
MapReduce:原理之Word Count 以及Java實現
為什麼要設定記憶體緩衝區?
批量收集map的結果,減少磁碟IO次數,提高效率。
磁碟檔案要寫到哪裡?
寫磁碟將按照輪詢方式寫到mapred.local.dir屬性指定的作業特定子目錄的目錄中。也就是存放在TaskTracker夠得著的某個本地目錄,每一個reduce task不斷通過RPC從JobTracker中獲取map task是否完成的資訊,如果reduce task得到通知,獲知某臺TaskTracker上的map task完成,Shuffle的後半段就開始了。
所有的合併究竟是為了什麼?
因為map節點和reduce節點之間的資料拷貝是通過網路進行拷貝的,資料量越小,拷貝的越快,相應的處理也就越快,那個,合併的目的就是減少map的輸出資料量,是網路拷貝儘可能快。
需要特殊說明的是,以上的步驟,都是在本地機器上完成,並不需要通過網路進行資料的傳輸。
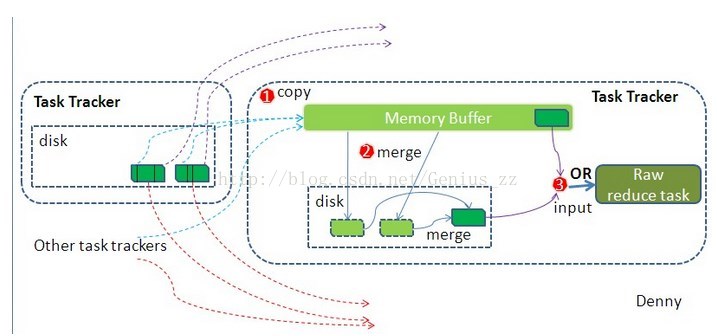
reduce段的Shuffle細節:
(1) copy階段
reduce程序啟動一些資料的copy執行緒,這個執行緒叫做fetcher執行緒,通過http方式請求map task所在的TaskTracker,來獲取map task的輸出資料。
reduce拷貝資料,不是進行隨意的拷貝,之前的partition,已經將資料分好區,reduce只是拷貝各個map上分割給自己的那一部分資料,拷貝到本地後,從每一個map上拷貝過來的資料都是一個小檔案,也是需要對這些小檔案進行合併的。合併以後,輸出到reduce進行處理。
Word Count 為例,結合程式碼分析:
Map過程需要繼承org.apache.hadoop.mapreduce包中Mapper類,並重寫其map方法。
通過在map方法中新增兩句把key值和value值輸出到控制檯的程式碼,可以發現map方法中value值儲存的是文字檔案中的一行(以回車符為行結束標記),而key值為該行的首字母相對於文字檔案的首地址的偏移量。
然後StringTokenizer類將每一行拆分成為一個個的單詞,並將作為map方法的結果輸出,其餘的工作都交有MapReduce框架處理。
Reduce過程需要繼承org.apache.hadoop.mapreduce包中Reducer
Map過程輸出中key為單個單詞,而values是對應單詞的計數值所組成的列表,Map的輸出就是Reduce的輸入,所以reduce方法只要遍歷values並求和,即可得到某個單詞的總次數。
在MapReduce中,由Job物件負責管理和執行一個計算任務,並通過Job的一些方法對任務的引數進行相關的設定。
此處設定了使用TokenizerMapper完成Map過程中的處理和使用IntSumReducer完成Combine和Reduce過程中的處理。還設定了Map過程和Reduce過程的輸出型別:key的型別為Text,value的型別為IntWritable。
任務的輸出和輸入路徑則由命令列引數指定,並由FileInputFormat和FileOutputFormat分別設定。完成相應任務的引數設定後,即可呼叫job.waitForCompletion()方法執行任務。
Hadoop提供瞭如下內容的資料型別,這些資料型別都實現了WritableComparable介面,以便用這些型別定義的資料可以被序列化進行網路傳輸和檔案儲存,以及進行大小比較。
| package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount "); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } |
BooleanWritable:標準布林型數值
ByteWritable:單位元組數值
DoubleWritable:雙位元組數
FloatWritable:浮點數
IntWritable:整型數
LongWritable:長整型數
Text:使用UTF8格式儲存的文字
NullWritable:當中的key或value為空時使用