
NSDictionary和NSMutableArray底層原理(雜湊表和環形緩衝區)
前言
1.NSDictionary底層是雜湊表,下面會介紹具體是用拉鍊法還是開放定址法線性探測來解決衝突?由於Apple給的查詢複雜度可以快至O(1),那麼為什麼是O(1),底層是如何通過空間換取時間的?
2.NSArray是線性連續記憶體,這個很好理解。但是NSMutableArray是可以插入和刪除的,那麼如何做到高效?就比如插入,如何做到儘可能少的移動或者不移動插入元素後其他元素的記憶體?實現資料結構原理是什麼?
以上兩個問題,我找到了兩個寫的非常好的文章,自己在此記錄下,需要的可以直接傳送,以下內容都是來自下面兩個大神的文章
NSDictionary底層原理
桶排序是典型的空間換時間,可以讓排序時間打到O(n)
建立N個空桶,N為排序陣列中最大值加一。然後遍歷排序陣列,以元素值為下標,將其放入對應的桶中
如果少量資料,可以根據數組裡面的最大值+1創建出那麼多空桶,然後遍歷,根據索引在空桶的值上累加,最後遍歷空桶(已裝載),根據值遍歷出對應的下標
雖然這樣做效率非常高,但是如果資料過大,記憶體吃不消,這樣就有了雜湊排序的介紹。例如一組資料,我們可以根據hash演算法後取模的值進行空桶排列,但是如果兩個值例如 101和11 % 10都是餘1,會被放入同一個桶裡面,這樣就會有需要二次排列。雖然這個排序效率並不高,因此雜湊化就變成了資料儲存的一種設計。
字典介紹
Foundation框架下提供了很多高階資料結構,這些都是對Core Foundation下的封裝,例如NSDictionary就是對_CFDictionary的封裝,
struct __CFDictionary {
CFRuntimeBase _base;
CFIndex _count;
CFIndex _capacity;
CFIndex _bucketsNum;
uintptr_t _marker;
void *_context;
CFIndex _deletes;
CFOptionFlags _xflags;
const void **_keys;
const void **_values;
};根據資料結構可以發現dictionary內部使用了兩個指標陣列分別來儲存keys
values,先不去討論這兩個陣列的元素如何形成對應關係,已知的是dictionary採用的是連續儲存的方式儲存鍵值對,因此接下來我們將一步步瞭解字典是如何完成key-value的匹配過程。
hash
這裡的hash指的不是上面的雜湊排序或者hash化,而是一個方法。在OC中,萬物皆NSObject的子孫,NSObject某種意義上來說等同於OC的上帝類,作為所有類的基類,NSObject提供了諸多介面,大多數的介面在日常開發中都不會被主動呼叫,比如有這麼一段程式碼:
NSArray *nums = @[@(1), @(2), @(3), @(4), @(5)];
NSLog(@"%zd", [nums containsObject: @(1)]);程式碼是為了檢測在陣列中是否存在@(1)這個物件,而在執行時,蘋果為了提高匹配兩個物件是否相同的效率,會先判斷兩個物件的hash方法返回值是否相等,再進行進一步的判斷。hash方法一般耗時在納秒級,這能有效的減少匹配的耗時:
- (BOOL)compareObj1: (id)obj1 withObj2: (id)obj2 {
if ([obj1 hash] == [obj2 hash]) {
return [obj1 isEqual: obj2];
}
return NO;
}原則上,hash結果應該通過合理的運算來儘可能的避免衝突,比如MD5是一種相當優秀的hash化,但這並不代表hash的實現難度很高。實際上只要hash的結果能夠體現出資料的特徵就行了,比如字典的hash實現非常任性的返回了鍵值對個數:
static CFHashCode __CFDictionaryHash(CFTypeRef cf) {
CFDictionaryRef dict = (CFDictionaryRef)cf;
return dict->_count;
}那麼可以得到一個初步的結論:相等變數的hash結果總是相同的,不相等變數的hash結果有可能相同。在繼續之前,我們再明確一個概念:
hash化是一個取得變數特徵的過程,這個過程可以是取出變數的特徵,也可以是一個計算
從dictionary的結構中可以看到keys大概率是一個數組,那麼當物件完成hash化運算,這個計算結果要如何和陣列實現位置匹配?由於儲存結構的特性,計算機的hash化幾乎總是返回一個非負整數,因此這個匹配過程就變得相當簡單——相同的數值的求餘結果總是相同的。下面將通過字典的key的匹配過程來論證這點,基於不同的初始化,這個hash化存在兩種運算。程式碼忽略其他邏輯:
static CFIndex __CFDictionaryFindBucketsXX(CFDictionaryRef dict, const void *key) {
/// 建立字典時傳入__kCFDictionaryHasNullCallBacks宣告key無法進行hash運算,直接使用物件地址作為keyHash
CFHashCode keyHash = (CFHashCode)key;
/// 建立字典時傳入其他配置,key存在hash實現程式碼,使用hash函式的結果值作為keyHash
CFHashCode keyHash = cb->hash ? (CFHashCode)INVOKE_CALLBACK2(((CFHashCode (*)(const void *, void *))cb->hash), key, dict->_context) : (CFHashCode)key;
const void **keys = dict->_keys;
CFIndex probe = keyHash % dict->_bucketsNum;
......
