
kylin入門到實戰
1.概述
kylin是一款開源的分散式資料分析工具,基於hadoop之上的sql查詢介面,能支援超大規模的資料分析。響應時間在亞秒級別,其核心是預計算,計算結果存放在hbase中。

2.特性
-
可擴充套件超快OLAP引擎:
Kylin是為減少在Hadoop上百億規模資料查詢延遲而設計 -
Hadoop ANSI SQL 介面:
Kylin為Hadoop提供標準SQL支援大部分查詢功能 -
互動式查詢能力:
通過Kylin,使用者可以與Hadoop資料進行亞秒級互動,在同樣的資料集上提供比Hive更好的效能 -
多維立方體(MOLAP Cube):
使用者能夠在Kylin裡為百億以上資料集定義資料模型並構建立方體 -
與BI工具無縫整合:
Kylin提供與BI工具,如Tableau,的整合能力,即將提供對其他工具的整合 -
其他特性:
Job管理與監控
壓縮與編碼
增量更新
利用HBase Coprocessor
基於HyperLogLog的Dinstinc Count近似演算法
友好的web介面以管理,監控和使用立方體
專案及立方體級別的訪問控制安全
支援LDAP
3.相關概念
3.1 Fact Table(事實表):
事實表是指包含了大量不冗餘資料的表,其列一般有兩種,分別為包含事實資料的列,包含維表foreign key的列。
