
(轉)Git 內部原理
9 Git 內部原理
不管你是從前面的章節直接跳到了本章,還是讀完了其餘各章一直到這,你都將在本章見識 Git 的內部工作原理和實現方式。我個人發現學習這些內容對於理解 Git 的用處和強大是非常重要的,不過也有人認為這些內容對於初學者來說可能難以理解且過於複雜。正因如此我把這部分內容放在最後一章,你在學習過程中可以先閱讀這部分,也可以晚點閱讀這部分,這完全取決於你自己。
既然已經讀到這了,就讓我們開始吧。首先要弄明白一點,從根本上來講 Git 是一套內容定址 (content-addressable) 檔案系統,在此之上提供了一個 VCS 使用者介面。馬上你就會學到這意味著什麼。
早期的 Git (主要是 1.5 之前版本) 的使用者介面要比現在複雜得多,這是因為它更側重於成為檔案系統而不是一套更精緻的 VCS 。最近幾年改進了 UI 從而使它跟其他任何系統一樣清晰易用。即便如此,還是經常會有一些陳腔濫調提到早期 Git 的 UI 複雜又難學。
內容定址檔案系統層相當酷,在本章中我會先講解這部分。隨後你會學到傳輸機制和最終要使用的各種庫管理任務。
本書講解了使用 checkout, branch, remote 等共約 30 個 Git 命令。然而由於 Git 一開始被設計成供 VCS 使用的工具集而不是一整套使用者友好的 VCS,它還包含了許多底層命令,這些命令用於以 UNIX 風格使用或由指令碼呼叫。這些命令一般被稱為 "plumbing" 命令(底層命令),其他的更友好的命令則被稱為 "porcelain" 命令(高層命令)。
本書前八章主要專門討論高層命令。本章將主要討論底層命令以理解 Git 的內部工作機制、演示 Git 如何及為何要以這種方式工作。這些命令主要不是用來從命令列手工使用的,更多的是用來為其他工具和自定義指令碼服務的。
當你在一個新目錄或已有目錄內執行 git init 時,Git 會建立一個 .git 目錄,幾乎所有 Git 儲存和操作的內容都位於該目錄下。如果你要備份或複製一個庫,基本上將這一目錄拷貝至其他地方就可以了。本章基本上都討論該目錄下的內容。該目錄結構如下:
$ ls
HEAD
branches/
config
description
hooks/
index
info/
objects/
refs/該目錄下有可能還有其他檔案,但這是一個全新的 git init 生成的庫,所以預設情況下這些就是你能看到的結構。新版本的 Git 不再使用 branches
description 檔案僅供 GitWeb 程式使用,所以不用關心這些內容。config 檔案包含了專案特有的配置選項,info 目錄儲存了一份不希望在 .gitignore 檔案中管理的忽略模式 (ignored patterns) 的全域性可執行檔案。hooks 目錄儲存了第七章詳細介紹了的客戶端或服務端鉤子指令碼。
另外還有四個重要的檔案或目錄:HEAD 及 index 檔案,objects 及 refs 目錄。這些是 Git 的核心部分。objects 目錄儲存所有資料內容,refs 目錄儲存指向資料 (分支) 的提交物件的指標,HEAD 檔案指向當前分支,index 檔案儲存了暫存區域資訊。馬上你將詳細瞭解 Git 是如何操縱這些內容的。
Git 是一套內容定址檔案系統。很不錯。不過這是什麼意思呢? 這種說法的意思是,Git 從核心上來看不過是簡單地儲存鍵值對(key-value)。它允許插入任意型別的內容,並會返回一個鍵值,通過該鍵值可以在任何時候再取出該內容。可以通過底層命令 hash-object 來示範這點,傳一些資料給該命令,它會將資料儲存在 .git 目錄並返回表示這些資料的鍵值。首先初使化一個 Git 倉庫並確認 objects 目錄是空的:
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$Git 初始化了 objects 目錄,同時在該目錄下建立了 pack 和 info 子目錄,但是該目錄下沒有其他常規檔案。我們往這個 Git 資料庫裡儲存一些文字:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4引數 -w 指示 hash-object 命令儲存 (資料) 物件,若不指定這個引數該命令僅僅返回鍵值。--stdin 指定從標準輸入裝置 (stdin) 來讀取內容,若不指定這個引數則需指定一個要儲存的檔案的路徑。該命令輸出長度為 40 個字元的校驗和。這是個 SHA-1 雜湊值──其值為要儲存的資料加上你馬上會了解到的一種頭資訊的校驗和。現在可以檢視到 Git 已經儲存了資料:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4可以在 objects 目錄下看到一個檔案。這便是 Git 儲存資料內容的方式──為每份內容生成一個檔案,取得該內容與頭資訊的 SHA-1 校驗和,建立以該校驗和前兩個字元為名稱的子目錄,並以 (校驗和) 剩下 38 個字元為檔案命名 (儲存至子目錄下)。
通過 cat-file 命令可以將資料內容取回。該命令是檢視 Git 物件的瑞士軍刀。傳入 -p 引數可以讓該命令輸出資料內容的型別:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content可以往 Git 中新增更多內容並取回了。也可以直接新增檔案。比方說可以對一個檔案進行簡單的版本控制。首先,建立一個新檔案,並把檔案內容儲存到資料庫中:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30接著往該檔案中寫入一些新內容並再次儲存:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a資料庫中已經將檔案的兩個新版本連同一開始的內容儲存下來了:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4再將檔案恢復到第一個版本:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1或恢復到第二個版本:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2需要記住的是幾個版本的檔案 SHA-1 值可能與實際的值不同,其次,儲存的並不是檔名而僅僅是檔案內容。這種物件型別稱為 blob 。通過傳遞 SHA-1 值給 cat-file -t 命令可以讓 Git 返回任何物件的型別:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobtree (樹) 物件
接下去來看 tree 物件,tree 物件可以儲存檔名,同時也允許儲存一組檔案。Git 以一種類似 UNIX 檔案系統但更簡單的方式來儲存內容。所有內容以 tree 或 blob 物件儲存,其中 tree 物件對應於 UNIX 中的目錄,blob 物件則大致對應於 inodes 或檔案內容。一個單獨的 tree 物件包含一條或多條 tree 記錄,每一條記錄含有一個指向 blob 或子 tree 物件的 SHA-1 指標,並附有該物件的許可權模式 (mode)、型別和檔名資訊。以 simplegit 專案為例,最新的 tree 可能是這個樣子:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libmaster^{tree} 表示 branch 分支上最新提交指向的 tree 物件。請注意 lib 子目錄並非一個 blob 物件,而是一個指向別一個 tree 物件的指標:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb從概念上來講,Git 儲存的資料如圖 9-1 所示。

圖 9-1. Git 物件模型的簡化版
