Spark中Task,Partition,RDD、節點數、Executor數、core數目的關係和Application,Driver,Job,Task,Stage理解
梳理一下Spark中關於併發度涉及的幾個概念File,Block,Split,Task,Partition,RDD以及節點數、Executor數、core數目的關係。
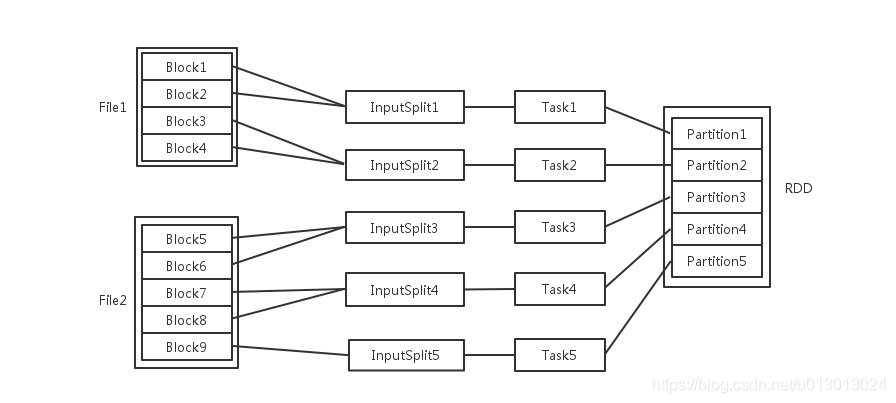
輸入可能以多個檔案的形式儲存在HDFS上,每個File都包含了很多塊,稱為Block。
當Spark讀取這些檔案作為輸入時,會根據具體資料格式對應的InputFormat進行解析,一般是將若干個Block合併成一個輸入分片,稱為InputSplit,注意InputSplit不能跨越檔案。
隨後將為這些輸入分片生成具體的Task。InputSplit與Task是一一對應的關係。
隨後這些具體的Task每個都會被分配到叢集上的某個節點的某個Executor
- 每個節點可以起一個或多個Executor。
- 每個Executor由若干core組成,每個Executor的每個core一次只能執行一個Task。
- 每個Task執行的結果就是生成了目標RDD的一個partiton。
注意: 這裡的core是虛擬的core而不是機器的物理CPU核,可以理解為就是Executor的一個工作執行緒。
而 Task被執行的併發度 = Executor數目 * 每個Executor核數。
至於partition的數目:
- 對於資料讀入階段,例如sc.textFile,輸入檔案被劃分為多少InputSplit就會需要多少初始Task。
- 在Map階段partition數目保持不變。
- 在Reduce階段,RDD的聚合會觸發shuffle操作,聚合後的RDD的partition數目跟具體操作有關,例如repartition操作會聚合成指定分割槽數,還有一些運算元是可配置的。
1,Application
application(應用)其實就是用spark-submit提交的程式。比方說spark examples中的計算pi的SparkPi。一個application通常包含三部分:從資料來源(比方說HDFS)取資料形成RDD,通過RDD的transformation和action進行計算,將結果輸出到console或者外部儲存(比方說collect收集輸出到console)。
2,Driver
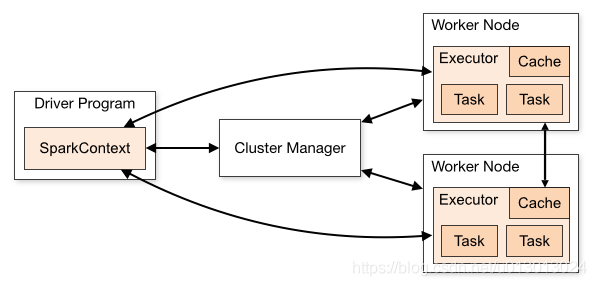
Spark中的driver感覺其實和yarn中Application Master的功能相類似。主要完成任務的排程以及和executor和cluster manager進行協調。有client和cluster聯眾模式。client模式driver在任務提交的機器上執行,而cluster模式會隨機選擇機器中的一臺機器啟動driver。從spark官網截圖的一張圖可以大致瞭解driver的功能。
3,Job
Spark中的Job和MR中Job不一樣不一樣。MR中Job主要是Map或者Reduce Job。而Spark的Job其實很好區別,一個action運算元就算一個Job,比方說count,first等。
4, Task
Task是Spark中最新的執行單元。RDD一般是帶有partitions的,每個partition的在一個executor上的執行可以任務是一個Task。
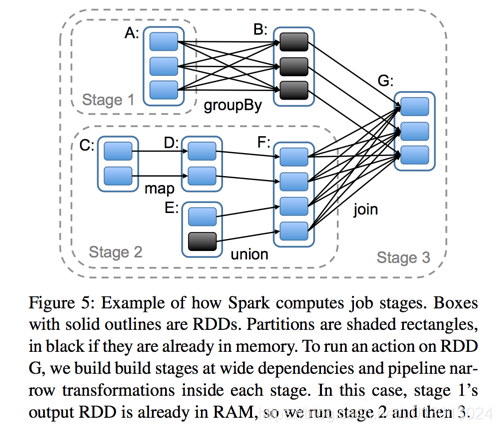
5, Stage
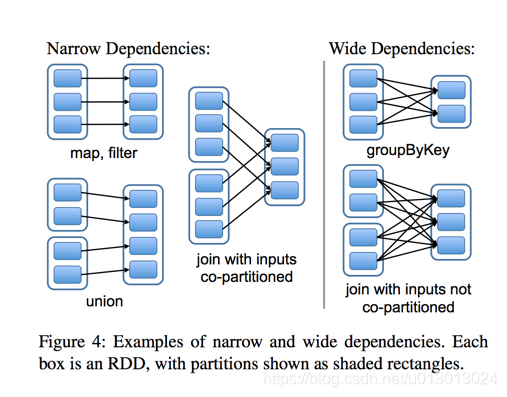
Stage概念是spark中獨有的。一般而言一個Job會切換成一定數量的stage。各個stage之間按照順序執行。至於stage是怎麼切分的,首選得知道spark論文中提到的narrow dependency(窄依賴)和wide dependency( 寬依賴)的概念。其實很好區分,看一下父RDD中的資料是否進入不同的子RDD,如果只進入到一個子RDD則是窄依賴,否則就是寬依賴。寬依賴和窄依賴的邊界就是stage的劃分點