
JDK1.8 ConcurrentHashMap原始碼分析
文章目錄
ConcurrentHashMap是conccurrent家族中的一個類,由於它可以高效地支援併發操作,以及被廣泛使用, 經典的開源框架spring的底層資料結構就是使用ConcurrentHashMap實現的。與同是執行緒安全的老大哥HashTable相比,它已經更勝一籌,因此它的鎖更加細化,而不是像HashTable一樣為幾乎每個方法都添加了synchronized鎖,這樣的鎖無疑會影響到效能。
本文的分析的原始碼是JDK8的版本,與JDK6的版本有很大的差異。實現執行緒安全的思想也已經完全變了,它摒棄了Segment(鎖段)的概念,而是啟用了一種全新的方式實現,利用
ConcurrentHashMap資料結構
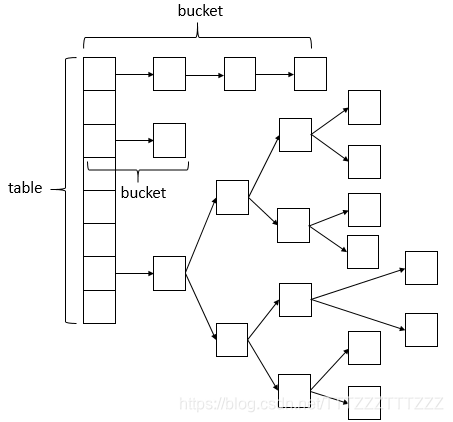
ConcurrentHashMap的資料結構(陣列+連結串列+紅黑樹),桶中的結構可能是連結串列,也可能是紅黑樹,紅黑樹是為了提高查詢效率。
類的繼承關係
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {}
ConcurrentHashMap繼承了AbstractMap抽象類,該抽象類定義了一些基本操作,同時,也實現了ConcurrentMap介面,ConcurrentMap介面也定義了一系列操作,實現了Serializable介面表示ConcurrentHashMap可以被序列化
類的內部類
ConcurrentHashMap包含了很多內部類,其中主要的內部類框架圖如下圖所示
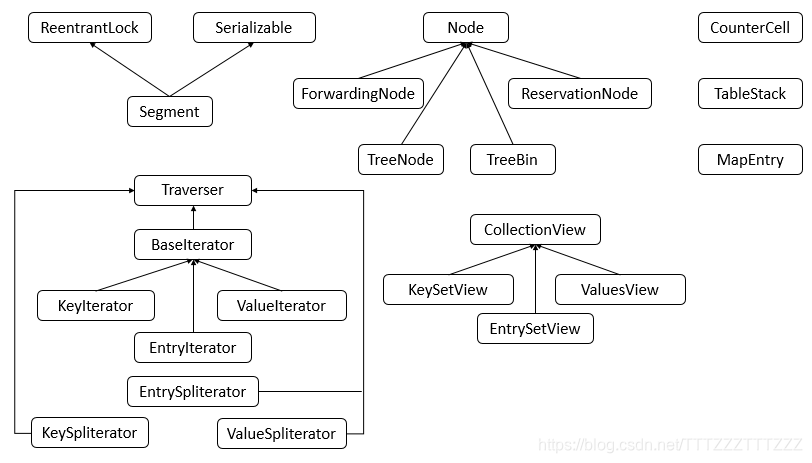
可以看到,ConcurrentHashMap的內部類非常的龐大,第二個圖是在JDK1.8下增加的類,下面對其中主要的內部類進行分析和講解。
-
Node類
Node類主要用於儲存具體鍵值對,其子類有ForwardingNode、ReservationNode、TreeNode和TreeBin四個子類。四個子類具體的程式碼在之後的具體例子中進行分析講解。 -
Traverser類
Traverser類主要用於遍歷操作,其子類有BaseIterator、KeySpliterator、ValueSpliterator、EntrySpliterator四個類,BaseIterator用於遍歷操作。KeySplitertor、ValueSpliterator、EntrySpliterator則用於鍵、值、鍵值對的劃分。 -
CollectionView類
CollectionView抽象類主要定義了檢視操作,其子類KeySetView、ValueSetView、EntrySetView分別表示鍵檢視、值檢視、鍵值對檢視。對檢視均可以進行操作。 -
Segment類
Segment類在JDK1.8中與之前的版本的JDK作用存在很大的差別,JDK1.8下,其在普通的ConcurrentHashMap操作中已經沒有失效,其在序列化與反序列化的時候會發揮作用。 -
CounterCell
CounterCell類主要用於對baseCount的計數。
重要的屬性
首先來看幾個重要的屬性,與HashMap相同的就不再介紹了,這裡重點解釋一下sizeCtl這個屬性。可以說它是ConcurrentHashMap中出鏡率很高的一個屬性,因為它是一個控制識別符號,在不同的地方有不同用途,而且它的取值不同,也代表不同的含義。
- 負數代表正在進行初始化或擴容操作
- -1代表正在初始化
- -N 表示有N-1個執行緒正在進行擴容操作
- 正數或0代表hash表還沒有被初始化,這個數值表示初始化或下一次進行擴容的大小,這一點類似於擴容閾值的概念。還後面可以看到,它的值始終是當前ConcurrentHashMap容量的0.75倍,這與loadfactor是對應的
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
private static final long serialVersionUID = 7249069246763182397L;
// 表的最大容量
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 預設表的大小
private static final int DEFAULT_CAPACITY = 16;
// 最大陣列大小