}但是hash過程中必定會出現衝突,如何來處理衝突?
開放定址法
在上文介紹雜湊排序時,解決hash碰撞的方式是將發生碰撞的多個元素放到一個容器中,這個容器通常使用連結串列結構,這種解決方案被稱作拉鍊法。試想一下,假如dictionary也採用這種方案解決衝突,為了能匹配到正確的資料,必然要使用一個複合結構儲存key和value的資料,然後碰撞發生時遍歷容器查詢匹配的key-value:

從設計結構上來看,這個方案能夠解決hash碰撞的匹配問題。但拉鍊法會將key和value包裝成一個結構儲存,而dictionary的結構擁有keys和values這兩個陣列,說明了這兩個資料是被分開儲存的,所以使用這個方案的可能性不高。而且拉鍊法存在一個問題:
桶數量不多的情況下,拉鍊衍生出來的連結串列會非常龐大,需要二次遍歷,匹配損耗一樣很大,這樣等於沒有優化一樣。官方都說了查詢演算法接近O(1),因此肯定不是拉鍊法,下面就有了開放定址法。
明白開發原理之後,我們可以看到,資料的衍生,會很容易把表儲存滿,這裡可以就有了擴容的概念。
為了解決這個問題,使用開放定址法的結構通常允許在通列表的數量達到了某個閾值,通常是通列表長度的80%使用量時,對通列表進行一次擴充grow,然後重新計算資料的keyHash放入新桶中
開放定址法可以通過動態擴充通列表長度解決了滿桶無法插入的問題,也符合O(1)的查詢速度,但同樣隨著資料量的增加,資料會明顯的集中在某一段連續區域,稱作堆積現象。基本可以確定dictionary就是採用這種解決方式來實現keyHash的資料存放問題。通過閱讀setValue的實現,也可以印證這個設計。下面程式碼已除去了無關邏輯:
/// set value for key
void CFDictionarySetValue(CFMutableDictionaryRef dict, const void *key, const void *value) {
/// 假如字典中存在key,match返回keyHash的儲存位置
/// 假如字典中不存在key,nomatch儲存插入key的儲存位置
CFIndex match, nomatch;
__CFDictionaryFindBuckets2(dict, key, &match, &nomatch);
......
if (kCFNotFound != match) {
/// 字典中已經存在key,修改操作
CF_OBJC_KVO_WILLCHANGE(dict, key);
......
CF_WRITE_BARRIER_ASSIGN(valuesAllocator, dict->_values[match], newValue);
CF_OBJC_KVO_DIDCHANGE(dict, key);
} else {
/// 字典中不存在key,新增操作
......
CF_OBJC_KVO_WILLCHANGE(dict, key);
CF_WRITE_BARRIER_ASSIGN(keysAllocator, dict->_keys[nomatch], newKey);
CF_WRITE_BARRIER_ASSIGN(valuesAllocator, dict->_values[nomatch], newValue);
dict->_count++;
CF_OBJC_KVO_DIDCHANGE(dict, key);
}
}
/// 查詢key儲存位置
static void __CFDictionaryFindBuckets2(CFDictionaryRef dict, const void *key, CFIndex *match, CFIndex *nomatch) {
/// 對key進行hash化,獲取keyHash
const CFDictionaryKeyCallBacks *cb = __CFDictionaryGetKeyCallBacks(dict);
CFHashCode keyHash = cb->hash ? (CFHashCode)INVOKE_CALLBACK2(((CFHashCode (*)(const void *, void *))cb->hash), key, dict->_context) : (CFHashCode)key;
const void **keys = dict->_keys;
uintptr_t marker = dict->_marker;
CFIndex probe = keyHash % dict->_bucketsNum;
CFIndex probeskip = 1;
CFIndex start = probe;
*match = kCFNotFound;
*nomatch = kCFNotFound;
for (;;) {
uintptr_t currKey = (uintptr_t)keys[probe];
/// 如果keyHash對應的桶是空桶,那麼標記nomatch,返回未匹配
if (marker == currKey) {
if (nomatch) *nomatch = probe;
return;
} else if (~marker == currKey) {
if (nomatch) {
*nomatch = probe;
nomatch = NULL;
}
} else if (currKey == (uintptr_t)key || (cb->equal && INVOKE_CALLBACK3((Boolean (*)(const void *, const void *, void*))cb->equal, (void *)currKey, key, dict->_context))) {
*match = probe;
return;
}
/// 如果未匹配,說明發生了衝突,那麼將桶下標向後移動,直到找到空桶位置
probe = probe + probeskip;
if (dict->_bucketsNum <= probe) {
probe -= dict->_bucketsNum;
}
if (start == probe) {
return;
}