你可以自己建立 tree 。通常 Git 根據你的暫存區域或 index 來建立並寫入一個 tree 。因此要建立一個 tree 物件的話首先要通過將一些檔案暫存從而建立一個 index 。可以使用 plumbing 命令 update-index 為一個單獨檔案 ── test.txt 檔案的第一個版本 ── 建立一個 index 。通過該命令人為的將 test.txt 檔案的首個版本加入到了一個新的暫存區域中。由於該檔案原先並不在暫存區域中 (甚至就連暫存區域也還沒被創建出來呢) ,必須傳入 --add引數;由於要新增的檔案並不在當前目錄下而是在資料庫中,必須傳入 --cacheinfo 引數。同時指定了檔案模式,SHA-1 值和檔名:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt在本例中,指定了檔案模式為 100644,表明這是一個普通檔案。其他可用的模式有:100755 表示可執行檔案,120000 表示符號連結。檔案模式是從常規的 UNIX 檔案模式中參考來的,但是沒有那麼靈活 ── 上述三種模式僅對 Git 中的檔案 (blobs) 有效 (雖然也有其他模式用於目錄和子模組)。
現在可以用 write-tree 命令將暫存區域的內容寫到一個 tree 物件了。無需 -w 引數 ── 如果目標 tree 不存在,呼叫 write-tree 會自動根據 index 狀態建立一個 tree 物件。
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt可以這樣驗證這確實是一個 tree 物件:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree再根據 test.txt 的第二個版本以及一個新檔案建立一個新 tree 物件:
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt這時暫存區域中包含了 test.txt 的新版本及一個新檔案 new.txt 。建立 (寫) 該 tree 物件 (將暫存區域或 index 狀態寫入到一個 tree 物件),然後瞧瞧它的樣子:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt請注意該 tree 物件包含了兩個檔案記錄,且 test.txt 的 SHA 值是早先值的 "第二版" (1f7a7a)。來點更有趣的,你將把第一個 tree 物件作為一個子目錄加進該 tree 中。可以用 read-tree 命令將 tree 物件讀到暫存區域中去。在這時,通過傳一個 --prefix 引數給 read-tree,將一個已有的 tree 物件作為一個子 tree 讀到暫存區域中:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt如果從剛寫入的新 tree 物件建立一個工作目錄,將得到位於工作目錄頂級的兩個檔案和一個名為 bak 的子目錄,該子目錄包含了 test.txt 檔案的第一個版本。可以將 Git 用來包含這些內容的資料想象成如圖 9-2 所示的樣子。

圖 9-2. 當前 Git 資料的內容結構
commit (提交) 物件
你現在有三個 tree 物件,它們指向了你要跟蹤的專案的不同快照,可是先前的問題依然存在:必須記往三個 SHA-1 值以獲得這些快照。你也沒有關於誰、何時以及為何儲存了這些快照的資訊。commit 物件為你儲存了這些基本資訊。
要建立一個 commit 物件,使用 commit-tree 命令,指定一個 tree 的 SHA-1,如果有任何前繼提交物件,也可以指定。從你寫的第一個 tree 開始:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d通過 cat-file 檢視這個新 commit 物件:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <[email protected]> 1243040974 -0700
committer Scott Chacon <[email protected]> 1243040974 -0700
first commitcommit 物件有格式很簡單:指明瞭該時間點專案快照的頂層樹物件、作者/提交者資訊(從 Git 設定的 user.name 和 user.email中獲得)以及當前時間戳、一個空行,以及提交註釋資訊。
接著再寫入另外兩個 commit 物件,每一個都指定其之前的那個 commit 物件:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9每一個 commit 物件都指向了你建立的樹物件快照。出乎意料的是,現在已經有了真實的 Git 歷史了,所以如果執行 git log 命令並指定最後那個 commit 物件的 SHA-1 便可以檢視歷史:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)真棒。你剛剛通過使用低階操作而不是那些普通命令建立了一個 Git 歷史。這基本上就是執行 git add 和 git commit 命令時 Git 進行的工作 ──儲存修改了的檔案的 blob,更新索引,建立 tree 物件,最後建立 commit 物件,這些 commit 物件指向了頂層 tree 物件以及先前的 commit 物件。這三類 Git 物件 ── blob,tree 以及 tree ── 都各自以檔案的方式儲存在 .git/objects 目錄下。以下所列是目前為止樣例中的所有物件,每個物件後面的註釋裡標明瞭它們儲存的內容:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1如果你按照以上描述進行了操作,可以得到如圖 9-3 所示的物件圖。

圖 9-3. Git 目錄下的所有物件
物件儲存
之前我提到當儲存資料內容時,同時會有一個檔案頭被儲存起來。我們花些時間來看看 Git 是如何儲存物件的。你將看來如何通過 Ruby 指令碼語言儲存一個 blob 物件 (這裡以字串 "what is up, doc?" 為例) 。使用 irb 命令進入 Ruby 互動式模式:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git 以物件型別為起始內容構造一個檔案頭,本例中是一個 blob。然後新增一個空格,接著是資料內容的長度,最後是一個空位元組 (null byte):
>> header = "blob #{content.length}\0"
=> "blob 16\000"Git 將檔案頭與原始資料內容拼接起來,並計算拼接後的新內容的 SHA-1 校驗和。可以在 Ruby 中使用 require 語句匯入 SHA1 digest 庫,然後呼叫 Digest::SHA1.hexdigest() 方法計算字串的 SHA-1 值:
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Git 用 zlib 對資料內容進行壓縮,在 Ruby 中可以用 zlib 庫來實現。首先需要匯入該庫,然後用 Zlib::Deflate.deflate() 對資料進行壓縮:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"最後將用 zlib 壓縮後的內容寫入磁碟。需要指定儲存物件的路徑 (SHA-1 值的頭兩個字元作為子目錄名稱,剩餘 38 個字元作為檔名儲存至該子目錄中)。在 Ruby 中,如果子目錄不存在可以用 FileUtils.mkdir_p() 函式建立它。接著用 File.open 方法開啟檔案,並用 write() 方法將之前壓縮的內容寫入該檔案:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32這就行了 ── 你已經建立了一個正確的 blob 物件。所有的 Git 物件都以這種方式儲存,惟一的區別是型別不同 ── 除了字串 blob,檔案頭起始內容還可以是 commit 或 tree 。不過雖然 blob 幾乎可以是任意內容,commit 和 tree 的資料卻是有固定格式的。