3.2 Lookup table
3.3 Dimenssion Table(維表):
由fact table和lookup table 抽象出來的表,包含了多個相關的列,提供對資料不同維度的觀察,其中每列的值的數目稱為cardinatily。
3.4 model:用來定義使用者需要使用的hive表名,及所包含的維度列、度量列、partition列和date格式。
3.5 cube:用來定義某具體查詢時會涉及到的維度列及相互之間的關係(如層級關係)、度量列的具體型別(如max,min,sum)等,一個model下可存在多個cube。
1.什麼是cube?
cube是所有dimession的組合,每一種dimession的組合稱之為cuboid。某一有n個dimession的cube會有2n個cuboid,如圖:
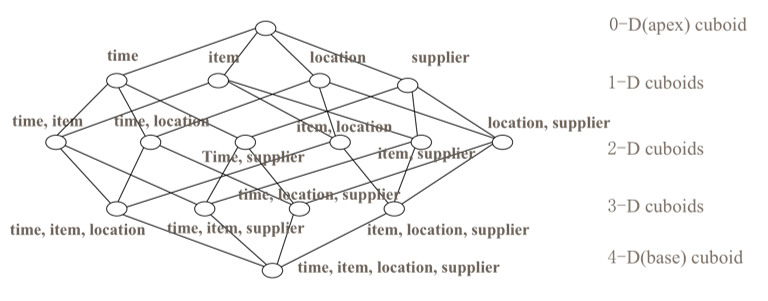
對應一張hive表,有time,item,location,supplier這四個維度,則0-D cuboid時對應的查詢語句為 select sum(money) from table;1-D cuboid對應的查詢語句有四個,分別為select sum(money) from table group by