
基於內容的推薦、協同過濾
基於內容的推薦
需要分析內容,無需考慮其他使用者的行為,例如基於使用者喜歡的item的屬性/內容進行推薦
通常使用在文字相關產品上進行推薦
使用詞袋模型來衡量不同文字的相似度,每個詞的權重可以使用頻率或者tf-idf表示
相似度計算公式一般使用餘弦相似度
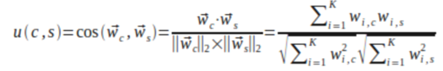
協同過濾(CF)
基於使用者的協同過濾
找到和使用者最近的其他使用者,找到其他使用者看過或者買過但當前使用者沒有看過或者買過的item,根據使用者與其他使用者距離的遠近進行打分,找到得分最高的item進行推薦。
Tip: 基於使用者的協同過濾求相似度時應該先去均值
基於物品的協同過濾
根據使用者對商品或者內容的行為,計算item與item的相似度,找到和當前item最近的進行推薦
相似度/距離度量方法
歐式距離:
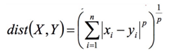
Jaccard相似度:
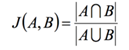
餘弦相似度:
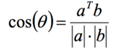
Pearson相似度:
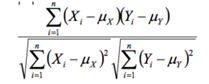
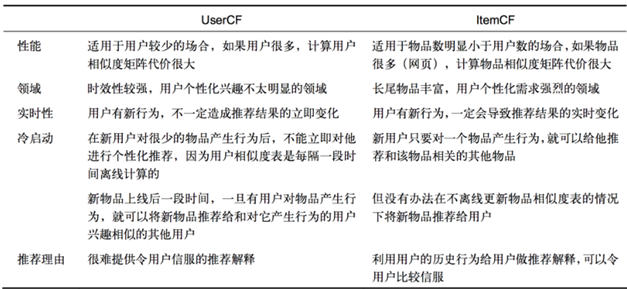
User CF vs Item CF
工業上一般使用Item CF,應為一般情況下使用者太多,遠多於商品的數量,並且Item CF更加穩定,例如隨著時間的推移,物品之間的相似度基本不發生變化,而由於個人興趣的改變,User CF的使用者之間的相似度很可能發生較大的變化。
CF優缺點
協同過濾優點
基於使用者行為,因此對推薦內容無需先驗知識
只需要使用者和商品關聯矩陣即可,結構簡單
在使用者行為豐富的情況下,效果好
協同過濾缺點
需要大量的顯性/隱性使用者行為
需要通過完全相同的商品關聯,相似的不行
假定使用者的興趣完全取決於之前的行為,而和當前上下文環境無關
在資料稀疏的情況下受影響。可以考慮二度關聯。(如U1與U2無關聯,而U1、U2與U3都關聯)
冷啟動問題
對於新使用者,所有推薦系統對於新使用者都有這個問題,一般的解決辦法:
1) 推薦非常熱門的商品,收集一些資訊
2) 在使用者註冊的時候收集一些資訊
3)在使用者註冊完之後,用一些互動遊戲等確定喜歡與不喜歡
4)對於新商品,根據本身的屬性,求與原來商品的相似度。Item-based協同過濾可以推薦出去。