
美團推薦演算法實踐
前言
推薦系統並不是新鮮的事物,在很久之前就存在,但是推薦系統真正進入人們的視野,並且作為一個重要的模組存在於各個網際網路公司,還是近幾年的事情。
隨著網際網路的深入發展,越來越多的資訊在網際網路上傳播,產生了嚴重的資訊過載。如果不採用一定的手段,使用者很難從如此多的資訊流中找到對自己有價值的資訊。
解決資訊過載有幾種手段:一種是搜尋,當用戶有了明確的資訊需求意圖後,將意圖轉換為幾個簡短的詞或者短語的組合(即query),然後將這些詞或短語組合提交到相應的搜尋引擎,再由搜尋引擎在海量的資訊庫中檢索出與query相關的資訊返回給使用者;另外一種是推薦,很多時候使用者的意圖並不是很明確,或者很難用清晰的語義表達,有時甚至連使用者自己都不清楚自己的需求,這種情況下搜尋就顯得捉襟見肘了。尤其是近些年來,隨著電子商務的興起,使用者並非一定是帶著明確的購買意圖去瀏覽,很多時候是去“逛”的,這種情景下解決資訊過載,理解使用者意圖,為使用者推送個性化的結果,推薦系統便是一種比較好的選擇。
美團作為國內發展較快的o2o網站,有著大量的使用者和豐富的使用者行為,這些為推薦系統的應用和優化提供了不可或缺的條件,接下來介紹我們在推薦系統的構建和優化過程中的一些做法,與大家共享。
框架

從框架的角度看,推薦系統基本可以分為資料層、觸發層、融合過濾層和排序層。資料層包括資料生成和資料儲存,主要是利用各種資料處理工具對原始日誌進行清洗,處理成格式化的資料,落地到不同型別的儲存系統中,供下游的演算法和模型使用。候選集觸發層主要是從使用者的歷史行為、實時行為、地理位置等角度利用各種觸發策略產生推薦的候選集。候選集融合和過濾層有兩個功能,一是對出發層產生的不同候選集進行融合,提高推薦策略的覆蓋度和精度;另外還要承擔一定的過濾職責,從產品、運營的角度確定一些人工規則,過濾掉不符合條件的item。排序層主要是利用機器學習的模型對觸發層篩選出來的候選集進行重排序。
同時,對與候選集觸發和重排序兩層而言,為了效果迭代是需要頻繁修改的兩層,因此需要支援ABtest。為了支援高效率的迭代,我們對候選集觸發和重排序兩層進行了解耦,這兩層的結果是正交的,因此可以分別進行對比試驗,不會相互影響。同時在每一層的內部,我們會根據使用者將流量劃分為多份,支援多個策略同時線上對比。
資料應用
資料乃演算法、模型之本。美團作為一個交易平臺,同時具有快速增長的使用者量,因此產生了海量豐富的使用者行為資料。當然,不同型別的資料的價值和反映的使用者意圖的強弱也有所不同。

