
spark體系結構以及詳細安裝步驟
阿新 • • 發佈:2018-12-10
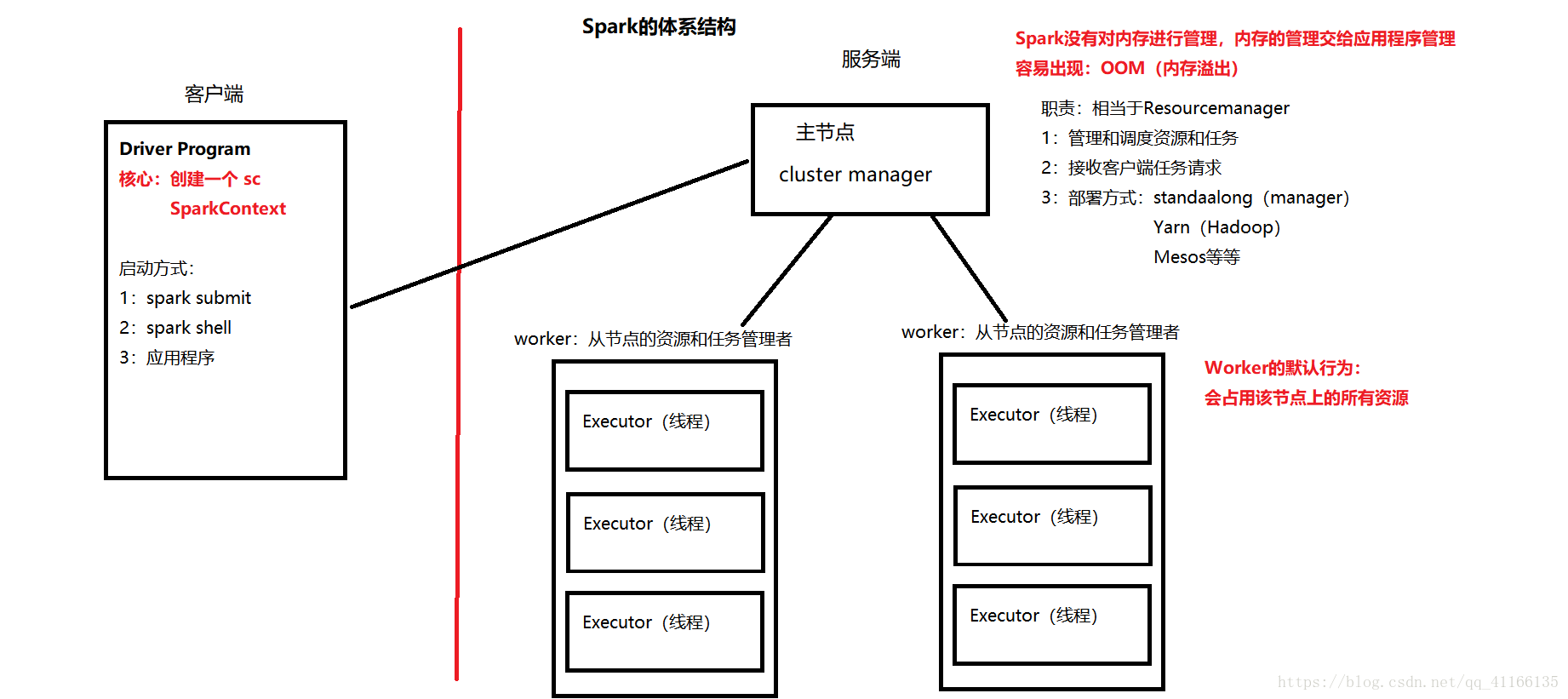
1.Spark體系分為服務端和客戶端
(1)服務端分為主節點和從節點 1>主節點是master,相當於Resourcemanager,職責是管理和排程資源和任務、接受客戶端任務請求,部署在其他服務上(standaalong、Yarn。。。) 2>從節點是worker,任務是從節點的資源和任務管理者 (2)需要注意的兩點是 1>Spark沒有對記憶體進行管理,記憶體的管理交給應用程式管理。容易出現OOM(記憶體溢位) 2>Worker的預設行為:會佔用該節點上的所有資源 (3)客戶端 核心:建立一個sc SparkContext 啟動方式:1:spark submit 2: soark shell 3:應用程式
2.詳細安裝步驟
1.先看一下自己的hadoop版本是多少,然後官網上找到相對應的版本,如果是2.7或者大於2.7呢就選擇我圖上的那個選項

2.解壓 tar -zxvf...... -C "自己的安裝目錄"
3.配置檔案:cd /usr/local/spark-2.2.1-bin-hadoop2.7/conf/
1) mv spark-env.sh.template spark-env.sh mv slaves.tenplate slaves 2) 偽分散式安裝(主要用於開發測試) vi spark-env.sh export JAVA_HOME = /usr/local/jdk.... export SPARK_MASTER_HOST=hadoop01 export SPARK_MASTER_PORT=7077 vi slaves hadoop01 啟動:進入到sbin下面 ./start-all.sh 3) 全分散式安裝(主要用於生產): Master節點:hadoop01 Worker節點:hadoop02,hadoop03 配置檔案: vi spark-env.sh export JAVA_HOME=...... export SPARK_MASTER_HOST=hadoop01 export SPARK_MASTER_PORT=7077 vi slaves hadoop02 hadoop03 將配置好的spark複製到從節點上 scp -r spark...hadoop2.7/ hadoop02:/usr/local/ scp -r spark...hadoop2.7/ hadoop03:/usr/local/
此時就弄好了 注: http://hadoop01:8080/ 是spark 外部的監控頁面埠 7077 是master的rpc通訊介面