}
}我們剛才在CFDictionary的結構體的時候看到了key和values這兩個二級指標,可以基本斷定為陣列結構,由於是兩個陣列分別儲存,因此,key雜湊出來的陣列下標地址,同樣這個地址對應到values陣列的下標,就是匹配到的值。因此keys和values這兩個陣列的長度一致才能保證匹配到資料。內部結構還有個_capacity表示當前通列表的擴充閥域 ,當count數量達到這個長度就擴容
/// 桶列表擴充閾值
static const uint32_t __CFDictionaryCapacities[42] = {
4, 8, 17, 29, 47, 76, 123, 199, 322, 521, 843, 1364, 2207, 3571, 5778, 9349,
15127, 24476, 39603, 64079, 103682, 167761, 271443, 439204, 710647, 1149851, 1860498,
3010349, 4870847, 7881196, 12752043, 20633239, 33385282, 54018521, 87403803, 141422324,
228826127, 370248451, 599074578, 969323029, 1568397607, 2537720636U
};
/// 桶列表長度
static const uint32_t __CFDictionaryBuckets[42] = {
5, 11, 23, 41, 67, 113, 199, 317, 521, 839, 1361, 2207, 3571, 5779, 9349, 15121,
24473, 39607, 64081, 103681, 167759, 271429, 439199, 710641, 1149857, 1860503, 3010349,
4870843, 7881193, 12752029, 20633237, 33385273, 54018521, 87403763, 141422317, 228826121,
370248451, 599074561, 969323023, 1568397599, 2537720629U, 4106118251U
};
/// 匹配下一個擴充閾值
CF_INLINE CFIndex __CFDictionaryRoundUpCapacity(CFIndex capacity) {
CFIndex idx;
for (idx = 0; idx < 42 && __CFDictionaryCapacities[idx] < (uint32_t)capacity; idx++);
if (42 <= idx) HALT;
return __CFDictionaryCapacities[idx];
}
/// 匹配下一個桶列表長度
CF_INLINE CFIndex __CFDictionaryNumBucketsForCapacity(CFIndex capacity) {
CFIndex idx;
for (idx = 0; idx < 42 && __CFDictionaryCapacities[idx] < (uint32_t)capacity; idx++);
if (42 <= idx) HALT;
return __CFDictionaryBuckets[idx];
}
/// set value for key
void CFDictionarySetValue(CFMutableDictionaryRef dict, const void *key, const void *value) {
......
if (dict->_count == dict->_capacity || NULL == dict->_keys) {
__CFDictionaryGrow(dict, 1);
}
......
}
/// 擴充
static void __CFDictionaryGrow(CFMutableDictionaryRef dict, CFIndex numNewValues) {
/// 儲存當前keys和values的資料,計算出新的長度
const void **oldkeys = dict->_keys;
const void **oldvalues = dict->_values;
CFIndex idx, oldnbuckets = dict->_bucketsNum;
CFIndex oldCount = dict->_count;
CFAllocatorRef allocator = __CFGetAllocator(dict), keysAllocator, valuesAllocator;
void *keysBase, *valuesBase;
dict->_capacity = __CFDictionaryRoundUpCapacity(oldCount + numNewValues);
dict->_bucketsNum = __CFDictionaryNumBucketsForCapacity(dict->_capacity);
dict->_deletes = 0;
......
/// 擴充keys和values陣列
CF_WRITE_BARRIER_BASE_ASSIGN(allocator, dict, dict->_keys, _CFAllocatorAllocateGC(allocator, 2 * dict->_bucketsNum * sizeof(const void *), AUTO_MEMORY_SCANNED));
dict->_values = (const void **)(dict->_keys + dict->_bucketsNum);
keysAllocator = valuesAllocator = allocator;
keysBase = valuesBase = dict->_keys;
if (NULL == dict->_keys || NULL == dict->_values) HALT;
......
