
基於OpenStack和Kubernetes構建組合雲平臺——網路整合方案綜述
轉自: http://geek.csdn.net/news/detail/104150
一談到雲端計算,大家都會自然想到三種雲服務的模型:基礎設施即服務(IaaS),平臺即服務(PaaS)和軟體即服務(SaaS)。OpenStack已經成為私有云IaaS的標準,而PaaS層雖然有很多可選技術,但已經確定統一的是一定會基於容器技術,並且一定會架構在某種容器編排管理系統之上。在主流的容器編排管理系統Kubernetes、Mesos和Swarm中,Kubernetes以它活躍的社群,完整強大的功能和社群領導者富有遠見的設計而得到越來越多的企業青睞。我們基於OpenStack和Kubernetes研發了全球首個實現容器和虛擬機器組合服務、統一管理的容器雲平臺。在本文中我們將分享我們在整合OpenStack和Kubernetes過程中的網路整合方案的經驗總結。
Kubernetes的優秀設計
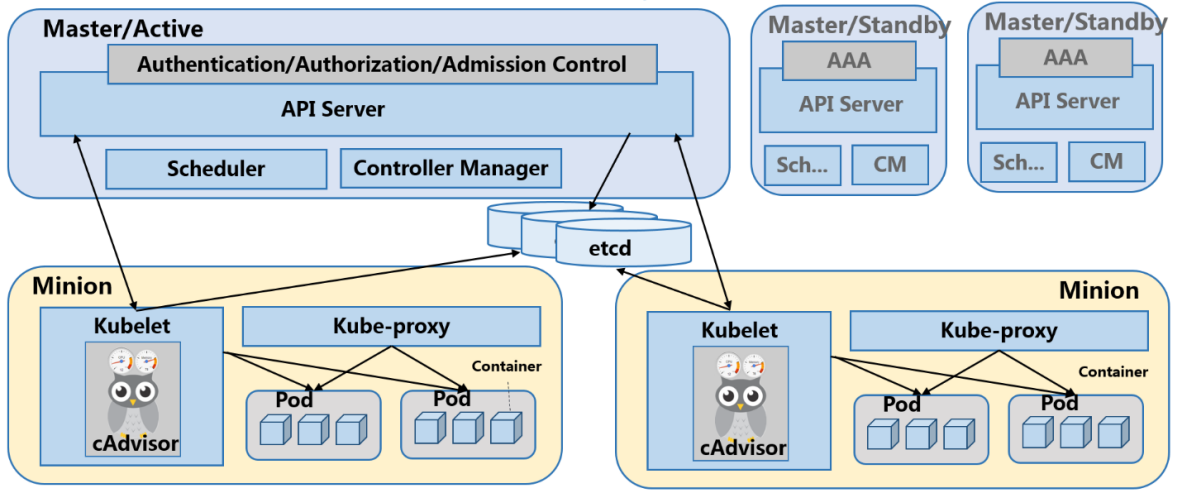
在我們介紹網路方案之前,先向大家簡單介紹一下Kubernetes的基礎構架。 一個Kubernetes叢集是由分散式儲存(etcd),服務節點(Minion)和控制節點(Master)構成的。所有的叢集狀態都儲存在etcd中,Master節點上則執行叢集的管理控制模組。Minion節點是真正執行應用容器的主機節點,在每個Minion節點上都會執行一個Kubelet代理,控制該節點上的容器、映象和儲存卷等。
支援多容器的微服務例項
Kubernetes有很多基本概念,最重要的也是最基礎的是Pod。Pod是一個執行部署的最小單元,他是可以支援多容器的。為什麼要有多容器?比如你執行一個作業系統發行版的軟體倉庫,一個Nginx容器用來發布軟體,另一個容器專門用來從源倉庫做同步,這兩個容器的映象不太可能是一個團隊開發的,但是他們一塊兒工作才能提供一個微服務;這種情況下,不同的團隊各自開發構建自己的容器映象,在部署的時候組合成一個微服務對外提供服務。
自動提供微服務的高可用