你可以執行像 git log 1a410e 這樣的命令來檢視完整的歷史,但是這樣你就要記得 1a410e 是你最後一次提交,這樣才能在提交歷史中找到這些物件。你需要一個檔案來用一個簡單的名字來記錄這些 SHA-1 值,這樣你就可以用這些指標而不是原來的 SHA-1 值去檢索了。
在 Git 中,我們稱之為“引用”(references 或者 refs,譯者注)。你可以在 .git/refs 目錄下面找到這些包含 SHA-1 值的檔案。在這個專案裡,這個目錄還沒不包含任何檔案,但是包含這樣一個簡單的結構:
$ find .git/refs
.git/refs
.git/refs/heads
.git/refs/tags
$ find .git/refs -type f
$如果想要建立一個新的引用幫助你記住最後一次提交,技術上你可以這樣做:
$ echo "1a410efbd13591db07496601ebc7a059dd55cfe9" > .git/refs/heads/master現在,你就可以在 Git 命令中使用你剛才建立的引用而不是 SHA-1 值:
$ git log --pretty=oneline master
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit當然,我們並不鼓勵你直接修改這些引用檔案。如果你確實需要更新一個引用,Git 提供了一個安全的命令 update-ref:
$ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9基本上 Git 中的一個分支其實就是一個指向某個工作版本一條 HEAD 記錄的指標或引用。你可以用這條命令建立一個指向第二次提交的分支:
$ git update-ref refs/heads/test cac0ca這樣你的分支將會只包含那次提交以及之前的工作:
$ git log --pretty=oneline test
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit現在,你的 Git 資料庫應該看起來像圖 9-4 一樣。
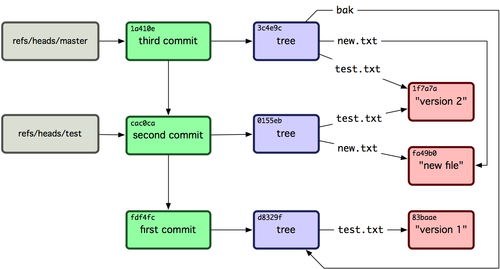
圖 9-4. 包含分支引用的 Git 目錄物件
每當你執行 git branch (分支名稱) 這樣的命令,Git 基本上就是執行 update-ref 命令,把你現在所在分支中最後一次提交的 SHA-1 值,新增到你要建立的分支的引用。
HEAD 標記
現在的問題是,當你執行 git branch (分支名稱) 這條命令的時候,Git 怎麼知道最後一次提交的 SHA-1 值呢?答案就是 HEAD 檔案。HEAD 檔案是一個指向你當前所在分支的引用識別符號。這樣的引用識別符號——它看起來並不像一個普通的引用——其實並不包含 SHA-1 值,而是一個指向另外一個引用的指標。如果你看一下這個檔案,通常你將會看到這樣的內容:
$ cat .git/HEAD
ref: refs/heads/master如果你執行 git checkout test,Git 就會更新這個檔案,看起來像這樣:
$ cat .git/HEAD
ref: refs/heads/test當你再執行 git commit 命令,它就建立了一個 commit 物件,把這個 commit 物件的父級設定為 HEAD 指向的引用的 SHA-1 值。
你也可以手動編輯這個檔案,但是同樣有一個更安全的方法可以這樣做:symbolic-ref。你可以用下面這條命令讀取 HEAD 的值:
$ git symbolic-ref HEAD
refs/heads/master你也可以設定 HEAD 的值:
$ git symbolic-ref HEAD refs/heads/test
$ cat .git/HEAD
ref: refs/heads/test但是你不能設定成 refs 以外的形式:
$ git symbolic-ref HEAD test
fatal: Refusing to point HEAD outside of refs/Tags
你剛剛已經重溫過了 Git 的三個主要物件型別,現在這是第四種。Tag 物件非常像一個 commit 物件——包含一個標籤,一組資料,一個訊息和一個指標。最主要的區別就是 Tag 物件指向一個 commit 而不是一個 tree。它就像是一個分支引用,但是不會變化——永遠指向同一個 commit,僅僅是提供一個更加友好的名字。
正如我們在第二章所討論的,Tag 有兩種型別:annotated 和 lightweight 。你可以類似下面這樣的命令建立一個 lightweight tag:
$ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d這就是 lightweight tag 的全部 —— 一個永遠不會發生變化的分支。 annotated tag 要更復雜一點。如果你建立一個 annotated tag,Git 會建立一個 tag 物件,然後寫入一個指向指向它而不是直接指向 commit 的 reference。你可以這樣建立一個 annotated tag(-a 引數表明這是一個 annotated tag):
$ git tag -a v1.1 1a410efbd13591db07496601ebc7a059dd55cfe9 -m 'test tag'這是所建立物件的 SHA-1 值:
$ cat .git/refs/tags/v1.1
9585191f37f7b0fb9444f35a9bf50de191beadc2現在你可以執行 cat-file 命令檢查這個 SHA-1 值:
$ git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2
object 1a410efbd13591db07496601ebc7a059dd55cfe9
type commit
tag v1.1
tagger Scott Chacon <[email protected]> Sat May 23 16:48:58 2009 -0700
test tag值得注意的是這個物件指向你所標記的 commit 物件的 SHA-1 值。同時需要注意的是它並不是必須要指向一個 commit 物件;你可以標記任何 Git 物件。例如,在 Git 的原始碼裡,管理者添加了一個 GPG 公鑰(這是一個 blob 物件)對它做了一個標籤。你就可以執行:
$ git cat-file blob junio-gpg-pub來檢視 Git 原始碼倉庫中的公鑰. Linux kernel 也有一個不是指向 commit 物件的 tag —— 第一個 tag 是在匯入原始碼的時候建立的,它指向初始 tree (initial tree,譯者注)。
Remotes
你將會看到的第四種 reference 是 remote reference(遠端引用,譯者注)。如果你添加了一個 remote 然後推送程式碼過去,Git 會把你最後一次推送到這個 remote 的每個分支的值都記錄在 refs/remotes 目錄下。例如,你可以新增一個叫做 origin 的 remote 然後把你的 master 分支推送上去:
$ git remote add origin [email protected]:schacon/simplegit-progit.git
$ git push origin master
Counting objects: 11, done.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (7/7), 716 bytes, done.