/// 重新計算keys資料的hash值,存放到新的列表裡
for (idx = dict->_bucketsNum; idx--;) {
dict->_keys[idx] = (const void *)dict->_marker;
dict->_values[idx] = 0;
}
if (NULL == oldkeys) return;
for (idx = 0; idx < oldnbuckets; idx++) {
if (dict->_marker != (uintptr_t)oldkeys[idx] && ~dict->_marker != (uintptr_t)oldkeys[idx]) {
CFIndex match, nomatch;
__CFDictionaryFindBuckets2(dict, oldkeys[idx], &match, &nomatch);
CFAssert3(kCFNotFound == match, __kCFLogAssertion, "%s(): two values (%p, %p) now hash to the same slot; mutable value changed while in table or hash value is not immutable", __PRETTY_FUNCTION__, oldkeys[idx], dict->_keys[match]);
if (kCFNotFound != nomatch) {
CF_WRITE_BARRIER_BASE_ASSIGN(keysAllocator, keysBase, dict->_keys[nomatch], oldkeys[idx]);
CF_WRITE_BARRIER_BASE_ASSIGN(valuesAllocator, valuesBase, dict->_values[nomatch], oldvalues[idx]);
}
}
}
......
}除了上述提到的拉鍊和開放定址,還有再雜湊以及建立公共溢位區域來解決衝突。
apple都用了,開放定址法應該是在三種方案中最優,它的缺點也非常明顯:
- 由於擴充幾乎是翻倍
grow,多次擴充後可能會存在大量的空桶,浪費空間 - 刪除元素時,為了影響後續元素查詢,需要對刪除位置做特殊處理,實現邏輯上更復雜
可以看到,NSDictionary設定的key和value,key值會根據特定的hash函式算出建立的空桶陣列,keys和values同樣多,然後儲存資料的時候,根據hash函式算出來的值,找到對應的index下標,如果下標已有資料,開放定址法後移動插入,如果空桶陣列到達資料閥值,這個時候就會把空桶陣列擴容,然後重新雜湊插入。這樣把一些不連續的key-value值插入到了能建立起關係的hash表中,當我們查詢的時候,key根據雜湊值算出來,然後根據索引,直接index訪問hash表keys和hash表values,這樣查詢速度就可以和連續線性儲存的資料一樣接近O(1)了,只是佔用空間有點大,效能就很強悍。如果刪除的時候,也會根據_maker標記邏輯上的刪除,除非NSDictionary(NSDictionary本體的hash值就是count)記憶體被移除。我們也會根據
dictionary之所以採用這種設計,其一出於查詢效能的考慮;其二dictionary在使用過程中總是會很快的被釋放,不會長期佔用記憶體。
associated object
關聯物件associated object是iOS開發常用的機制之一,它實現了不通過繼承來增加屬性這種需求。通過閱讀objc-references原始碼,可以發現關聯物件內部使用了巢狀dictionary的結構實現了物件的擴充套件屬性管理,也就是使用開放定址法的解決方案。下面程式碼去除了無關儲存的邏輯:
void _object_set_associative_reference(id object, void *key, id value, uintptr_t policy) {
/// 獲取associated object全域性map
AssociationsManager manager;
AssociationsHashMap &associations(manager.associations());
/// DISGUISE巨集定義獲取物件的唯一值,等同於hash方法
disguised_ptr_t disguised_object = DISGUISE(object);
if (new_value) {
AssociationsHashMap::iterator i = associations.find(disguised_object);
