簡單,對於初學者很難正確理解他們的涵義。
官方解釋如下(http://spark.apache.org/docs/latest/cluster-overview.html): Driver Program: 執行應用程式的main()函式並建立SparkContext的過程. Job:由多個任務組成的平行計算,這些任務在Spark操作(例如儲存、收集)下生成;您將在驅動程式日誌中看到這個術語。. Stage: 每個作業被劃分為更小的任務集,稱為相互依賴的階段(類似於MapReduce中的map和reduce階段);您將在驅動程式日誌中看到這個術語。
看起來很抽象對不對?反正我看完後對於這幾個概念還是一頭霧水。於是Yahoo了一下,在stackoverflow上看到一篇帖子問了類似的問題。下面有好心人舉了一個簡單易懂的例子,解釋了這幾個概念的區別。
我簡單整理了一下,方便大家參考。
例子:
術語總是難以理解的,因為它取決於所處的上下文。在很多情況下,你可能習慣於“將Job提交給一個cluster”,但是對於spark而言卻是提交了一個driver程式。
也就是說,對於Job,spark有它自己的定義,如下: A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs.
在這個例子中,假設你需要做如下一些事情: 1. 將一個包含人名和地址的檔案載入到RDD1中 2. 將一個包含人名和電話的檔案載入到RDD2中 3. 通過name來Join RDD1和RDD2,生成RDD3 4. 在RDD3上做Map,給每個人生成一個HTML展示卡作為RDD4 5. 將RDD4儲存到檔案 6. 在RDD1上做Map,從每個地址中提取郵編,結果生成RDD5 7. 在RDD5上做聚合,計算出每個郵編地區中生活的人數,結果生成RDD6 8. Collect RDD6,並且將這些統計結果輸出到stdout
為了方便說明,我將這個例子整理成如下的一張示意圖:
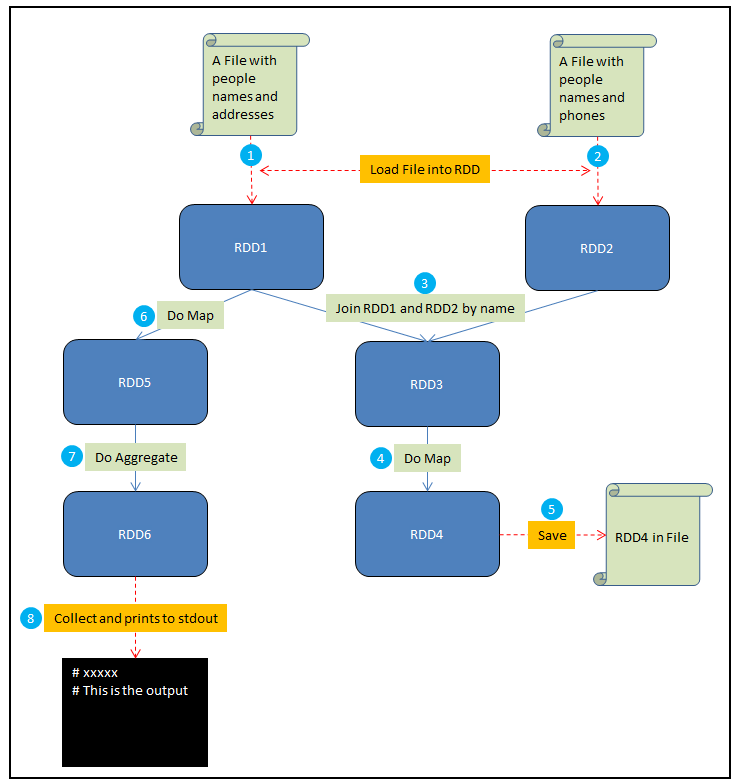
其中紅色虛線表示輸入和輸出,藍色實線是對RDD的操作,圓圈中的數字對應了以上的8個步驟。接下來解釋driver program, job和stage這幾個概念:
- Driver program是全部的程式碼,執行所有的8個步驟。
- 第五步中的save和第八步中的collect都是Spark Job。Spark中每個action對應著一個Job,transformation不是Job。
- 其他的步驟(1、2、3、4、6、7)被Spark組織成stages,每個job則是一些stage序列的結果。對於一些簡單的場景,一個job可以只有一個stage。但是對於資料重分割槽的需求(比如第三步中的join),或者任何破壞資料局域性的事件,通常會導致更多的stage。可以將stage看作是能夠產生中間結果的計算。這種計算可以被持久化,比如可以把RDD1持久化來避免重複計算。
- 以上全部三個概念解釋了某個演算法被拆分的邏輯。相比之下,task是一個特定的資料片段,在給定的executor上,它可以跨越某個特定的stage。
到了這裡,很多概念就清楚了。驅動程式就是執行了一個Spark Application的main函式和建立Spark Context的程序,它包含了這個application的全部程式碼。Spark Application中的每個action會被Spark作為Job進行排程。每個Job是一個計算序列的最終結果,而這個序列中能夠產生中間結果的計算就是一個stage。
再回過頭來看一下Spark Programming Guide,對於Transformations和Actions是有著明確區分的。通常Action對應了Job,而Transformation對應了Stage:
Action列表:
- reduce
- collect
- count
- first
- take
- takeSample
- takeOrdered
- saveAsTextFile
- saveAsSequenceFile
- saveAsObjectFile
- countByKey
- foreach
Transformation列表:
- map
- filter
- flatMap
- mapPartitions
- mapPartitionsWithIndex
- sample
- union
- intersection
- distinct
- groupByKey
- reduceByKey
- aggregateByKey
- sortByKey
- join
- cogroup
- cartesian
- pipe
- coalesce
- repartition
- repartitionAndSortWithinPartitions
至於task,官方文件中是這麼說的:Task is a unit of work that will be sent to one executor。再結合官方對Stage的解釋,可以這樣理解: 一個Job被拆分成若干個Stage,每個Stage執行一些計算,產生一些中間結果。它們的目的是最終生成這個Job的計算結果。而每個Stage是一個task set,包含若干個task。Task是Spark中最小的工作單元,在一個executor上完成一個特定的事情。