Total 7 (delta 2), reused 4 (delta 1)
To [email protected]:schacon/simplegit-progit.git
a11bef0..ca82a6d master -> master然後檢視 refs/remotes/origin/master 這個檔案,你就會發現 origin remote 中的 master 分支就是你最後一次和伺服器的通訊。
$ cat .git/refs/remotes/origin/master
ca82a6dff817ec66f44342007202690a93763949Remote 應用和分支主要區別在於他們是不能被 check out 的。Git 把他們當作是標記這些了這些分支在伺服器上最後狀態的一種書籤。
我們再來看一下 test Git 倉庫。目前為止,有 11 個物件 ── 4 個 blob,3 個 tree,3 個 commit 以及一個 tag:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/95/85191f37f7b0fb9444f35a9bf50de191beadc2 # tag
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Git 用 zlib 壓縮檔案內容,因此這些檔案並沒有佔用太多空間,所有檔案加起來總共僅用了 925 位元組。接下去你會新增一些大檔案以演示 Git 的一個很有意思的功能。將你之前用到過的 Grit 庫中的 repo.rb 檔案加進去 ── 這個原始碼檔案大小約為 12K:
$ curl http://github.com/mojombo/grit/raw/master/lib/grit/repo.rb > repo.rb
$ git add repo.rb
$ git commit -m 'added repo.rb'
[master 484a592] added repo.rb
3 files changed, 459 insertions(+), 2 deletions(-)
delete mode 100644 bak/test.txt
create mode 100644 repo.rb
rewrite test.txt (100%)如果檢視一下生成的 tree,可以看到 repo.rb 檔案的 blob 物件的 SHA-1 值:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt然後可以用 git cat-file 命令檢視這個物件有多大:
$ git cat-file -s 9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e
12898稍微修改一下些檔案,看會發生些什麼:
$ echo '# testing' >> repo.rb
$ git commit -am 'modified repo a bit'
[master ab1afef] modified repo a bit
1 files changed, 1 insertions(+), 0 deletions(-)檢視這個 commit 生成的 tree,可以看到一些有趣的東西:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 05408d195263d853f09dca71d55116663690c27c repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txtblob 物件與之前的已經不同了。這說明雖然只是往一個 400 行的檔案最後加入了一行內容,Git 卻用一個全新的物件來儲存新的檔案內容:
$ git cat-file -s 05408d195263d853f09dca71d55116663690c27c
12908你的磁碟上有了兩個幾乎完全相同的 12K 的物件。如果 Git 只完整儲存其中一個,並儲存另一個物件的差異內容,豈不更好?
事實上 Git 可以那樣做。Git 往磁碟儲存物件時預設使用的格式叫鬆散物件 (loose object) 格式。Git 時不時地將這些物件打包至一個叫 packfile 的二進位制檔案以節省空間並提高效率。當倉庫中有太多的鬆散物件,或是手工呼叫 git gc 命令,或推送至遠端伺服器時,Git 都會這樣做。手工呼叫 git gc命令讓 Git 將庫中物件打包並看會發生些什麼:
$ git gc
Counting objects: 17, done.
Delta compression using 2 threads.
Compressing objects: 100% (13/13), done.
Writing objects: 100% (17/17), done.