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 預設併發數
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 裝載因子
private static final float LOAD_FACTOR = 0.75f;
// 轉化為紅黑樹的閾值
static final int TREEIFY_THRESHOLD = 8;
// 由紅黑樹轉化為連結串列的閾值
static final int UNTREEIFY_THRESHOLD = 6;
// 轉化為紅黑樹的表的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
// 每次進行轉移的最小值
private static final int MIN_TRANSFER_STRIDE = 16;
// 生成sizeCtl所使用的bit位數
private static int RESIZE_STAMP_BITS = 16;
// 進行擴容所允許的最大執行緒數
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 記錄sizeCtl中的大小所需要進行的偏移位數
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// 一系列的標識
static final int MOVED = -1;// hash值是-1,表示這是一個forwardNode節點
static final int TREEBIN = -2; // hash值是-2 表示這時一個TreeBin節點
static final int RESERVED = -3; // hash for transient reservations
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
//
/** Number of CPUS, to place bounds on some sizings */
// 獲取可用的CPU個數
static final int NCPU = Runtime.getRuntime().availableProcessors();
//
/** For serialization compatibility. */
// 進行序列化的屬性
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("segments", Segment[].class),
new ObjectStreamField("segmentMask", Integer.TYPE),
new ObjectStreamField("segmentShift", Integer.TYPE)
};
/**
* 盛裝Node元素的陣列 它的大小是2的整數次冪
* Size is always a power of two. Accessed directly by iterators.
*/
transient volatile Node<K,V>[] table;
// 下一個表
private transient volatile Node<K,V>[] nextTable;
//
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
// 基本計數
private transient volatile long baseCount;
//
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
hash表初始化或擴容時的一個控制位標識量。
負數代表正在進行初始化或擴容操作
-1代表正在初始化
-N 表示有N-1個執行緒正在進行擴容操作
正數或0代表hash表還沒有被初始化,這個數值表示初始化或下一次進行擴容的大小
*/
private transient volatile int sizeCtl;
/**
* The next table index (plus one) to split while resizing.
*/
// 擴容下另一個表的索引
private transient volatile int transferIndex;
/**
* Spinlock (locked via CAS) used when resizing and/or creating CounterCells.
