
【機器學習】用QR分解求最小二乘法的最優閉式解
【機器學習】用QR分解求最小二乘法的最優閉式解
寫在前面
今天刷知乎,看到張皓在面試官如何判斷面試者的機器學習水平?的回答裡面講到了關於用矩陣的QR分解求解最小二乘法閉式解的問題,碰巧前幾天《矩陣分析》課堂上剛講到QR分解,覺得挺有意思,值得深究,遂產生寫本篇博文的動機。另外本人知識水平理解能力有限,如有錯漏請各位大俠批評指正。
QR分解
先來看看維基百科上怎麼說:
QR分解法是三種將矩陣分解的方式之一。這種方式,把矩陣分解成一個半正交矩陣與一個上三角矩陣的積。QR分解經常用來解線性最小二乘法問題。QR分解也是特定特徵值演算法即QR演算法的基礎。
定義
實數矩陣的QR分解是把矩陣A分解為:
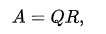
這裡的Q是正交矩陣(意味著QTQ = E)而R是上三角矩陣(即矩陣R的對角線下面的元素全為0)。為了便於理解,這裡引用一下daniel-D的圖:
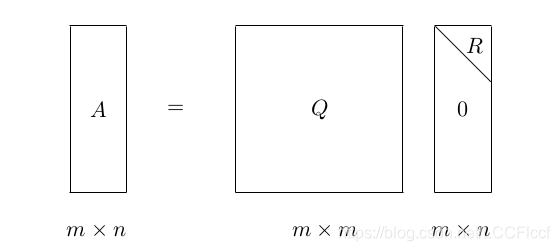
這個將A分解成這樣的矩陣Q和R的過程就是QR分解,QR分解可用於求解矩陣A的特徵值、A的逆等問題。具體參考血影雪夢大神的博文。
QR的求解
QR 分解的實際計算有很多方法,例如 Givens 旋轉、Householder 變換,以及 Gram-Schmidt 正交化等等。每一種方法都有其優點和不足。對於QR分解的求解這裡不再展開論述,在python中可以用numpy庫實現:
import numpy as np
Q, R = np.linalg.qr(A)
線性迴歸模型
給定資料集
其中
.即樣本由
個屬性描述。“線性迴歸”(linear regression)試圖學得一個線性模型以儘可能準確地預測實值輸出標記。
線性迴歸試圖學得的模型為:
這稱為“多元線性迴歸”(multivariate linear regression)
可以利用最小二乘法來對引數
進行估計。我們知道均方誤差是迴歸任務中最常用的效能度量,即通常所說的損失函式,這裡的損失函式可以表示為:
因此我們可試圖讓均方誤差最小化,求出最優閉式解,即
在處理大型資料集時,我們一般都把引數和訓練資料進行向量化(vectorization),即吸入矩陣中,再對矩陣進行計算,資料的向量化能給計算速度帶來非常大的提升。具體做法是:對於訓練引數,把
,即在列向量
的第一個元素前插入偏置項
,此時的引數
變成
的列向量;即
對於訓練資料集
,我們把
吸入一個
大小的矩陣
中,矩陣
的第一列用全為1的元素填充,即