if (i != associations.end()) {
/// 結果不等於未匹配end()
ObjectAssociationMap *refs = i->second;
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
old_association = j->second;
j->second = ObjcAssociation(policy, new_value);
} else {
(*refs)[key] = ObjcAssociation(policy, new_value);
}
} else {
/// 物件未繫結過任何屬性,新增map儲存
ObjectAssociationMap *refs = new ObjectAssociationMap;
associations[disguised_object] = refs;
(*refs)[key] = ObjcAssociation(policy, new_value);
_class_setInstancesHaveAssociatedObjects(_object_getClass(object));
}
} else {
AssociationsHashMap::iterator i = associations.find(disguised_object);
/// 結果不等於未匹配end()
if (i != associations.end()) {
ObjectAssociationMap *refs = i->second;
ObjectAssociationMap::iterator j = refs->find(key);
if (j != refs->end()) {
old_association = j->second;
refs->erase(j);
}
}
}
}-
AssociationsHashMap是一個dictionary,以物件hash結果儲存了一個dictionary,用OC的泛型宣告來看,就是一個NSDictionary<id, NSDictionary *>的結構變數,這個變數是全域性的。 -
ObjectAssociationMap是被上面巢狀的dictionary,這個結構儲存了實際繫結的屬性值。在我們呼叫objc_setAssociatedObject的時候,會將傳入的key和value儲存在這裡面。
開放定址法在大量資料儲存時,會造成大量的空間佔用,為什麼associated object採用全域性物件的情況下依舊使用這種方案。這是因為雖然蘋果使用了一個全域性的AssociationsHashMap物件儲存了全部的關聯物件,但在物件dealloc時會移除這些資料,同一時間佔用的記憶體也是可接受的:
@synchronized
在上篇文章中我提到過@synchronized採用了hash + linked list的實現結構,原始碼參見objc-sync,實際上就是拉鍊法來解決碰撞問題。在程式碼編譯時,這個語句會被轉換成成對的兩個函式呼叫:
int objc_sync_enter(id obj);
int objc_sync_exit(id obj);
相比起一般的拉鍊法的設計,@synchronized增加了一個快取機制,下面是使用到的關鍵結構:
typedef struct SyncData {
struct SyncData* nextData;
id object;
int threadCount;
recursive_mutex_t mutex;
} SyncData;
typedef struct {
SyncData *data;
OSSpinLock lock;
char align[64 - sizeof (OSSpinLock) - sizeof (SyncData *)];
} SyncList __attribute__((aligned(64)));
#define COUNT 16
#define HASH(obj) ((((uintptr_t)(obj)) >> 5) & (COUNT - 1))
#define LOCK_FOR_OBJ(obj) sDataLists[HASH(obj)].lock
#define LIST_FOR_OBJ(obj) sDataLists[HASH(obj)].data
static SyncList sDataLists[COUNT];