*/
// 旋轉鎖
private transient volatile int cellsBusy;
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
// counterCell表
private transient volatile CounterCell[] counterCells;
// views
// 檢視
private transient KeySetView<K,V> keySet;
private transient ValuesView<K,V> values;
private transient EntrySetView<K,V> entrySet;
// Unsafe mechanics
private static final sun.misc.Unsafe U;
private static final long SIZECTL;
private static final long TRANSFERINDEX;
private static final long BASECOUNT;
private static final long CELLSBUSY;
private static final long CELLVALUE;
private static final long ABASE;
private static final int ASHIFT;
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentHashMap.class;
SIZECTL = U.objectFieldOffset
(k.getDeclaredField("sizeCtl"));
TRANSFERINDEX = U.objectFieldOffset
(k.getDeclaredField("transferIndex"));
BASECOUNT = U.objectFieldOffset
(k.getDeclaredField("baseCount"));
CELLSBUSY = U.objectFieldOffset
(k.getDeclaredField("cellsBusy"));
Class<?> ck = CounterCell.class;
CELLVALUE = U.objectFieldOffset
(ck.getDeclaredField("value"));
Class<?> ak = Node[].class;
ABASE = U.arrayBaseOffset(ak);
int scale = U.arrayIndexScale(ak);
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
}
}
類的建構函式
ConcurrentHashMap()型建構函式
public ConcurrentHashMap() {
}
該建構函式用於建立一個帶有預設初始容量 (16)、載入因子 (0.75) 和 concurrencyLevel (16) 的新的空對映。
ConcurrentHashMap(int)型建構函式
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0) // 初始容量小於0,丟擲異常
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); // 找到最接近該容量的2的冪次方數
// 初始化
this.sizeCtl = cap;
}
該建構函式用於建立一個帶有指定初始容量、預設載入因子 (0.75) 和 concurrencyLevel (16) 的新的空對映
ConcurrentHashMap(Map<? extends K, ? extends V>)型建構函式
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
// 將集合m的元素全部放入
putAll(m);
}
該建構函式用於構造一個與給定對映具有相同對映關係的新對映
ConcurrentHashMap(int, float)型建構函式
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
該建構函式用於建立一個帶有指定初始容量、載入因子和預設 concurrencyLevel (1) 的新的空對映
ConcurrentHashMap(int, float, int)型建構函式
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) // 合法性判斷
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
說明:該建構函式用於建立一個帶有指定初始容量、載入因子和併發級別的新的空對映。
對於建構函式而言,會根據輸入的initialCapacity的大小來確定一個最小的且大於等於initialCapacity大小的2的n次冪,如initialCapacity為15,則sizeCtl為16,若initialCapacity為16,則sizeCtl為16。若initialCapacity大小超過了允許的最大值,則sizeCtl為最大值。值得注意的是,建構函式中的concurrencyLevel引數已經在JDK1.8中的意義發生了很大的變化,其並不代表所允許的併發數,其只是用來確定sizeCtl大小,在JDK1.8中的併發控制都是針對具體的桶而言,即有多少個桶就可以允許多少個併發數。
重要的內部類
Node
Node是最核心的內部類,它包裝了key-value鍵值對,所有插入ConcurrentHashMap的資料都包裝在這裡面。它與HashMap中的定義很相似,但是但是有一些差別它對value和next屬性設定了volatile同步鎖,它不允許呼叫setValue方法直接改變Node的value域,它增加了find方法輔助map.get()方法。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;//帶有同步鎖的value
volatile Node<K,V> next;//帶有同步鎖的next指標
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
//不允許直接改變value的值
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
這個Node內部類與HashMap中定義的Node類很相似,但是有一些差別
它對value和next屬性設定了volatile同步鎖
它不允許呼叫setValue方法直接改變Node的value域
它增加了find方法輔助map.get()方法
TreeNode
樹節點類,另外一個核心的資料結構。當連結串列長度過長的時候,會轉換為TreeNode。但是與HashMap不相同的是,它並不是直接轉換為紅黑樹,而是把這些結點包裝成TreeNode放在TreeBin物件中,由TreeBin完成對紅黑樹的包裝。而且TreeNode在ConcurrentHashMap整合自Node類,而並非HashMap中的整合自LinkedHashMap.Entry<K,V>類,也就是說TreeNode帶有next指標,這樣做的目的是方便基於TreeBin的訪問
TreeBin
這個類並不負責包裝使用者的key、value資訊,而是包裝的很多TreeNode節點。它代替了TreeNode的根節點,也就是說在實際的ConcurrentHashMap“陣列”中,存放的是TreeBin物件,而不是TreeNode物件,這是與HashMap的區別。另外這個類還帶有了讀寫鎖。
這裡僅貼出它的構造方法。可以看到在構造TreeBin節點時,僅僅指定了它的hash值為TREEBIN常量,這也就是個標識為。同時也看到我們熟悉的紅黑樹構造方法
/**
* Creates bin with initial set of nodes headed by b.
*/
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null);
this.first = b;
TreeNode<K,V> r = null;
for (TreeNode<K,V> x = b, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (r == null) {
x.parent = null;
x.red = false;
r = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = r;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
r = balanceInsertion(r, x);
break;
}
}
}
}
this.root = r;
assert checkInvariants(root);
}
ForwardingNode
一個用於連線兩個table的節點類。它包含一個nextTable指標,用於指向下一張表。而且這個節點的key value next指標全部為null,它的hash值為-1. 這裡面定義的find的方法是從nextTable裡進行查詢節點,而不是以自身為頭節點進行查詢
/