Total 17 (delta 1), reused 10 (delta 0)檢視一下 objects 目錄,會發現大部分物件都不在了,與此同時出現了兩個新檔案:
$ find .git/objects -type f
.git/objects/71/08f7ecb345ee9d0084193f147cdad4d2998293
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/info/packs
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack仍保留著的幾個物件是未被任何 commit 引用的 blob ── 在此例中是你之前建立的 "what is up, doc?" 和 "test content" 這兩個示例 blob。你從沒將他們新增至任何 commit,所以 Git 認為它們是 "懸空" 的,不會將它們打包進 packfile 。
剩下的檔案是新建立的 packfile 以及一個索引。packfile 檔案包含了剛才從檔案系統中移除的所有物件。索引檔案包含了 packfile 的偏移資訊,這樣就可以快速定位任意一個指定物件。有意思的是執行 gc 命令前磁碟上的物件大小約為 12K ,而這個新生成的 packfile 僅為 6K 大小。通過打包物件減少了一半磁碟使用空間。
Git 是如何做到這點的?Git 打包物件時,會查詢命名及尺寸相近的檔案,並只儲存檔案不同版本之間的差異內容。可以檢視一下 packfile ,觀察它是如何節省空間的。git verify-pack 命令用於顯示已打包的內容:
$ git verify-pack -v \
.git/objects/pack/pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.idx
0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 5400
05408d195263d853f09dca71d55116663690c27c blob 12908 3478 874
09f01cea547666f58d6a8d809583841a7c6f0130 tree 106 107 5086
1a410efbd13591db07496601ebc7a059dd55cfe9 commit 225 151 322
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 5381
3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 101 105 5211
484a59275031909e19aadb7c92262719cfcdf19a commit 226 153 169
83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 5362
9585191f37f7b0fb9444f35a9bf50de191beadc2 tag 136 127 5476
9bc1dc421dcd51b4ac296e3e5b6e2a99cf44391e blob 7 18 5193 1 \
05408d195263d853f09dca71d55116663690c27c
ab1afef80fac8e34258ff41fc1b867c702daa24b commit 232 157 12
cac0cab538b970a37ea1e769cbbde608743bc96d commit 226 154 473
d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 5316
e3f094f522629ae358806b17daf78246c27c007b blob 1486 734 4352
f8f51d7d8a1760462eca26eebafde32087499533 tree 106 107 749
fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 856
fdf4fc3344e67ab068f836878b6c4951e3b15f3d commit 177 122 627
chain length = 1: 1 object
pack-7a16e4488ae40c7d2bc56ea2bd43e25212a66c45.pack: ok如果你還記得的話, 9bc1d 這個 blob 是 repo.rb 檔案的第一個版本,這個 blob 引用了 05408 這個 blob,即該檔案的第二個版本。命令輸出內容的第三列顯示的是物件大小,可以看到 05408 佔用了 12K 空間,而 9bc1d 僅為 7 位元組。非常有趣的是第二個版本才是完整儲存檔案內容的物件,而第一個版本是以差異方式儲存的 ── 這是因為大部分情況下需要快速訪問檔案的最新版本。
最妙的是可以隨時進行重新打包。Git 自動定期對倉庫進行重新打包以節省空間。當然也可以手工執行 git gc 命令來這麼做。
這本書讀到這裡,你已經使用過一些簡單的遠端分支到本地引用的對映方式了,這種對映可以更為複雜。 假設你像這樣添加了一項遠端倉庫:
$ git remote add origin [email protected]:schacon/simplegit-progit.git它在你的 .git/config 檔案中添加了一節,指定了遠端的名稱 (origin), 遠端倉庫的URL地址,和用於獲取操作的 Refspec:
[remote "origin"]
url = [email protected]:schacon/simplegit-progit.git
fetch = +refs/heads/*:refs/remotes/origin/*Refspec 的格式是一個可選的 + 號,接著是 <src>:<dst> 的格式,這裡 <src> 是遠端上的引用格式, <dst> 是將要記錄在本地的引用格式。可選的 + 號告訴 Git 在即使不能快速演進的情況下,也去強制更新它。
預設情況下 refspec 會被 git remote add 命令所自動生成, Git 會獲取遠端上 refs/heads/ 下面的所有引用,並將它寫入到本地的 refs/remotes/origin/. 所以,如果遠端上有一個 master 分支,你在本地可以通過下面這種方式來訪問它的歷史記錄:
$ git log origin/master
$ git log remotes/origin/master
$ git log refs/remotes/origin/master它們全是等價的,因為 Git 把它們都擴充套件成 refs/remotes/origin/master.
如果你想讓 Git 每次只拉取遠端的 master 分支,而不是遠端的所有分支,你可以把 fetch 這一行修改成這樣:
fetch = +refs/heads/master:refs/remotes/origin/master這是 git fetch 操作對這個遠端的預設 refspec 值。而如果你只想做一次該操作,也可以在命令列上指定這個 refspec. 如可以這樣拉取遠端的 master 分支到本地的 origin/mymaster 分支:
$ git fetch origin master:refs/remotes/origin/mymaster你也可以在命令列上指定多個 refspec. 像這樣可以一次獲取遠端的多個分支:
$ git fetch origin master:refs/remotes/origin/mymaster \
topic:refs/remotes/origin/topic
From [email protected]:schacon/simplegit
! [rejected] master -> origin/mymaster (non fast forward)
* [new branch] topic -> origin/topic在這個例子中, master 分支因為不是一個可以快速演進的引用而拉取操作被拒絕。你可以在 refspec 之前使用一個 + 號來過載這種行為。
你也可以在配置檔案中指定多個 refspec. 如你想在每次獲取時都獲取 master 和 experiment 分支,就新增兩行:
[remote "origin"]
url = [email protected]:schacon/simplegit-progit.git
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/experiment:refs/remotes/origin/experiment但是這裡不能使用部分萬用字元,像這樣就是不合法的:
fetch = +refs/heads/qa*:refs/remotes/origin/qa*但無論如何,你可以使用名稱空間來達到這個目的。如你有一個QA組,他們推送一系列分支,你想每次獲取 master 分支和QA組的所有分支,你可以使用這樣的配置段落:
[remote "origin"]
