
推薦演算法 協同過濾sklearn實現
阿新 • • 發佈:2018-12-10
資料集使用MovieLens資料集
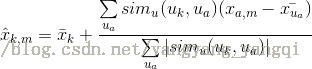
import pandas as pd import numpy as np header = ['user_id', 'item_id', 'rating', 'timestamp'] dataset = pd.read_csv('../data/u.data',sep='\t',names=header) #計算唯一使用者和電影的數量 # unique對以為陣列去重 shape[0] shape為矩陣的長度 users = dataset.user_id.unique().shape[0] items = dataset.item_id.unique().shape[0] from sklearn.model_selection import train_test_split train_data,test_data = train_test_split(dataset,test_size=0.25) ''' 建立user-item矩陣 itertuples pandas dataframe 建立索引的方式 結果為: Pandas(Index=77054, user_id=650, item_id=528, rating=3, timestamp=891370998) ''' train_data_matrix = np.zeros((users,items)) for line in train_data.itertuples(): train_data_matrix[line[1] - 1, line[2] - 1] = line[3] test_data_matrix = np.zeros((users,items)) for line in test_data.itertuples(): test_data_matrix[line[1] - 1, line[2] - 1] = line[3] #計算相似度 from sklearn.metrics.pairwise import pairwise_distances #相似度相當於權重w user_similarity = pairwise_distances(train_data_matrix,metric='cosine') #train_data_matrix.T 矩陣轉置 items_similarity = pairwise_distances(train_data_matrix.T,metric='cosine') ''' 基於使用者相似矩陣 -> 基於使用者的推薦 mean函式求取均值 axis=1 對各行求取均值,返回一個m*1的矩陣 np.newaxis 給矩陣增加一個列 一維矩陣變為多維矩陣 mean_user_rating(n*1) train_data_matrix所有行都減去mean_user_rating對應行的數 此為規範化評分,使其在統一的範圍內 numpy a.dot(b) -> 兩個矩陣的點積 np.abs(a) ->計算矩陣a各元素的絕對值 np.sum() -> 無引數 矩陣全部元素相加 -> axis=0 按列相加 -> axis=1 按行相加 b /a 矩陣對應為相除 ''' mean_user_rating = train_data_matrix.mean(axis = 1) #計算每行的平均數 rating_diff = train_data_matrix - mean_user_rating[:,np.newaxis] #評分規範化 print(user_similarity.dot(rating_diff)) pred = mean_user_rating[:, np.newaxis] \ + user_similarity.dot(rating_diff) / np.array([np.abs(user_similarity).sum(axis=1)]).T #權重w*平均化的評分 ''' 基於物品相似矩陣 ---基於物品的推薦 '''