time,以及select sum(money) from table group by item,以及select sum(money) from table group by location。對應的在2-D時group by 後面的維度會是time,item,location,supplier兩兩組合。如果不採取優化措施,理論上kylin在預計算過程中會對上述每一種組合進行預計算,隨著維度的增加,計算量將會呈幾何倍數的增長。為了解決這種問題,kylin對dimession做了分類,見下文。
2.dimession
為了減少cuboid的數量,kylin對dimession做了如下分類
normal:最為普通常見的dimession型別,與其他型別的dimession組成cuboid。
mandatory:每次查詢均會使用到的dimession,在下圖中A為Mandatory dimension,則與B、C總共構成了4個cuboid,相較於normal dimension的cuboid(23=8)減少了一半。
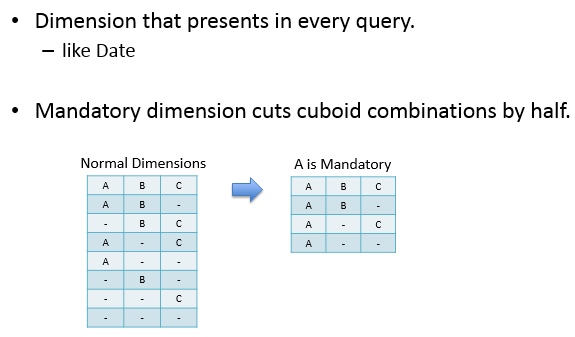
在實際生產應用中,比如對於日報表的分析,可能日期就是一個mandatory dimession。