url = [email protected]:schacon/simplegit-progit.git
fetch = +refs/heads/master:refs/remotes/origin/master
fetch = +refs/heads/qa/*:refs/remotes/origin/qa/*如果你的工作流很複雜,有QA組推送的分支、開發人員推送的分支、和整合人員推送的分支,並且他們在遠端分支上協作,你可以採用這種方式為他們建立各自的名稱空間。
推送 Refspec
採用名稱空間的方式確實很棒,但QA組成員第1次是如何將他們的分支推送到 qa/ 空間裡面的呢?答案是你可以使用 refspec 來推送。
如果QA組成員想把他們的 master 分支推送到遠端的 qa/master 分支上,可以這樣執行:
$ git push origin master:refs/heads/qa/master如果他們想讓 Git 每次執行 git push origin 時都這樣自動推送,他們可以在配置檔案中新增 push 值:
[remote "origin"]
url = [email protected]:schacon/simplegit-progit.git
fetch = +refs/heads/*:refs/remotes/origin/*
push = refs/heads/master:refs/heads/qa/master這樣,就會讓 git push origin 預設就把本地的 master 分支推送到遠端的 qa/master 分支上。
刪除引用
你也可以使用 refspec 來刪除遠端的引用,是通過執行這樣的命令:
$ git push origin :topic因為 refspec 的格式是 <src>:<dst>, 通過把 <src> 部分留空的方式,這個意思是是把遠端的 topic 分支變成空,也就是刪除它。
Git 可以以兩種主要的方式跨越兩個倉庫傳輸資料:基於HTTP協議之上,和 file://, ssh://, 和 git:// 等智慧傳輸協議。這一節帶你快速瀏覽這兩種主要的協議操作過程。
啞協議
Git 基於HTTP之上傳輸通常被稱為啞協議,這是因為它在服務端不需要有針對 Git 特有的程式碼。這個獲取過程僅僅是一系列GET請求,客戶端可以假定服務端的Git倉庫中的佈局。讓我們以 simplegit 庫來看看 http-fetch 的過程:
$ git clone http://github.com/schacon/simplegit-progit.git它做的第1件事情就是獲取 info/refs 檔案。這個檔案是在服務端運行了 update-server-info 所生成的,這也解釋了為什麼在服務端要想使用HTTP傳輸,必須要開啟 post-receive 鉤子:
=> GET info/refs
ca82a6dff817ec66f44342007202690a93763949 refs/heads/master現在你有一個遠端引用和SHA值的列表。下一步是尋找HEAD引用,這樣你就知道了在完成後,什麼應該被檢出到工作目錄:
=> GET HEAD
ref: refs/heads/master這說明在完成獲取後,需要檢出 master 分支。 這時,已經可以開始漫遊操作了。因為你的起點是在 info/refs 檔案中所提到的 ca82a6 commit 物件,你的開始操作就是獲取它:
=> GET objects/ca/82a6dff817ec66f44342007202690a93763949
(179 bytes of binary data)然後你取回了這個物件 - 這在服務端是一個鬆散格式的物件,你使用的是靜態的 HTTP GET 請求獲取的。可以使用 zlib 解壓縮它,去除其頭部,檢視它的 commmit 內容:
$ git cat-file -p ca82a6dff817ec66f44342007202690a93763949
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
author Scott Chacon <[email protected]> 1205815931 -0700
committer Scott Chacon <[email protected]> 1240030591 -0700
changed the version number這樣,就得到了兩個需要進一步獲取的物件 - cfda3b 是這個 commit 物件所對應的 tree 物件,和 085bb3 是它的父物件;
=> GET objects/08/5bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
(179 bytes of data)這樣就取得了這它的下一步 commit 物件,再抓取 tree 物件:
=> GET objects/cf/da3bf379e4f8dba8717dee55aab78aef7f4daf
(404 - Not Found)Oops - 看起來這個 tree 物件在服務端並不以鬆散格式物件存在,所以得到了404響應,代表在HTTP服務端沒有找到該物件。這有好幾個原因 - 這個物件可能在替代倉庫裡面,或者在打包檔案裡面, Git 會首先檢查任何列出的替代倉庫:
=> GET objects/info/http-alternates
(empty file)如果這返回了幾個替代倉庫列表,那麼它會去那些地方檢查鬆散格式物件和檔案 - 這是一種在軟體分叉之間共享物件以節省磁碟的好方法。然而,在這個例子中,沒有替代倉庫。所以你所需要的物件肯定在某個打包檔案中。要檢查服務端有哪些打包格式檔案,你需要獲取 objects/info/packs 檔案,這裡麵包含有打包檔案列表(是的,它也是被 update-server-info 所生成的);
=> GET objects/info/packs
P pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack這裡服務端只有一個打包檔案,所以你要的物件顯然就在裡面。但是你可以先檢查它的索引檔案以確認。這在服務端有多個打包檔案時也很有用,因為這樣就可以先檢查你所需要的物件空間是在哪一個打包檔案裡面了:
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.idx
(4k of binary data)現在你有了這個打包檔案的索引,你可以看看你要的物件是否在裡面 - 因為索引檔案列出了這個打包檔案所包含的所有物件的SHA值,和該物件存在於打包檔案中的偏移量,所以你只需要簡單地獲取整個打包檔案:
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack
(13k of binary data)現在你也有了這個 tree 物件,你可以繼續在 commit 物件上漫遊。它們全部都在這個你已經下載到的打包檔案裡面,所以你不用繼續向服務端請求更多下載了。 在這完成之後,由於下載開始時已探明HEAD引用是指向 master 分支, Git 會將它檢出到工作目錄。
整個過程看起來就像這樣:
$ git clone http://github.com/schacon/simplegit-progit.git
Initialized empty Git repository in /private/tmp/simplegit-progit/.git/
got ca82a6dff817ec66f44342007202690a93763949
walk ca82a6dff817ec66f44342007202690a93763949
got 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Getting alternates list for http://github.com/schacon/simplegit-progit.git
Getting pack list for http://github.com/schacon/simplegit-progit.git
Getting index for pack 816a9b2334da9953e530f27bcac22082a9f5b835
Getting pack 816a9b2334da9953e530f27bcac22082a9f5b835
which contains cfda3bf379e4f8dba8717dee55aab78aef7f4daf
walk 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
walk a11bef06a3f659402fe7563abf99ad00de2209e6智慧協議
這個HTTP方法是很簡單但效率不是很高。使用智慧協議是傳送資料的更常用的方法。這些協議在遠端都有Git智慧型程序在服務 - 它可以讀出本地資料並計算出客戶端所需要的,並生成合適的資料給它,這有兩類傳輸資料的程序:一對用於上傳資料和一對用於下載。
上傳資料
