
函式式模型概述
Keras函式式模型介面是使用者定義多輸出模型、非迴圈有向模型或具有共享層的模型等複雜模型的途徑。一句話,只要你的模型不是類似VGG一樣一條路走到黑的模型,或者你的模型需要多於一個的輸出,那麼你總應該選擇函式式模型。函式式模型是最廣泛的一類模型,序貫模型(Sequential)只是它的一種特殊情況。
因為序貫模型是函式式模型的一個特例,所以我們從一個簡單的序貫模型開始,舉例看看函式式模型是如何完成的。
考慮這樣一個模型。我們希望預測Twitter上一條新聞會被轉發和點贊多少次。
模型的主要輸入是新聞本身,也就是一個詞語的序列。但我們還可以擁有額外的輸入,如新聞釋出的日期等。
這個模型的損失函式將由兩部分組成,輔助的損失函式評估僅僅基於新聞本身做出預測的情況,主損失函式評估基於新聞和額外資訊的預測的情況,即使來自主損失函式的梯度發生彌散,來自輔助損失函式的資訊也能夠訓練Embeddding和LSTM層。在模型中早點使用主要的損失函式是對於深度網路的一個良好的正則方法。總而言之,該模型框圖如下:
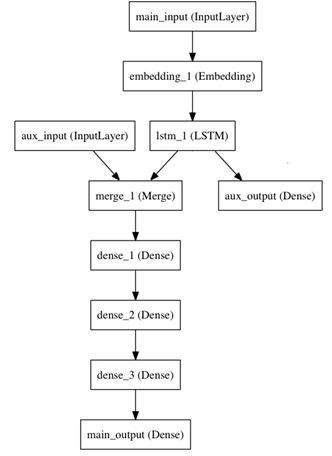
函式式模型搭建這個框圖裡的模型是方便的。
主要的輸入接收新聞本身,即一個整數的序列(每個整數編碼了一個詞)。這些整數位於1到10000之間(即我們的字典有10000個詞)。這個序列有100個單詞。
from keras.layers import Input, Embedding, LSTM, Dense
from keras.models import Model
main_input = Input(shape=(100,), dtype='int32', name='main_input')
x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
lstm_out = LSTM(32)(x)
然後,我們插入一個額外的損失,使得即使在主損失很高的情況下,LSTM和Embedding層也可以平滑的訓練。
auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
再然後,我們將LSTM與額外的輸入資料串聯起來組成輸入,送入模型中:
auxiliary_input = Input(shape=(5,), name='aux_input')
x = keras.layers.concatenate([lstm_out, auxiliary_input])
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
# And finally we add the main logistic regression layer
main_output = Dense(1, activation='sigmoid', name='main_output')(x)
最後,我們定義整個2輸入,2輸出的模型:
model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
模型定義完畢,下一步編譯模型。我們給額外的損失賦0.2的權重。
我們可以通過關鍵字引數loss_weights或loss來為不同的輸出設定不同的損失函式或權值。
這兩個引數均可為Python的列表或字典。這裡我們給loss傳遞單個損失函式,這個損失函式會被應用於所有輸出上。
model.compile(optimizer='rmsprop', loss='binary_crossentropy', loss_weights=[1., 0.2])
編譯完成後,我們通過傳遞訓練資料和目標值訓練該模型:
model.fit([headline_data, additional_data], [labels, labels], epochs=50, batch_size=32)
因為我們輸入和輸出是被命名過的(在定義時傳遞了“name”引數),我們也可以用下面的方式編譯和訓練模型:
model.compile(optimizer='rmsprop', loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
loss_weights={'main_output': 1., 'aux_output': 0.2})
model.fit({'main_input': headline_data, 'aux_input': additional_data},
{'main_output': labels, 'aux_output': labels},
epochs=50, batch_size=32)