Kubernetes叢集自動提供微服務的高可用能力,由複製控制器(Replication Controller)即RC進行支援。RC通過監控執行中的Pod來保證叢集中執行指定數目的Pod副本。指定的數目可以是多個也可以是1個;少於指定數目,RC就會啟動執行新的Pod副本;多於指定數目,RC就會殺死多餘的Pod副本。即使在指定數目為1的情況下,通過RC執行Pod也比直接執行Pod更明智,因為RC也可以發揮它高可用的能力,保證永遠有1個Pod在執行。
微服務在叢集內部的負載均衡
在Kubernetes內部,一個Pod只是一個執行服務的例項,隨時可能在一個節點上停止,在另一個節點以一個新的IP啟動一個新的Pod,因此不能以確定的IP和埠號提供服務。在Kubernetes中真正對應一個微服務的概念是服務(Service),每個服務會對應一個叢集內部有效的虛擬IP,叢集內部通過虛擬IP訪問一個微服務。
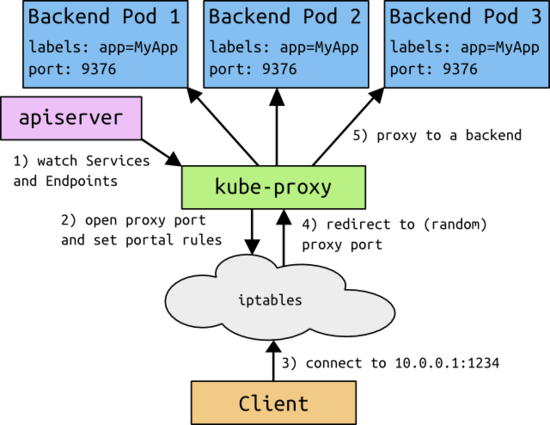
在Kubernetes叢集中,叢集管理員管理的是一系列抽象資源,例如對應一個微服務的抽象資源就是Service;對應一個微服務例項的抽象資源就是Pod。從Service到Pod的資料轉發是通過Kubernetes叢集中的負載均衡器,即kube-proxy實現的。Kube-proxy是一個分散式代理伺服器,在Kubernetes的每個Minion節點上都有一個;這一設計體現了它的伸縮性優勢,需要訪問服務的節點越多,提供負載均衡能力的kube-proxy就越多,高可用節點也隨之增多。與之相比,我們平時在伺服器端做個反向代理做負載均衡,還要進一步解決反向代理的負載均衡和高可用問題。Kube-proxy對應的是Service資源。每個節點的Kube-proxy都會監控Master節點針對Service的配置。當部署一個新的Service時,計入這個Service的IP是10.0.0.1,port是1234,那每個Kube-proxy都會在本地的IP Table上加上redirect規則,將所有傳送到10.0.0.1:1234的資料包都REDIRECT到本地的一個隨機埠,當然Kube-proxy也在這個埠監聽著,然後根據一些負載均衡規則,例如round robin把資料轉發到不同的後端Pod。