- 使用者主動行為資料記錄了使用者在美團平臺上不同的環節的各種行為,這些行為一方面用於候選集觸發演算法(在下一部分介紹)中的離線計算(主要是瀏覽、下單),另外一方面,這些行為代表的意圖的強弱不同,因此在訓練重排序模型時可以針對不同的行為設定不同的迴歸目標值,以更細地刻畫使用者的行為強弱程度。此外,使用者對deal的這些行為還可以作為重排序模型的交叉特徵,用於模型的離線訓練和線上預測。
- 負反饋資料反映了當前的結果可能在某些方面不能滿足使用者的需求,因此在後續的候選集觸發過程中需要考慮對特定的因素進行過濾或者降權,降低負面因素再次出現的機率,提高使用者體驗;同時在重排序的模型訓練中,負反饋資料可以作為不可多得的負例參與模型訓練,這些負例要比那些展示後未點選、未下單的樣本顯著的多。
- 使用者畫像是刻畫使用者屬性的基礎資料,其中有些是直接獲取的原始資料,有些是經過挖掘的二次加工資料,這些屬性一方面可以用於候選集觸發過程中對deal進行加權或降權,另外一方面可以作為重排序模型中的使用者維度特徵。
- 通過對UGC資料的挖掘可以提取出一些關鍵詞,然後使用這些關鍵詞給deal打標籤,用於deal的個性化展示。
策略觸發
上文中我們提到了資料的重要性,但是資料的落腳點還是演算法和模型。單純的資料只是一些位元組的堆積,我們必須通過對資料的清洗去除資料中的噪聲,然後通過演算法和模型學習其中的規律,才能將資料的價值最大化。在本節中,將介紹推薦候選集觸發過程中用到的相關演算法。
##1. 協同過濾
提到推薦,就不得不說協同過濾,它幾乎在每一個推薦系統中都會用到。基本的演算法非常簡單,但是要獲得更好的效果,往往需要根據具體的業務做一些差異化的處理。
-
清除作弊、刷單、代購等噪聲資料。這些資料的存在會嚴重影響演算法的效果,因此要在第一步的資料清洗中就將這些資料剔除。
-
合理選取訓練資料。選取的訓練資料的時間視窗不宜過長,當然也不能過短。具體的視窗期數值需要經過多次的實驗來確定。同時可以考慮引入時間衰減,因為近期的使用者行為更能反映使用者接下來的行為動作。
-
user-based與item-based相結合。
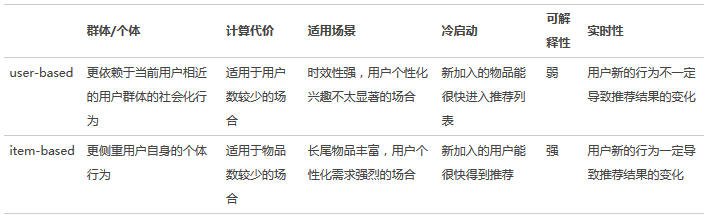
- 嘗試不同的相似度計算方法。在實踐中,我們採用了一種稱作loglikelihood ratio[1]的相似度計算方法。在mahout中,loglikelihood ratio也作為一種相似度計算方法被採用。 下表表示了Event A和Event B之間的相互關係,其中: k11 :Event A和Event B共現的次數 k12 :Event B發生,Event A未發生的次數 k21 :Event A發生,Event B未發生的次數 k22 :Event A和Event B都不發生的次數

則logLikelihoodRatio=2 * (matrixEntropy - rowEntropy - columnEntropy)
其中 rowEntropy = entropy(k11, k12) + entropy(k21, k22) columnEntropy = entropy(k11, k21) + entropy(k12, k22) matrixEntropy = entropy(k11, k12, k21, k22) (entropy為幾個元素組成的系統的夏農熵)
##2. location-based
對於移動裝置而言,與PC端最大的區別之一是移動裝置的位置是經常發生變化的。不同的地理位置反映了不同的使用者場景,在具體的業務中可以充分利用使用者所處的地理位置。在推薦的候選集觸發中,我們也會根據使用者的實時地理位置、工作地、居住地等地理位置觸發相應的策略。
- 根據使用者的歷史消費、歷史瀏覽等,挖掘出某一粒度的區域(比如商圈)內的區域消費熱單和區域購買熱單
 區域消費熱單
區域消費熱單
 區域購買熱單
區域購買熱單
-
當新的線上使用者請求到達時,根據使用者的幾個地理位置對相應地理位置的區域消費熱單和區域購買熱單進行加權,最終得到一個推薦列表。
-
此外,還可以根據使用者出現的地理位置,採用協同過濾的方式計算使用者的相似度。
##3. query-based
搜尋是一種強使用者意圖,比較明確的反應了使用者的意願,但是在很多情況下,因為各種各樣的原因,沒有形成最終的轉換。儘管如此,我們認為,這種情景還是代表了一定的使用者意願,可以加以利用。具體做法如下:
-
對使用者過去一段時間的搜尋無轉換行為進行挖掘,計算每一個使用者對不同query的權重。