在程式碼@synchronized(x)中,一開始有一個結構體定義 struct SyncData的定義,這個結構體包含一個object,就是之前傳入的x物件,以及和物件x關聯的鎖mutex,仔細看,還有個同類型的指標nextData,這很明顯是連結串列的特徵。最後每個結構體裡面還有個treadCount,這個是用來記錄物件鎖被執行緒使用的數量,當treadCount=0的時候沒有執行緒使用,就可以拿出來複用,賦值給新的物件。連結串列節點物件SyncData,那麼連結串列就是下面定義的SyncList,裡面有頭結點data,以及防止多執行緒修改連結串列頭結點的自旋鎖 OSSpinLock。這裡可以看出@synchronized(x)內部儲存是拉鍊法解決衝突的,因此設計了連結串列。下面來看下hash演算法HASH(obj),將物件的指標傳入,然後向右位移5,和COUNT-1進行與運算,這樣結果不會超過陣列長度,牛逼。那麼下面兩個巨集就很好理解了LOCK_FOR_OBJ和LIST_FOR_OBJ,傳入的物件進行HASH運算,算出0-15的一個index,然後陣列直接指標偏移以O(1),直接拿出資料,如果不同物件放在同一個index,衝突就在一條連結串列中,繼續遍歷連結串列拿資料
為什麼同樣是使用全域性儲存的實現方式下,
@synchronized採用的是拉鍊法,而associate object採用的是開放定址法
其實最重要的一點是儲存資料的生命週期和特性所決定的:
-
開放定址法的儲存屬性基本是和key所屬物件相關聯的,一旦key所屬物件發生變化時,其所儲存的資料大概率也是要發生修改的。因此即便是開放定址法在使用全域性實現時,物件釋放時同樣會清空所儲存的內容,因此總體來說記憶體佔用並不會過高。 -
拉鍊法對於碰撞的處理方式更為簡單,不用擔心資料的堆積現象。另外如果儲存的資料是通用型別資料,可以被反覆利用。比如@synchronized是儲存的鎖是一種無關業務的實現結構,程式執行時多個物件使用同一個鎖的概率相當的高,有效的節省了記憶體。
好像weak對應的引用計數根據物件地址維護了一張雜湊表,這裡由於weak指向的物件在釋放的時候,根據物件地址的雜湊函式地址計算出對應在雜湊表中的index,然後找到存到的指標(連結串列結構),然後都置為nil。記憶體釋放的時候採用雜湊結構,可以更更快找到對應地址對應的weak指標。我猜測是拉鍊法實現的
以上就是NSDictionary的內部原理介紹
內部結構keys和values兩個對應的陣列(一一對應),hash函式通過key的值計算出雜湊表的index,然後對應插入,下次訪問的時候直接在此計算key的hash函式index,直接按照連續控制元件的訪問順序訪問下標即可拿出資料,因此把無序和龐大的資料進行了空間雜湊表對應,下次查詢複雜度接近於O(1),但是不斷擴容的空間就是其弊端,因此開放地址法最好儲存的是臨時需要,儘快釋放的資源例如字典引數和associated object,拉鍊法就保證了資源的可控性,像這種@synchronized鎖就可以根據地址拉鍊出一條對應的使用執行緒即可,隨時使用。
NSMutableArray底層原理
c陣列問題
普通c陣列,歸根接地就是一段能被方便讀寫的連續記憶體控制元件。
使用一段線性記憶體空間的一個最明顯的缺點是,在下標 0 處插入一個元素時,需要移動其它所有的元素,即 memmove 的原理:
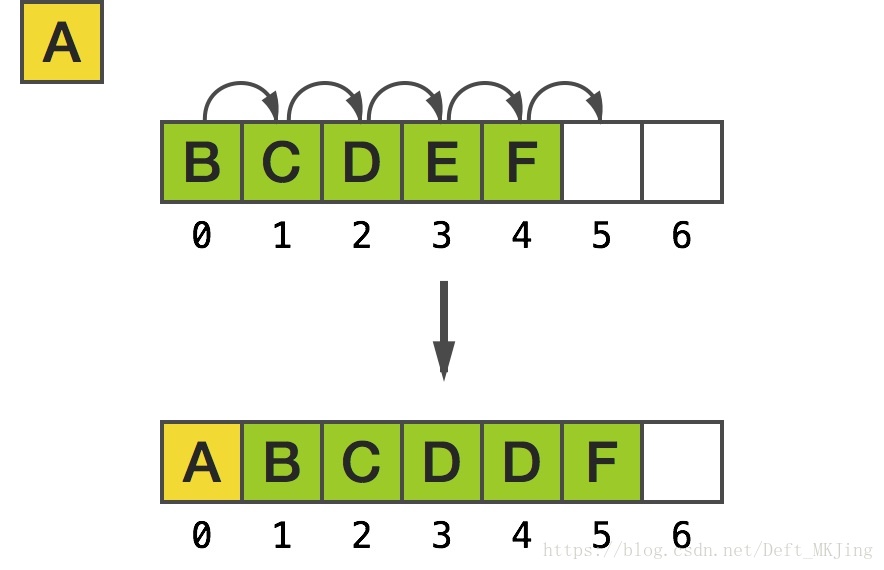
同樣地,假如想要保持相同的記憶體指標作為首個元素的地址,移除第一個元素需要進行相同的動作:
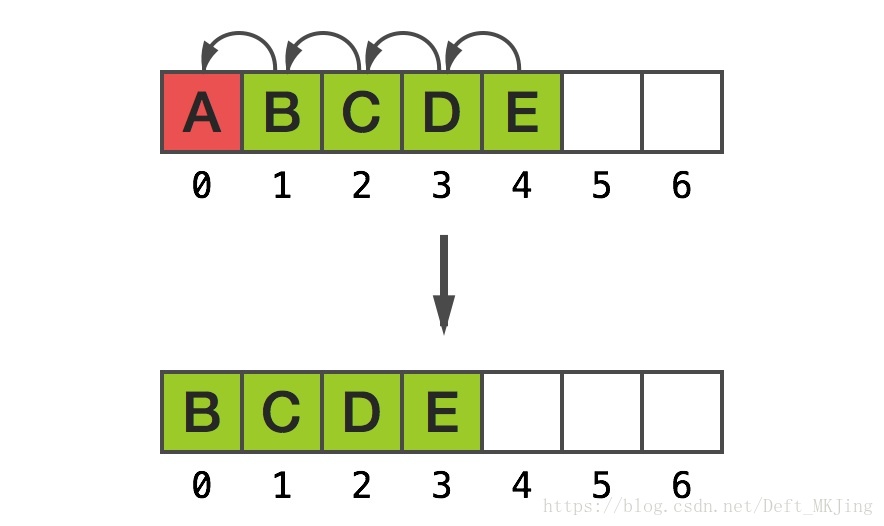
當陣列非常大時,這樣很快會成為問題。顯而易見,直接指標存取在陣列的世界裡必定不是最高階的抽象。C 風格的陣列通常很有用,但 Obj-C 程式設計師每天的主要工作使得它們需要 NSMutableArray 這樣一個可變的、可索引的容器。
上面文章中介紹瞭如何反彙編出來原始碼,下面通過引數來詳細介紹NSMutableArray
ivars 的意思
我們來概括下每個 ivar 的意思:
- _used 是計數的意思
- _list 是緩衝區指標
- _size 是緩衝區的大小
- _offset 是在緩衝區裡的陣列的第一個元素索引
記憶體佈局
最關鍵的部分是決定 realOffset 應該等於 fetchOffset(減去 0)還是 fetchOffset 減 _size。看著純程式碼不一定能畫出完美的圖畫,我們設想一下兩個關於如何獲取物件的例子。
_size > fetchOffset
這個例子中,偏移量相對較小:

為了獲取 0 處的物件,我們計算出 fetchOffset 等於 3 + 0。因為 _size 大於 fetchOffset,realOffset 也等於 3。程式碼返回 _list[3] 的值。而獲取 4 處的物件時,fetchOffset 等於 3 + 4,程式碼返回 _list[7]。
_size <= fetchOffset
當偏移量比較大時會怎樣?