可替換選擇的組網方案
Kube-proxy只負責把服務請求的目標替換成目標Pod的埠,並不指定如何實現從當前節點將資料包傳送到指定Pod;後面如何再發送到Pod,那是Kubernetes自身的組網方案解決的。這裡也體現了Kubernetes優秀的設計理念,即組網方式和負載均衡分式可以獨立選擇,互不依賴。Kubernetes對組網方案的要求是能夠給每個Pod以內網可識別的獨立IP並且可達。如果用flannel組網的話,那就是每個節點上的flannel把發向容器的資料包進行封裝後,再用隧道將封裝後的資料包傳送到執行著目標Pod的Minion節點上。目標Minion節點再負責去掉封裝,將去除封裝的資料包傳送到目標Pod上。
雲平臺的多租戶隔離
對於一個完整的雲平臺,最基礎的需求是多租戶的隔離,我們需要考慮租戶Kubernetes叢集之間的隔離問題。就是我們希望把租戶自己的虛擬機器和容器叢集可以互聯互通,而不同租戶之間是隔離不能通訊的。使用OpenStack的多租戶私有網路可以實現網路的隔離。OpenStack以前叫租戶即Tenant,現在叫專案即Project;Tenant和Project是一個意思,即把獨立分配管理的一組資源放在一起管理,與其他組的資源互相隔離互不影響。為了提供支援多租戶的容器和虛擬機器組合服務,可以把容器叢集和虛擬機器放到一個獨立租戶的私有網路中去,這樣就達到了隔離作用。這種隔離有兩個效果,一是不同租戶之間的容器和虛擬機器不能通訊,二是不同租戶可以重用內網IP地址,例如10.0.0.1這個IP,兩個租戶都可用。放在同一個私有網路中的容器和虛擬機器,互相訪問通過內網通訊,相對於繞道公網,不僅節省公網頻寬,而且可以大大提高訪問效能。

對外發布應用服務
虛擬機器的內網IP,Kubernetes叢集節點的IP,服務的虛擬IP以及服務後端Pod的IP,這些IP在外網都是不可見的,叢集外的客戶端無法訪問。想讓外網的客戶端訪問虛擬機器,最簡單是用浮動IP;例如,一個VM有一個內網IP,我們可以給它分配一個外網浮動IP;外網連線這個浮動IP,就會轉發到相應的內網固定IP上。