-
計算每個query下不同deal的權重。

-
當用戶再次請求時,根據使用者對不同query的權重及query下不同deal的權重進行加權,取出權重最大的TopN進行推薦。
##4. graph-based
對於協同過濾而言,user之間或者deal之間的圖距離是兩跳,對於更遠距離的關係則不能考慮在內。而圖演算法可以打破這一限制,將user與deal的關係視作一個二部圖,相互間的關係可以在圖上傳播。Simrank[2]是一種衡量對等實體相似度的圖演算法。它的基本思想是,如果兩個實體與另外的相似實體有相關關係,那它們也是相似的,即相似性是可以傳播的。
- Let s(A,B) denote the similarity between persons A and B, for A != B

Let s(c,d) denote the similarity between items c and d, for c != d
O(A),O(B): the set of out-neighbors for node A or node B I(c),I(d): the set of in-neighbors for node c or node d
-
simrank的計算(採用矩陣迭代的方式)

-
計算得出相似度矩陣後,可以類似協同過濾用於線上推薦。
##5. 實時使用者行為
目前我們的業務會產生包括搜尋、篩選、收藏、瀏覽、下單等豐富的使用者行為,這些是我們進行效果優化的重要基礎。我們當然希望每一個使用者行為流都能到達轉化的環節,但是事實上遠非這樣。
當用戶產生了下單行為上游的某些行為時,會有相當一部分因為各種原因使行為流沒有形成轉化。但是,使用者的這些上游行為對我們而言是非常重要的先驗知識。很多情況下,使用者當時沒有轉化並不代表使用者對當前的item不感興趣。當用戶再次到達我們的推薦展位時,我們根據使用者之前產生的先驗行為理解並識別使用者的真正意圖,將符合使用者意圖的相關deal再次展現給使用者,引導使用者沿著行為流向下游行進,最終達到下單這個終極目標。
目前引入的實時使用者行為包括:實時瀏覽、實時收藏。
##6. 替補策略
雖然我們有一系列基於使用者歷史行為的候選集觸發演算法,但對於部分新使用者或者歷史行為不太豐富的使用者,上述演算法觸發的候選集太小,因此需要使用一些替補策略進行填充。
- 熱銷單:在一定時間內銷量最多的item,可以考慮時間衰減的影響等。
- 好評單:使用者產生的評價中,評分較高的item。
- 城市單:滿足基本的限定條件,在使用者的請求城市內的。
子策略融合
為了結合不同觸發演算法的優點,同時提高候選集的多樣性和覆蓋率,需要將不同的觸發演算法融合在一起。常見的融合的方法有以下幾種[3]:
- 加權型:最簡單的融合方法就是根據經驗值對不同演算法賦給不同的權重,對各個演算法產生的候選集按照給定的權重進行加權,然後再按照權重排序。
- 分級型:優先採用效果好的演算法,當產生的候選集大小不足以滿足目標值時,再使用效果次好的演算法,依此類推。
- 調製型:不同的演算法按照不同的比例產生一定量的候選集,然後疊加產生最終總的候選集。
- 過濾型:當前的演算法對前一級演算法產生的候選集進行過濾,依此類推,候選集被逐級過濾,最終產生一個小而精的候選集合。
目前我們使用的方法集成了調製和分級兩種融合方法,不同的演算法根據歷史效果表現給定不同的候選集構成比例,同時優先採用效果好的演算法觸發,如果候選集不夠大,再採用效果次之的演算法觸發,依此類推。
候選集重排序
如上所述,對於不同演算法觸發出來的候選集,只是根據演算法的歷史效果決定演算法產生的item的位置顯得有些簡單粗暴,同時,在每個演算法的內部,不同item的順序也只是簡單的由一個或者幾個因素決定,這些排序的方法只能用於第一步的初選過程,最終的排序結果需要藉助機器學習的方法,使用相關的排序模型,綜合多方面的因素來確定。
##1. 模型
非線性模型能較好的捕捉特徵中的非線性關係,但訓練和預測的代價相對線性模型要高一些,這也導致了非線性模型的更新週期相對要長。反之,線性模型對特徵的處理要求比較高,需要憑藉領域知識和經驗人工對特徵做一些先期處理,但因為線性模型簡單,在訓練和預測時效率較高。因此在更新週期上也可以做的更短,還可以結合業務做一些線上學習的嘗試。在我們的實踐中,非線性模型和線性模型都有應用。
- 非線性模型
目前我們主要採用了非線性的樹模型Additive Groves[4](簡稱AG),相對於線性模型,非線性模型可以更好的處理特徵中的非線性關係,不必像線性模型那樣在特徵處理和特徵組合上花費比較大的精力。AG是一個加性模型,由很多個Grove組成,不同的Grove之間進行bagging得出最後的預測結果,由此可以減小過擬合的影響。
 每一個Grove有多棵樹組成,在訓練時每棵樹的擬合目標為真實值與其他樹預測結果之和之間的殘差。當達到給定數目的樹時,重新訓練的樹會逐棵替代以前的樹。經過多次迭代後,達到收斂。
每一個Grove有多棵樹組成,在訓練時每棵樹的擬合目標為真實值與其他樹預測結果之和之間的殘差。當達到給定數目的樹時,重新訓練的樹會逐棵替代以前的樹。經過多次迭代後,達到收斂。