獲取 0 處的物件,使得 fetchOffset 等於 7 + 0,呼叫方法後如期望的返回 _list[7]。然而,獲取 4 處的物件時,fetchOffset 等於 7 + 4 = 11,要大於 _size。獲得的 realOffset 要從 fetchOffset 減去 _size,即 11 - 10 = 1,方法返回 list[1]。
我們基本上是在做取模運算,當穿過快取區邊界時會轉回緩衝區的另一端。
資料結構
正如你會猜測的,__NSArrayM 用了環形緩衝區 (circular buffer)。這個資料結構相當簡單,只是比常規陣列或緩衝區複雜點。環形緩衝區的內容能在到達任意一端時繞向另一端。
環形緩衝區有一些非常酷的屬性。尤其是,除非緩衝區滿了,否則在任意一端插入或刪除均不會要求移動任何記憶體。我們來分析這個類如何充分利用環形緩衝區來使得自身比 C 陣列強大得多。在任意一端插入或者刪除,只是修改offset引數,不需要移動記憶體,我們訪問的時候只是不和普通的陣列一樣index多少就是多少,這裡會計算加上offset之後處理的值取資料,而不是插入頭和尾巴的時候,環形結構會根據最少移動記憶體指標的方式插入,例如要在A和B之間插入,按照C的陣列,我們需要把B到E的元素移動記憶體,但是環形緩衝區的設計,我們只要把A的值向前移動一個單位記憶體,即可,同時修改offset偏移量,就能保證最小的移動單元來完成中間插入
在兩端插入或刪除會相當地快
我麼來思考一下一個非常簡單的例子:
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i < 5; i++) {
[array addObject:@(i)];
}
[array removeObjectAtIndex:0];
[array removeObjectAtIndex:0];
NSLog(@"%@", [array explored_description]);輸出顯示移除位於 0 處的物件兩次後,只是簡單地清除了指標並由此而移動了 _offset ivar:
Size: 6
Count: 3
Offset: 2
Storage: 0x178245ca0
[0] 0x0
[1] 0x0
[2] 0xb000000000000022
[3] 0xb000000000000032
[4] 0xb000000000000042
[5] 0x0
頭部插入
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i < 4; i++) {
[array addObject:@(i)];
}
[array insertObject:@(15) atIndex:0];在 0 處插入物件用了環形緩衝區魔法來將新插入的物件放置在快取區的末端:
Size: 6
Count: 5
Offset: 5
Storage: 0x17004a560
[0] 0xb000000000000002
[1] 0xb000000000000012
[2] 0xb000000000000022