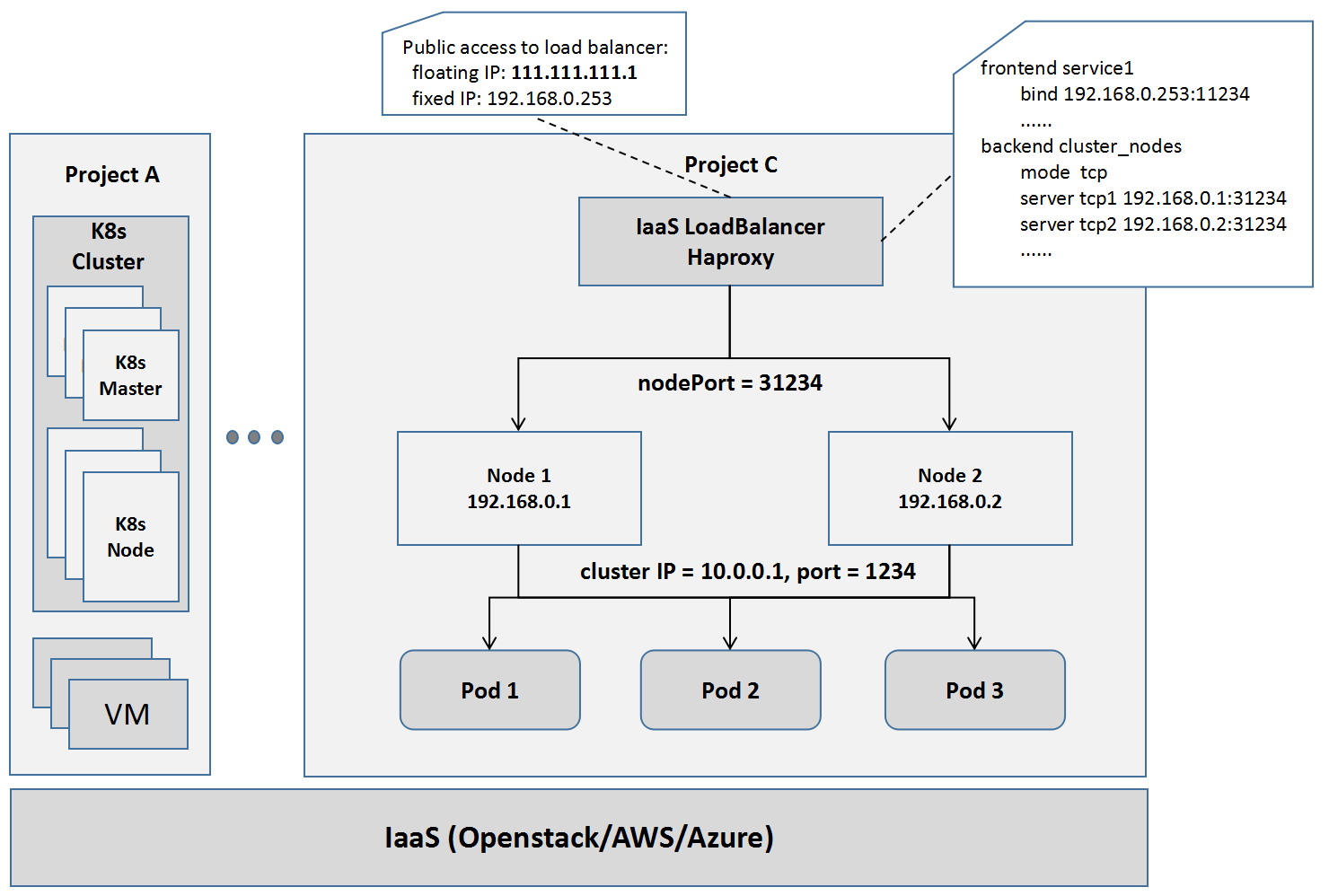
浮動IP的模式只適用於虛擬機器,不適用於Kubernetes中的服務。在OpenStack網路中,支援外網要利用nodePort和Load Balancer結合的方式。比如這裡有個服務,它的服務的虛擬IP(也叫Cluster IP)是10.0.0.1,埠是1234,那麼我們知道內網的客戶端就是通過這個IP和埠訪問的。為了讓外網訪問相應的服務,Kubernetes叢集中針對每個服務埠,會設定一個node Port 31234,群中的每個節點都會監聽這個埠,並會在通過IP Table的REDIRECT規則,將發向這個埠的資料包,REDIRECT對應服務的虛擬IP和埠。所有發向nodePort 31234這個埠的資料包,會被轉發到微服務的虛擬IP和埠上去,並進一步REDIRECT到Kube-proxy對應的埠上去。再進一步,只要從外網進來的資料包,就傳送到服務節點的nodePort埠上。那我們用Load Balancer來做,Load Balancer的前端是它的內網IP和釋出埠,後端是所有內網的節點IP和nodePort。因此所有發到負載均衡器的包,會做一次負載均衡,均衡地轉發到某個節點的nodePort上去,到達節點的nodePort的資料包又會轉發給相應的服務。為了讓外網訪問,我們要給Load Balancer綁一個外網IP,例如111.111.111.1,這樣所有來自外網,傳送到111.111.111.1:11234的資料包,都會轉發給對應的微服務10.0.0.1:1234,並最終轉發給某個隨機的Pod副本。
實現了以上工作,我們部署在Kubernetes叢集中的服務就可以實現在OpenStack的基礎平臺上對外發布和訪問了。
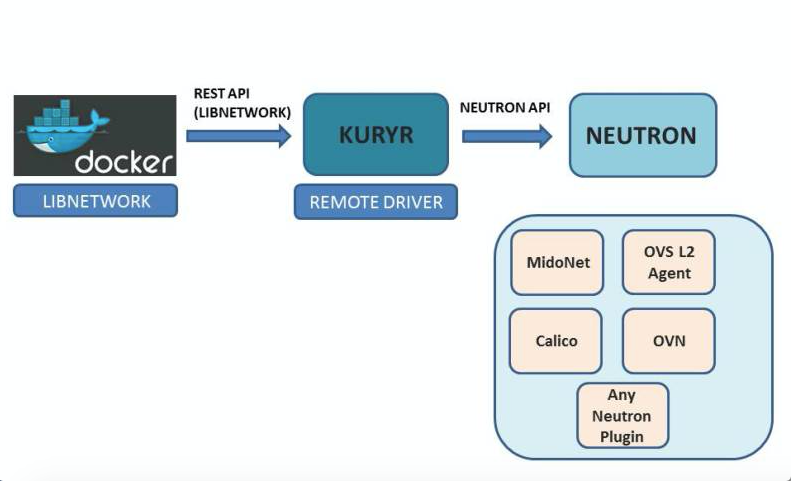
基於Kuryr的組網方案
Docker從1.6版本開始,將網路部分抽離出來成為Libnetwork專案,使得第三方可以以外掛機制為Dockers容器開發不同網路管理方案。Libnetwork包括4種驅動型別:
- Null:顧名思義,就是沒有網路支援。
- Bridge:傳統的Docker0網橋機制,只適用於單主機容器之間的通訊,不能支援跨主機通訊。