為了上傳資料至遠端, Git 使用 send-pack 和 receive-pack 程序。這個 send-pack 程序執行在客戶端上,它連線至遠端執行的 receive-pack程序。
舉例來說,你在你的專案上運行了 git push origin master, 並且 origin 被定義為一個使用SSH協議的URL。 Git 會使用 send-pack 程序,它會啟動一個基於SSH的連線到伺服器。它嘗試像這樣透過SSH在服務端執行命令:
$ ssh -x [email protected] "git-receive-pack 'schacon/simplegit-progit.git'"
005bca82a6dff817ec66f4437202690a93763949 refs/heads/master report-status delete-refs
003e085bb3bcb608e1e84b2432f8ecbe6306e7e7 refs/heads/topic
0000這裡的 git-receive-pack 命令會立即對它所擁有的每一個引用響應一行 - 在這個例子中,只有 master 分支和它的SHA值。這裡第1行也包含了服務端的能力列表(這裡是 report-status 和 delete-refs)。
每一行以4位元組的十六進位制開始,用於指定整行的長度。你看到第1行以005b開始,這在十六進位制中表示91,意味著第1行有91位元組長。下一行以003e起始,表示有62位元組長,所以需要讀剩下的62位元組。再下一行是0000開始,表示伺服器已完成了引用列表過程。
現在它知道了服務端的狀態,你的 send-pack 程序會判斷哪些 commit 是它所擁有但服務端沒有的。針對每個引用,這次推送都會告訴對端的 receive-pack 這個資訊。舉例說,如果你在更新 master 分支,並且增加 experiment 分支,這個 send-pack 將會是像這樣:
0085ca82a6dff817ec66f44342007202690a93763949 15027957951b64cf874c3557a0f3547bd83b3ff6
refs/heads/master report-status
00670000000000000000000000000000000000000000 cdfdb42577e2506715f8cfeacdbabc092bf63e8d refs/heads/experiment
0000這裡的全'0'的SHA-1值表示之前沒有過這個物件 - 因為你是在新增新的 experiment 引用。如果你在刪除一個引用,你會看到相反的: 就是右邊是全'0'。
Git 針對每個引用傳送這樣一行資訊,就是舊的SHA值,新的SHA值,和將要更新的引用的名稱。第1行還會包含有客戶端的能力。下一步,客戶端會發送一個所有那些服務端所沒有的物件的一個打包檔案。最後,服務端以成功(或者失敗)來響應:
000Aunpack ok下載資料
當你在下載資料時, fetch-pack 和 upload-pack 程序就起作用了。客戶端啟動 fetch-pack 程序,連線至遠端的 upload-pack 程序,以協商後續資料傳輸過程。
在遠端倉庫有不同的方式啟動 upload-pack 程序。你可以使用與 receive-pack 相同的透過SSH管道的方式,也可以通過 Git 後臺來啟動這個程序,它預設監聽在9418號埠上。這裡 fetch-pack 程序在連線後像這樣向後臺傳送資料:
003fgit-upload-pack schacon/simplegit-progit.git\0host=myserver.com\0它也是以4位元組指定後續位元組長度的方式開始,然後是要執行的命令,和一個空位元組,然後是服務端的主機名,再跟隨一個最後的空位元組。 Git 後臺程序會檢查這個命令是否可以執行,以及那個倉庫是否存在,以及是否具有公開許可權。如果所有檢查都通過了,它會啟動這個 upload-pack 程序並將客戶端的請求移交給它。
如果你透過SSH使用獲取功能, fetch-pack 會像這樣執行:
$ ssh -x [email protected] "git-upload-pack 'schacon/simplegit-progit.git'"不管哪種方式,在 fetch-pack 連線之後, upload-pack 都會以這種形式返回:
0088ca82a6dff817ec66f44342007202690a93763949 HEAD\0multi_ack thin-pack \
side-band side-band-64k ofs-delta shallow no-progress include-tag
003fca82a6dff817ec66f44342007202690a93763949 refs/heads/master
003e085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 refs/heads/topic
0000這與 receive-pack 響應很類似,但是這裡指的能力是不同的。而且它還會指出HEAD引用,讓客戶端可以檢查是否是一份克隆。
在這裡, fetch-pack 程序檢查它自己所擁有的物件和所有它需要的物件,通過傳送 "want" 和所需物件的SHA值,傳送 "have" 和所有它已擁有的物件的SHA值。在列表完成時,再發送 "done" 通知 upload-pack 程序開始傳送所需物件的打包檔案。這個過程看起來像這樣:
0054want ca82a6dff817ec66f44342007202690a93763949 ofs-delta
0032have 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
0000
0009done這是傳輸協議的一個很基礎的例子,在更復雜的例子中,客戶端可能會支援 multi_ack 或者 side-band 能力;但是這個例子中展示了智慧協議的基本互動過程。
你時不時的需要進行一些清理工作 ── 如減小一個倉庫的大小,清理匯入的庫,或是恢復丟失的資料。本節將描述這類使用場景。
維護
Git 會不定時地自動執行稱為 "auto gc" 的命令。大部分情況下該命令什麼都不處理。不過要是存在太多鬆散物件 (loose object, 不在 packfile 中的物件) 或 packfile,Git 會進行呼叫 git gc 命令。 gc 指垃圾收集 (garbage collect),此命令會做很多工作:收集所有鬆散物件並將它們存入 packfile,合併這些 packfile 進一個大的 packfile,然後將不被任何 commit 引用並且已存在一段時間 (數月) 的物件刪除。
可以手工執行 auto gc 命令:
$ git gc --auto再次強調,這個命令一般什麼都不幹。如果有 7,000 個左右的鬆散物件或是 50 個以上的 packfile,Git 才會真正呼叫 gc 命令。可能通過修改配置中的 gc.auto 和 gc.autopacklimit 來調整這兩個閾值。
gc 還會將所有引用 (references) 併入一個單獨檔案。假設倉庫中包含以下分支和標籤:
$ find .git/refs -type f
.git/refs/heads/experiment
.git/refs/heads/master
.git/refs/tags/v1.0
.git/refs/tags/v1.1這時如果執行 git gc, refs 下的所有檔案都會消失。Git 會將這些檔案挪到 .git/packed-refs 檔案中去以提高效率,該檔案是這個樣子的:
$ cat .git/packed-refs
# pack-refs with: peeled
cac0cab538b970a37ea1e769cbbde608743bc96d refs/heads/experiment
ab1afef80fac8e34258ff41fc1b867c702daa24b refs/heads/master
cac0cab538b970a37ea1e769cbbde608743bc96d refs/tags/v1.0
9585191f37f7b0fb9444f35a9bf50de191beadc2 refs/tags/v1.1
^1a410efbd13591db07496601ebc7a059dd55cfe9當更新一個引用時,Git 不會修改這個檔案,而是在 refs/heads 下寫入一個新檔案。當查詢一個引用的 SHA 時,Git 首先在 refs 目錄下查詢,如果未找到則到 packed-refs 檔案中去查詢。因此如果在 refs 目錄下找不到一個引用,該引用可能存到 packed-refs 檔案中去了。
請留意檔案最後以 ^ 開頭的那一行。這表示該行上一行的那個標籤是一個 annotated 標籤,而該行正是那個標籤所指向的 commit 。
資料恢復
在使用 Git 的過程中,有時會不小心丟失 commit 資訊。這一般出現在以下情況下:強制刪除了一個分支而後又想重新使用這個分支,hard-reset 了一個分支從而丟棄了分支的部分 commit。如果這真的發生了,有什麼辦法把丟失的 commit 找回來呢?