hierarchy:帶層級的dimession,如:年->月->日,要求子級的父級必須存在。如下的例子中cuboid由2n降為了n+1。
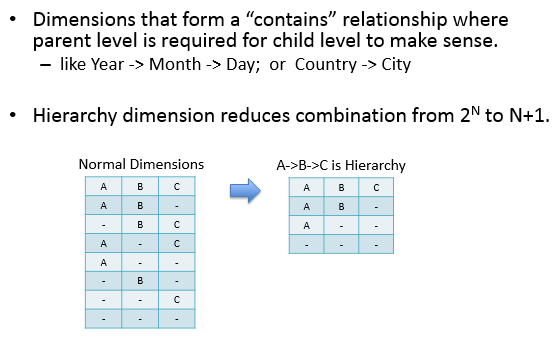
然而,Kylin的Hierarchy dimensions並沒有做集合包含約束,比如:kylin_sales_cube定義Hierarchy dimension為META_CATEG_NAME->CATEG_LVL2_NAME->CATEG_LVL3_NAME,但是同一個CATEG_LVL2_NAME可以對應不同META_CATEG_NAME。因此,hierarchy 顯得非常雞肋,以至於在Kylin後臺處理時被廢棄了。
derived:指該dimession與維表的primary key是一一對應的關係,可以有效減少cuboid的數量,derived dimession只能由Lookup Table生成。
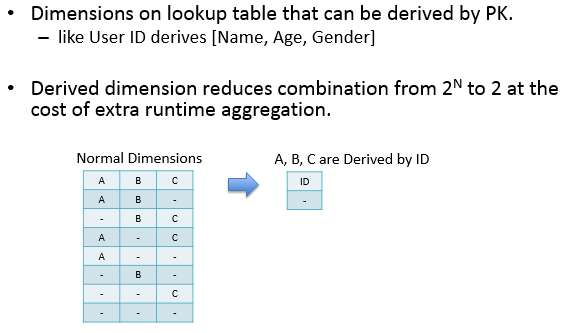
3.measure
measure為事實表的度量值,kylin提供了下面幾個函式:
sum,count,max,min,avarage,count_distinct
其中count_distinct有兩種實現方式:
(1)近似Count Distinct。Apache Kylin使用HyperLogLog演算法實現了近似Count Distinct,提供了錯誤率從9.75%到1.22%幾種精度供選擇;
演算法計算後的Count Distinct指標,理論上,結果最大隻有64KB,最低的錯誤率是1.22%;這種實現方式用在需要快速計算、節省儲存空間,並且能接受錯誤率的Count Distinct指標計算。
(2)準Count Distinct。從1.5.3版本開始,Kylin中實現了基於bitmap的精確Count Distinct計算方式。當資料型別為tiny int(byte)、small int(short)以及int,
會直接將資料值對映到bitmap中;當資料型別為long,string或者其他,則需要將資料值以字串形式編碼成dict(字典),再將字典ID對映到bitmap;
指標計算後的結果,並不是計數後的值,而是包含了序列化值的bitmap.這樣,才能確保在任意維度上的Count Distinct結果是正確的。
這種實現方式提供了精確的無錯誤的Count Distinct結果,但是需要更多的儲存資源,如果資料中的不重複值超過百萬,結果所佔的儲存應該會達到幾百MB。
前面兩篇文章已經介紹了kylin的相關概念以及cube的一些原理,這篇文章將從一個實際的案例入手,介紹如何在kylin平臺上建立一個多維分析專案。