- Overlay:在下層主機網路的上層,基於隧道封裝機制,搭建層疊網路,實現跨主機的通訊;Overlay無疑是架構最簡單清晰的網路實現機制,但資料通訊效能則大受影響。
- Remote:Remote驅動並不真正實現驅動,而是以REST服務的方式定義了與第三方網路驅動互動的機制和管理介面。第三方容器網路方案主要通過這一機制與Docker整合。
說到這裡,必須要提到OpenStack的容器網路管理專案Kuryr,正是一個Remote驅動的實現,整合Dockers和Openstack Neutron網路。Kuryr英文的原意是信使的意思,本身也不是網路配置的一個具體實現,而是來自Docker使用者操作意圖轉換為對Openstack Neutron API的操作意圖。具體來說,容器管理平臺的操作會通過以下方式與Openstack整合:
- Kubernetes的網路配置管理操作(例如Kubectl命令)會由一個Kubectl操作轉換成對Dockers引擎的操作;
- Dockers引擎的操作轉換成對Libnetwork的Remote驅動的操作;
- 對Remote驅動的操作,通過Kuryr轉換成對Neutron API的操作;
- 對Neutron API的操作,通過Neutron外掛的機制轉換成對具體網路方案驅動的操作。
相對於Docker網路驅動,Flannel是CoreOS團隊針對Kubernetes設計的一個網路規劃服務;簡單來說,它的功能是讓叢集中的不同節點主機建立的Docker容器都具有全叢集唯一的虛擬IP地址,並使Docker容器可以互連。
基於Flannel網路的組網方案
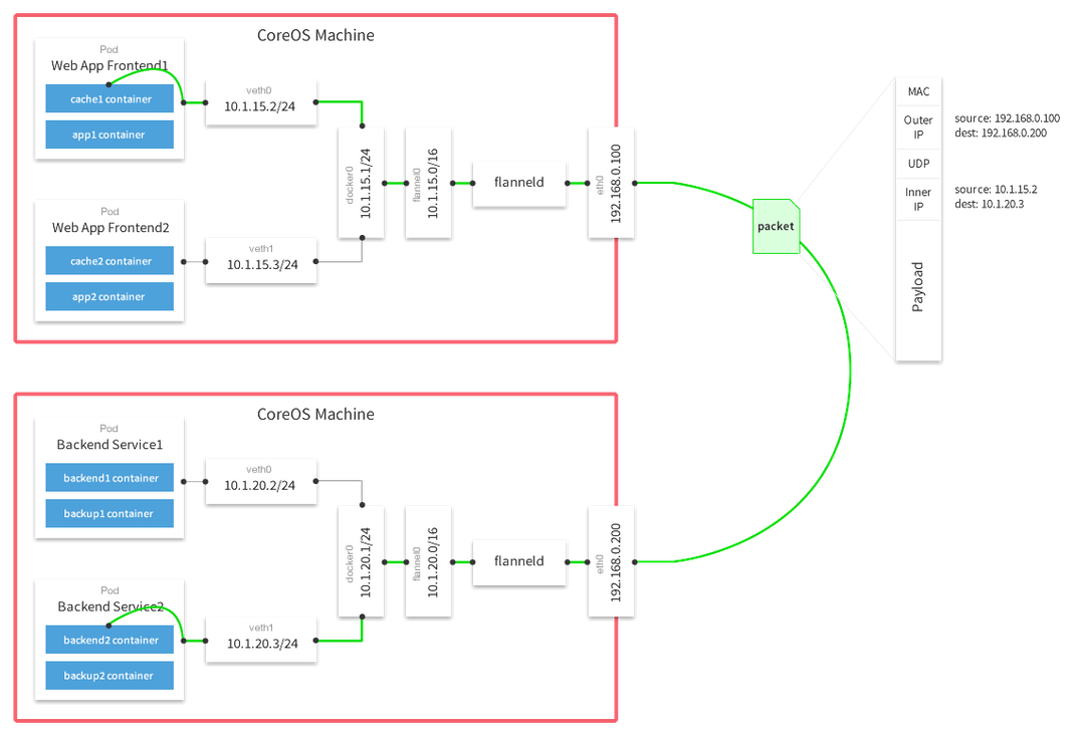
在整合Kubernetes的網路方案中,基於Flannel的網路方案Kubernetes的預設實現也是配置最簡單直接的。在Flannel網路中,容器的IP地址和服務節點的IP地址處於不同的網段,例如將10.1.0.0/16網段都用於容器網路,將192.168.0.0/24網段用於服務節點。