- 線性模型
目前應用比較多的線性模型非Logistic Regression莫屬了。為了能實時捕捉資料分佈的變化,我們引入了online learning,接入實時資料流,使用google提出的FTRL[5]方法對模型進行線上更新。

主要的步驟如下:
- 線上寫特徵向量到HBase
- Storm解析實時點選和下單日誌流,改寫HBase中對應特徵向量的label
- 通過FTRL更新模型權重
- 將新的模型引數應用於線上
##2. 資料
- 取樣:對於點選率預估而言,正負樣本嚴重不均衡,所以需要對負例做一些取樣。
- 負例:正例一般是使用者產生點選、下單等轉換行為的樣本,但是使用者沒有轉換行為的樣本是否就一定是負例呢?其實不然,很多展現其實使用者根本沒有看到,所以把這樣樣本視為負例是不合理的,也會影響模型的效果。比較常用的方法是skip-above,即使用者點選的item位置以上的展現才可能視作負例。當然,上面的負例都是隱式的負反饋資料,除此之外,我們還有使用者主動刪除的顯示負反饋資料,這些資料是高質量的負例。
- 去噪:對於資料中混雜的刷單等類作弊行為的資料,要將其排除出訓練資料,否則會直接影響模型的效果。
##3. 特徵
在我們目前的重排序模型中,大概分為以下幾類特徵:
- deal(即團購單,下同)維度的特徵:主要是deal本身的一些屬性,包括價格、折扣、銷量、評分、類別、點選率等
- user維度的特徵:包括使用者等級、使用者的人口屬性、使用者的客戶端型別等
- user、deal的交叉特徵:包括使用者對deal的點選、收藏、購買等
- 距離特徵:包括使用者的實時地理位置、常去地理位置、工作地、居住地等與poi的距離
對於非線性模型,上述特徵可以直接使用;而對於線性模型,則需要對特徵值做一些分桶、歸一化等處理,使特徵值成為0~1之間的連續值或01二值。
總結
以資料為基礎,用演算法去雕琢,只有將二者有機結合,才會帶來效果的提升。對我們而言,以下兩個節點是我們優化過程中的里程碑:
- 將候選集進行融合:提高了推薦的覆蓋度、多樣性和精度
- 引入重排序模型:解決了候選集增加以後deal之間排列順序的問題

以上是我們在實踐中的一點總結,當然我們還有還多事情要做。we are still on the way!
備註:
本文為美團推薦與個性化團隊集體智慧的結晶,感謝為此辛苦付出的每一個成員。同時,團隊長期招聘演算法工程師與平臺研發工程師,感興趣的同學請聯絡[email protected],郵件標題註明“應聘推薦系統工程師”。