下面的示例演示了對 test 倉庫主分支進行 hard-reset 到一個老版本的 commit 的操作,然後恢復丟失的 commit 。首先檢視一下當前的倉庫狀態:
$ git log --pretty=oneline
ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit接著將 master 分支移回至中間的一個 commit:
$ git reset --hard 1a410efbd13591db07496601ebc7a059dd55cfe9
HEAD is now at 1a410ef third commit
$ git log --pretty=oneline
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit這樣就丟棄了最新的兩個 commit ── 包含這兩個 commit 的分支不存在了。現在要做的是找出最新的那個 commit 的 SHA,然後新增一個指它它的分支。關鍵在於找出最新的 commit 的 SHA ── 你不大可能記住了這個 SHA,是吧?
通常最快捷的辦法是使用 git reflog 工具。當你 (在一個倉庫下) 工作時,Git 會在你每次修改了 HEAD 時悄悄地將改動記錄下來。當你提交或修改分支時,reflog 就會更新。git update-ref 命令也可以更新 reflog,這是在本章前面的 "Git References" 部分我們使用該命令而不是手工將 SHA 值寫入 ref 檔案的理由。任何時間執行 git reflog 命令可以檢視當前的狀態:
$ git reflog
1a410ef [email protected]{0}: 1a410efbd13591db07496601ebc7a059dd55cfe9: updating HEAD
ab1afef [email protected]{1}: ab1afef80fac8e34258ff41fc1b867c702daa24b: updating HEAD可以看到我們簽出的兩個 commit ,但沒有更多的相關資訊。執行 git log -g 會輸出 reflog 的正常日誌,從而顯示更多有用資訊:
$ git log -g
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Reflog: [email protected]{0} (Scott Chacon <[email protected]>)
Reflog message: updating HEAD
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:22:37 2009 -0700
third commit
commit ab1afef80fac8e34258ff41fc1b867c702daa24b
Reflog: [email protected]{1} (Scott Chacon <[email protected]>)
Reflog message: updating HEAD
Author: Scott Chacon <[email protected]>
Date: Fri May 22 18:15:24 2009 -0700
modified repo a bit看起來弄丟了的 commit 是底下那個,這樣在那個 commit 上建立一個新分支就能把它恢復過來。比方說,可以在那個 commit (ab1afef) 上建立一個名為 recover-branch 的分支:
$ git branch recover-branch ab1afef
$ git log --pretty=oneline recover-branch
ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit
484a59275031909e19aadb7c92262719cfcdf19a added repo.rb
1a410efbd13591db07496601ebc7a059dd55cfe9 third commit
cac0cab538b970a37ea1e769cbbde608743bc96d second commit
fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit酷!這樣有了一個跟原來 master 一樣的 recover-branch 分支,最新的兩個 commit 又找回來了。接著,假設引起 commit 丟失的原因並沒有記錄在 reflog 中 ── 可以通過刪除 recover-branch 和 reflog 來模擬這種情況。這樣最新的兩個 commit 不會被任何東西引用到:
$ git branch -D recover-branch
$ rm -Rf .git/logs/因為 reflog 資料是儲存在 .git/logs/ 目錄下的,這樣就沒有 reflog 了。現在要怎樣恢復 commit 呢?辦法之一是使用 git fsck 工具,該工具會檢查倉庫的資料完整性。如果指定 --ful 選項,該命令顯示所有未被其他物件引用 (指向) 的所有物件:
$ git fsck --full
dangling blob d670460b4b4aece5915caf5c68d12f560a9fe3e4
dangling commit ab1afef80fac8e34258ff41fc1b867c702daa24b
dangling tree aea790b9a58f6cf6f2804eeac9f0abbe9631e4c9
dangling blob 7108f7ecb345ee9d0084193f147cdad4d2998293本例中,可以從 dangling commit 找到丟失了的 commit。用相同的方法就可以恢復它,即建立一個指向該 SHA 的分支。
移除物件
Git 有許多過人之處,不過有一個功能有時卻會帶來問題:git clone 會將包含每一個檔案的所有歷史版本的整個專案下載下來。如果專案包含的僅僅是原始碼的話這並沒有什麼壞處,畢竟 Git 可以非常高效地壓縮此類資料。不過如果有人在某個時刻往專案中添加了一個非常大的檔案,那們即便他在後來的提交中將此檔案刪掉了,所有的簽出都會下載這個大檔案。因為歷史記錄中引用了這個檔案,它會一直存在著。
當你將 Subversion 或 Perforce 倉庫轉換匯入至 Git 時