每個Kubernetes服務節點上的Pod會形成一個獨立子網,例如節點192.168.0.100上的容器子網為10.1.15.0/24;容器子網與服務節點的對應關係儲存在Etcd上。每個服務節點都會安裝flanneld程式,flanneld程式會截獲所有發向容器叢集網段10.1.0.0/24的資料包。對於發向容器叢集網段的資料包,如果是指向其他節點對應的容器地址的,flannel會通過隧道協議封裝成指向目的服務節點的資料包;如果是指向本節點對應的容器地址的,flannel將會轉發給docker0。Flannel支援不同的隧道封裝協議,常用的是Flannel UDP和Flannel VxLan,根據實際測試結果,VxLan封裝在吞吐量和網路延時效能上都要好於UDP,因此一般推薦使用VxLan的封裝方式。
在Kubernetes叢集中的Flannel網路非常類似於Docker網路的Overlay驅動,都是基於隧道封裝的層疊網路,優勢和劣勢都是非常明顯的。
層疊網路的優勢
- 1.對底層網路依賴較少,不管底層是物理網路還是虛擬網路,對層疊網路的配置管理影響較少;
- 2.配置簡單,邏輯清晰,易於理解和學習,非常適用於開發測試等對網路效能要求不高的場景。
層疊網路的劣勢
- 1.網路封裝是一種傳輸開銷,對網路效能會有影響,不適用於對網路效能要求高的生產場景;
- 2.由於對底層網路結構缺乏瞭解,無法做到真正有效的流量工程控制,也會對網路效能產生影響;
- 3.某些情況下也不能完全做到與下層網路無關,例如隧道封裝會對網路的MTU限制產生影響。
基於Calico網路的組網方案
與其他的SDN網路方案相比,Calico有其獨特的特點,就是非層疊網路,不需要隧道封裝機制,依靠現有的三層路由協議來實現軟體定義網路(SDN)。Calico利用iBGP即內部閘道器協議來實現對資料包轉發的控制。在基於隧道封裝的網路方案中,網路控制器將宿主機當作隧道封裝的閘道器,來封裝來自虛擬機器或容器的資料包通過第四層的傳輸層傳送到目的宿主機做處理;與此相對,Calico網路中的控制器將宿主機當作內部閘道器協議中的閘道器節點,將來自虛擬機器或容器的資料包通過第三層的路由傳送到目的宿主機做處理。