[3] 0xb000000000000032
[4] 0x0
[5] 0xb0000000000000f2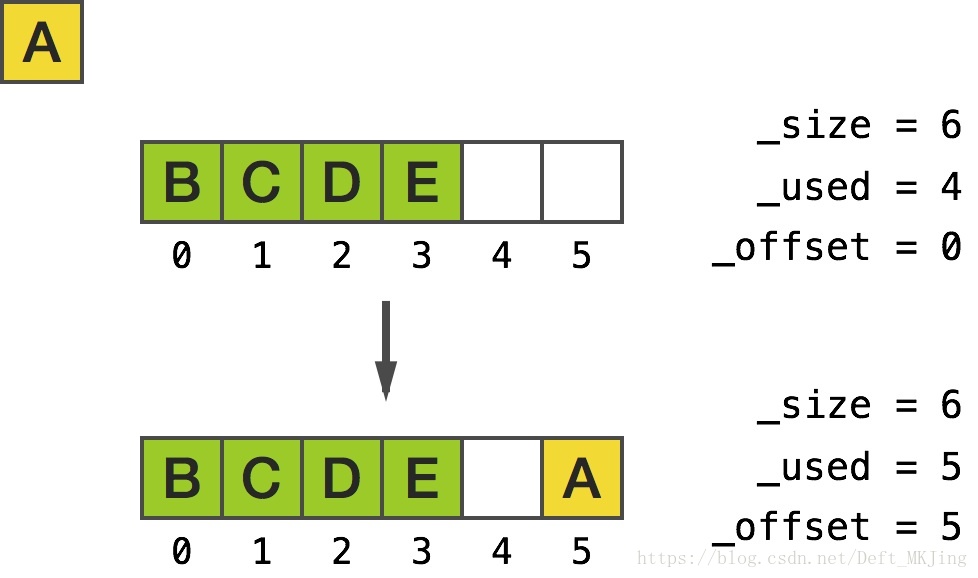
可以看到插入頭尾只是修改offset指標而已,如果插入資料到達閥值,一樣需要擴容。
最糟糕的就是中間插入和刪除中間
NSMutableArray *array = [NSMutableArray array];
for (int i = 0; i < 6; i++) {
[array addObject:@(i)];
}
[array removeObjectAtIndex:3];從輸出中我們看到頂部的元素往下移動,底部為低索引(注意 [5] 處的遊離指標):
[0] 0xb000000000000002
[1] 0xb000000000000012
[2] 0xb000000000000022
[3] 0xb000000000000042
[4] 0xb000000000000052
[5] 0xb000000000000052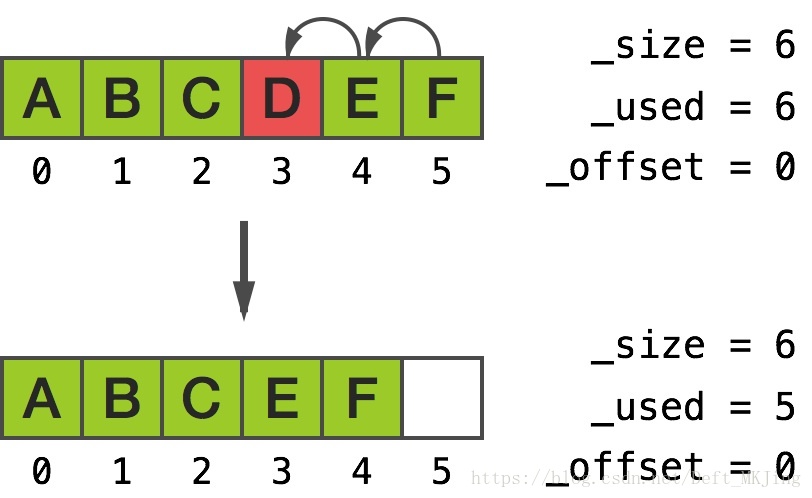
然而,當我們呼叫 [array removeObjectAtIndex:2] 時,底部的元素往上移動,頂部為高索引:
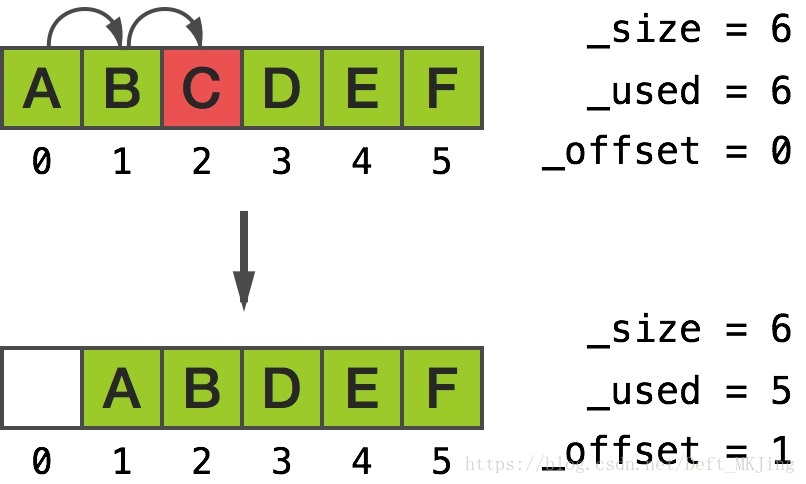
往中部插入物件有非常相似的結果。合理的解釋就是,__NSArrayM 試著去最小化記憶體的移動,因此會移動最少的一邊元素。
總結
NSMutableArray 是一個高階抽象陣列,解決了 C 風格陣列對應的缺點。(C陣列插入的時候都會移動記憶體,不是O(1),用到了環形緩衝區資料結構來處理記憶體移動的損耗)
但是可變陣列任意一端插入或刪除能有固定時間的效能。而且在中間插入和刪除的時候都會試著去移動最小化記憶體。
環形緩衝區的資料結構如果是連續陣列結構,在擴容的時候難免會移動大量記憶體,因此用連結串列實現環形緩衝會更好
維基百科就是這麼介紹的
附:
- setValue和setObject的區別
- (void)setObject:(ObjectType)anObject forKey:(KeyType <NSCopying>)aKey;
- (void)setValue:(nullable ObjectType)value forKey:(NSString *)key;setObject: ForKey:是NSMutableDictionary特有的;setValue: ForKey:是KVC的主要方法。
(1) setValue: ForKey:的value是可以為nil的(但是當value為nil的時候,會自動呼叫removeObject:forKey方法); setObject: ForKey:的value則不可以為nil。 (2) setValue: ForKey:的key必須是不為nil的字串型別; setObject: ForKey:的key可以是不為nil的所有繼承NSCopying的型別。