1.建立project
進入kylin操作介面,如果沒有project可以建立,kylin裡面可以建立多個project,有效的把各種業務資料分析隔離開來。如圖:
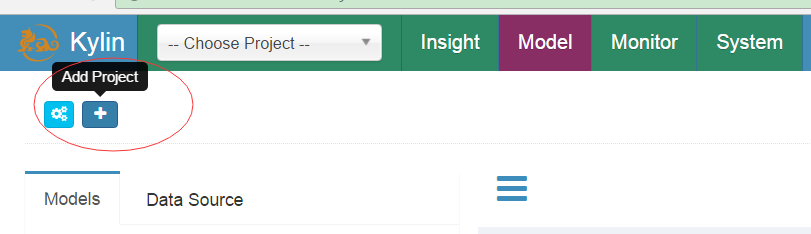
如下,填寫project name,description可以不填
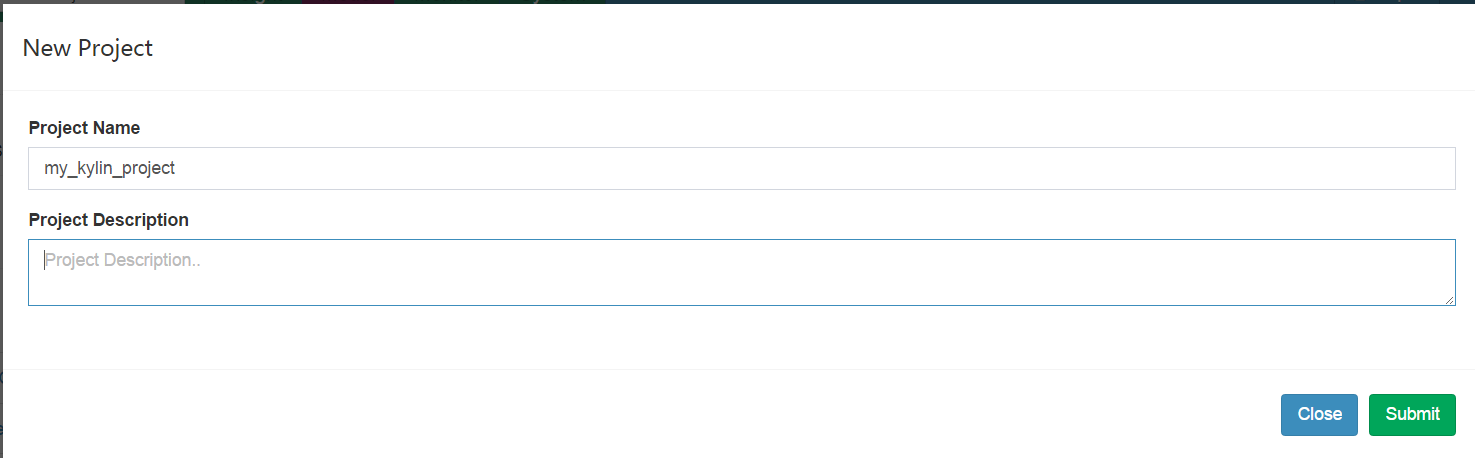
然後submit 提交,project建立成功。
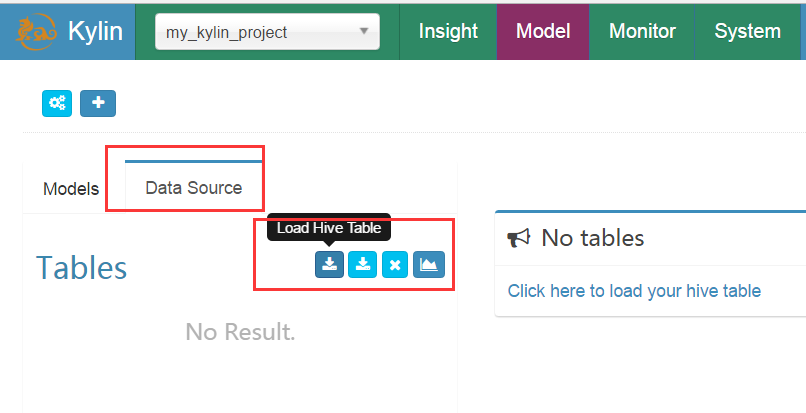
2.新增資料來源
點選DataSource選項卡->Load Hive Table
填寫hive表名,前面加上庫名
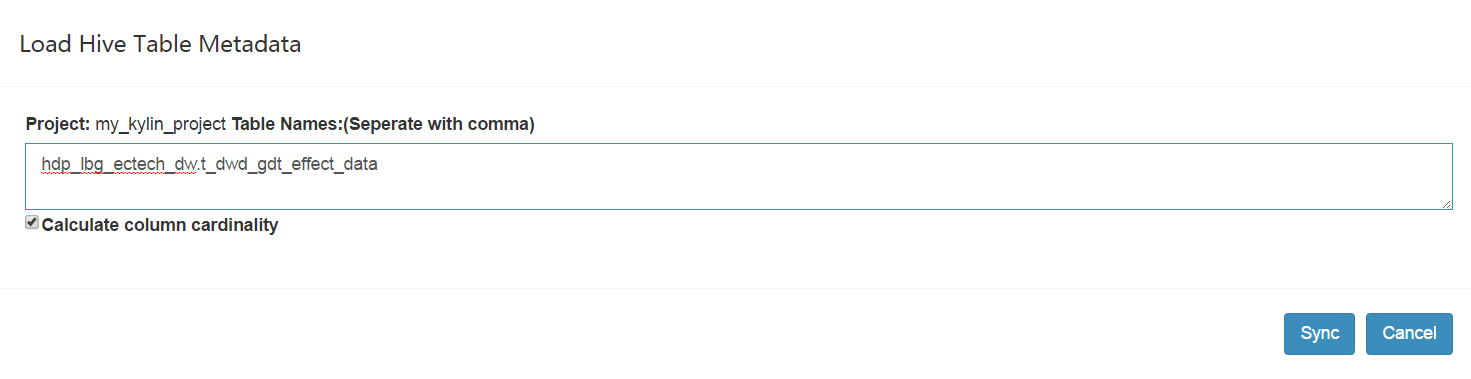
然後點選sync,匯入資料來源成功,可以看到如下資訊:
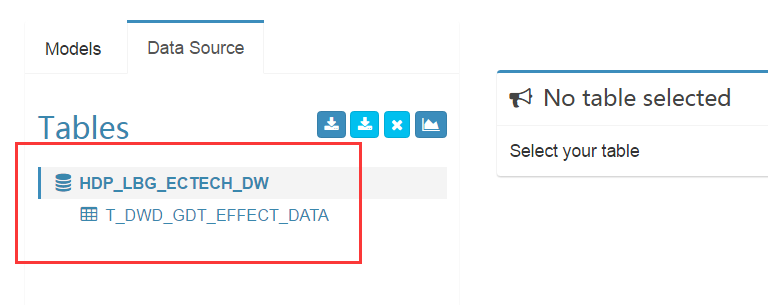
3.建立model
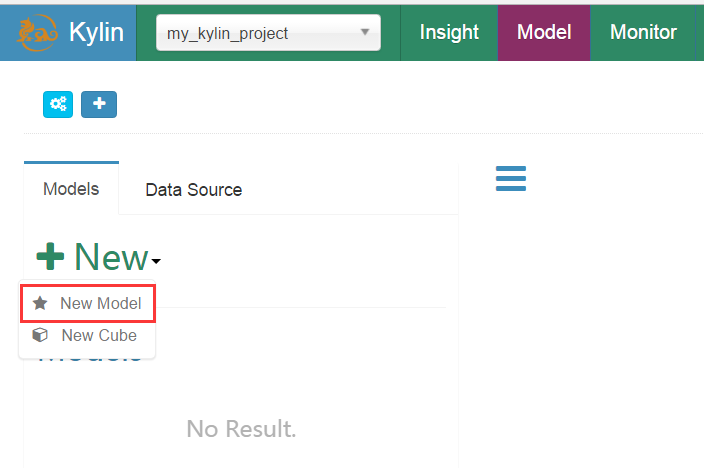
新增model name然後 next
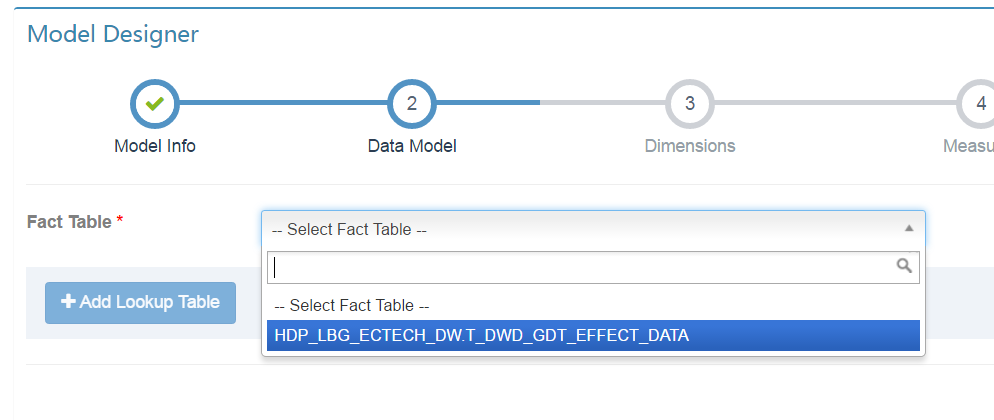
選擇剛才新增到資料來源中的事實表,如果有Lookup Table也可新增,然後next