內部閘道器協議的一個特點是要求閘道器節點的全連線,即要求所有閘道器節點之間兩兩連線;顯然,這樣鏈路數隨節點的增長速度是平方級的,會導致鏈路數的暴漲。為解決這個問題,當節點較多時,要引入路由反射器(RR)。路由反射器的作用是將一個全連線網路轉變成一個星形網路,由路由反射器作為星形網路的中心連線所有節點,使得其他節點不需要直接連線,從而使鏈路數從O(n2)變為O(n)。因此Calico的解決方案是所有節點中選擇一些節點做為路由反射器,路由反射器之間是全聯通的,非路由反射器節點之間則需要路由反射器間接連線。
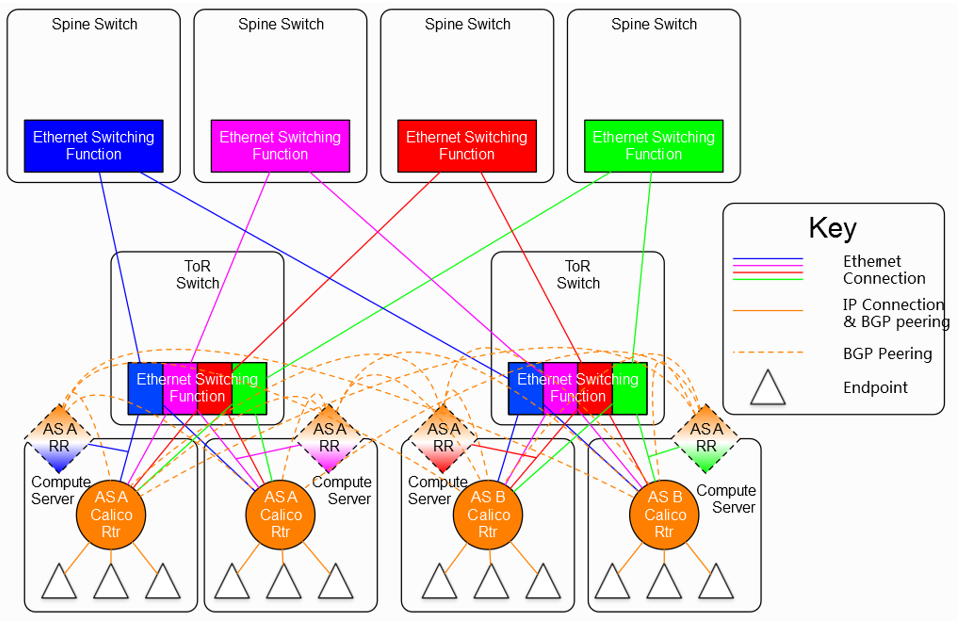
圖 7 包含路由反射器的Calico網路結構圖
Calico網路的優勢
- 1.沒有隧道封裝的網路開銷;
- 2.相比於通過Overlay構成的大二層層疊網路,用iBGP構成的扁平三層網路擴充套件模式更符合傳統IP網路的分散式結構;
- 3.不會對物理層網路的二層引數如MTU引入新的要求。
Calico網路的劣勢
- 1.最大的問題是不容易支援多租戶,由於沒有封裝,所有的虛擬機器或者容器只能通過真實的IP來區分自己,這就要求所有租戶的虛擬機器或容器統一分配一個地址空間;而在典型的支援多租戶的網路環境中,每個租戶可以分配自己的私有網路地址,租戶之間即使地址相同也不會有衝突;
- 2.不容易與其他基於主機路由的網路應用整合。
不同網路方案對OpenStack和Kubernetes的影響
總結一下引入Kuryr,Overlay和Calico技術對雲平臺解決方案的作用和帶來的影響。如果我們形象地比喻一下不同的組網技術的話,基於Overlay的組網技術是最重的,開銷最大的,但也是最穩定的,就像一隻烏龜;基於Calico的組網技術較為輕量級,但與複雜的網路環境整合就不太穩定,就像一隻蹦蹦跳跳的兔子;基於Kuryr的技術,因為Kuryr本身並不提供網路控制功能,而只是提供下面一層網路控制功能到容器網路的管理介面封裝,就像穿了一件馬甲或戴了一頂帽子。

在一個集成了OpenStack和Kubernetes的平臺,分別在OpenStack層和Kubernetes層要引入一種網路解決方案,OpenStack在下層,Kubernetes在上層。考慮作為IaaS層服務,多租戶隔離和二層網路的支援對OpenStack網路更為重要,某些組合的網路方案基本可以排除:例如,Kuryr作為一個管理容器網路的框架,一定要應用在Kubernetes層,而不是在下面的OpenStack層,於是,所有將Kuryr作為OpenStack層組網的方案都可以排除。
綜合OpenStack層和Kubernetes層網路,較為合理的網路方案可能為以下幾種:
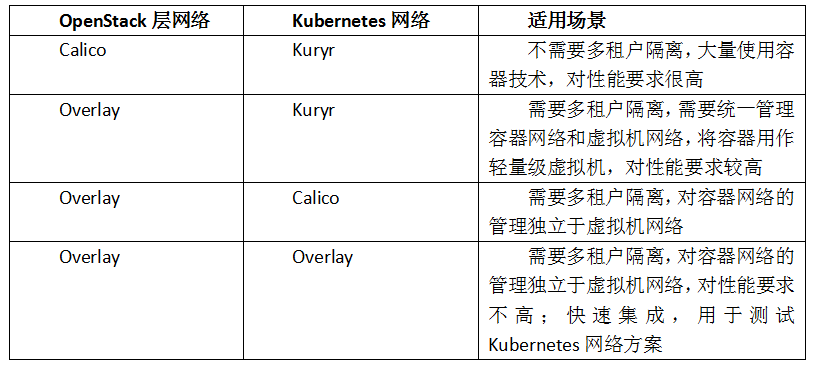

如上圖所示,第一種組合,底層用Calico連通OpenStack網路,上層用Kuryr將容器網路與IaaS網路打通,像一個小兔子戴帽子;這種組網方式無疑效能開銷是最少的,但因為沒有方便的多租戶隔離,不適合需要多租戶隔離的場景。第二種組合,底層用Overlay進行多租戶隔離,上層用Kuryr將容器網路與IaaS網路打通,像一個烏龜戴帽子;這種組網方式兼顧了效能和多租戶隔離的簡便性,比較適合統一管理容器和虛擬機器的網路方案。第三種組合,底層用Overlay進行多租戶隔離,上層用Calico實現容器叢集組網,像小兔子站在烏龜上;這種組網方式下,效能較好,容器層的網路管理基本獨立於IaaS層,有利於實驗驗證Calico跟Kubernetes的整合,但實踐中Calico的組網方式還是稍顯複雜。第四種組合,上下兩層都是Overlay網路,好像兩個烏龜壘在一起,是一種效能開銷最大的方式,但同時也是初期最容易搭建和實現的組網方式,比較適合於快速整合和驗證Kubernetes的整體功能。
總結
本文探討了基於OpenStack和Kubernetes構建雲平臺過程中,網路層面的技術解決方案。特別的,我們介紹瞭如何在基於OpenStack和Kubernetes的雲平臺中,實現租戶隔離和服務對外發布。同時,我們介紹了Kubernetes的可替換叢集組網模型,探討了幾種不同技術特點的組網方式,分析了Kuryr、Flannel和Calico這些網路技術的特點和對系統的技術影響,並探討了OpenStack和Kubernetes不同組網方案的適用場景。
轉自: http://geek.csdn.net/news/detail/104150