選擇需要的維度
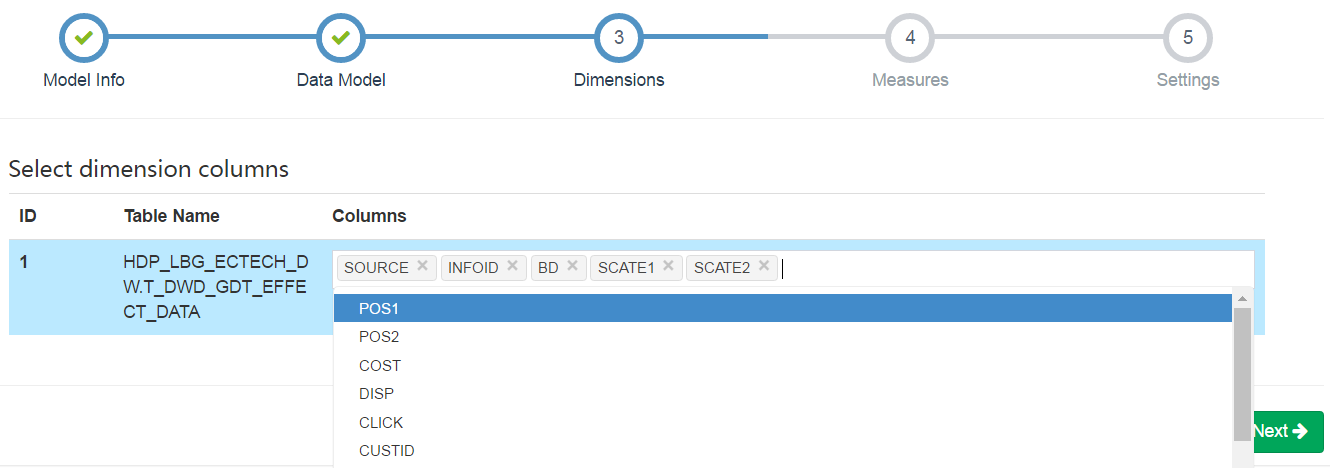
選擇需要的指標
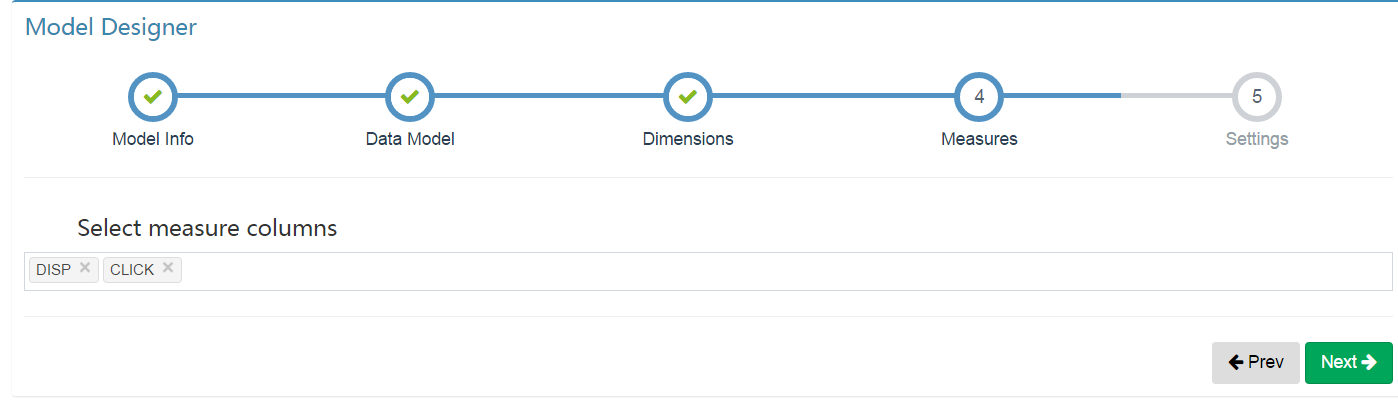
相關設定
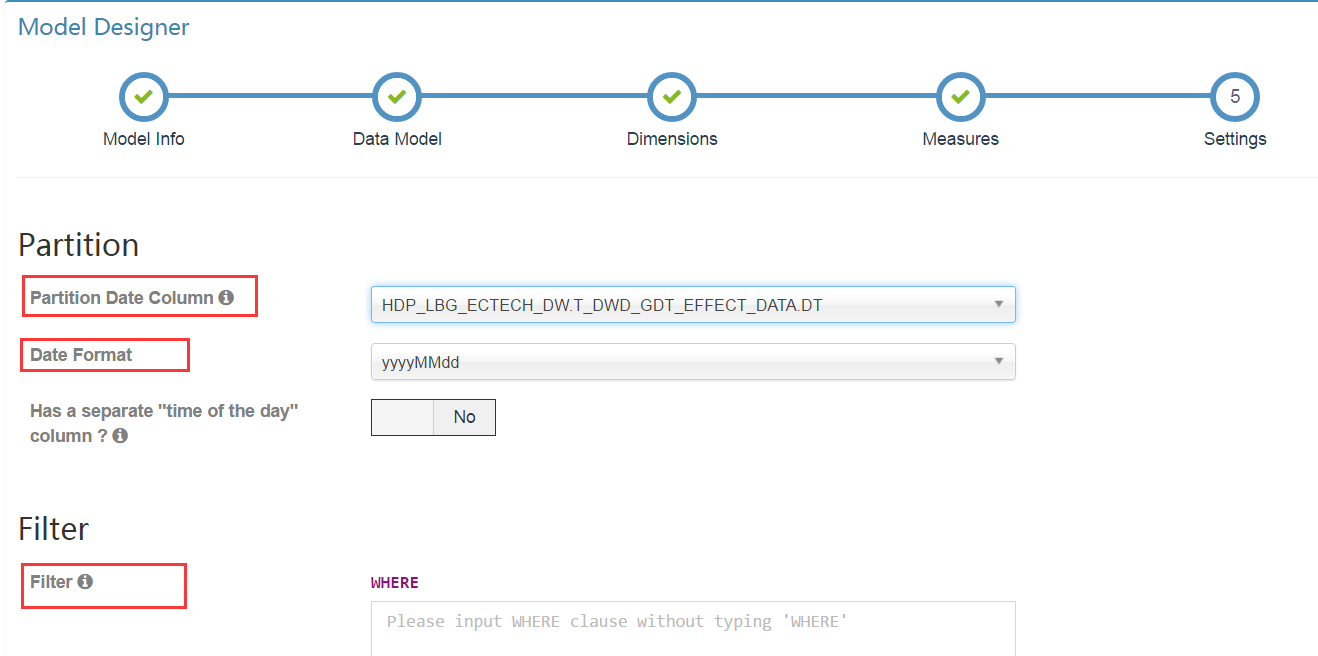
partition date colume表示分割槽欄位,選擇hive表中按時間分割槽的欄位。然後從date format中選擇不同的時間格式。最下面的filter可以新增where條件對資料來源中的資料做過濾。
至此,model建立完成。
4.建立cube
下面進入關鍵環節建立cube。
類似於建立model,建立cube。選擇之前建立好的model,並填入cube name。notification email list是選填項,表示報警接收人郵件地址,多個郵件地址以逗號隔開。
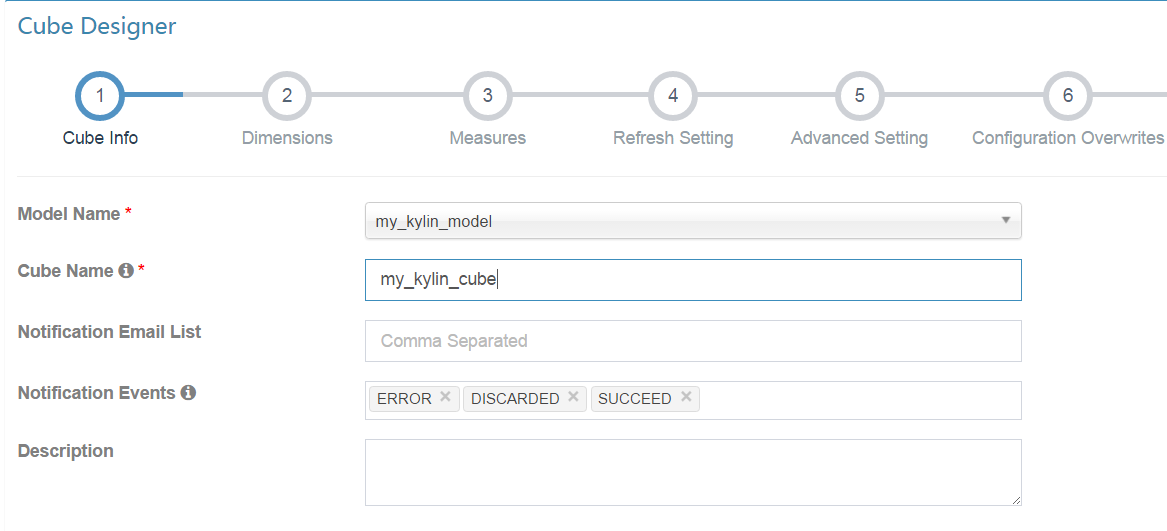
然後next。選擇dimession,有兩種方式:一是手動新增dimession,二是使用自動生成,我們這裡使用自動生成,然後勾選需要的欄位。
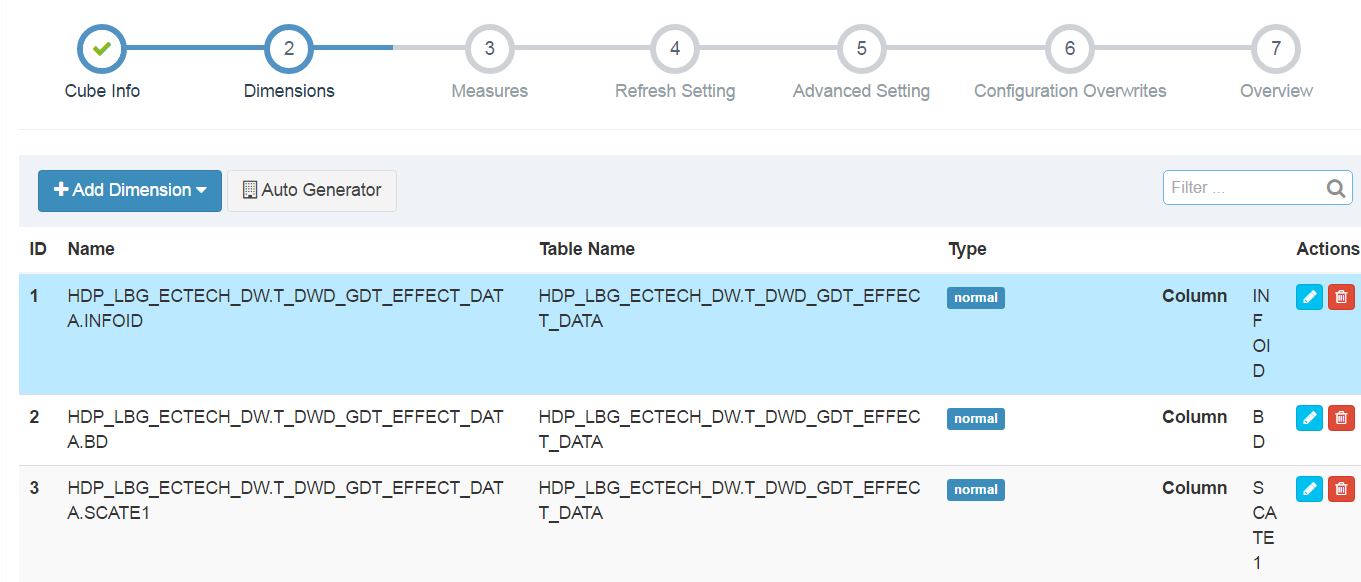
然後next,選擇指標
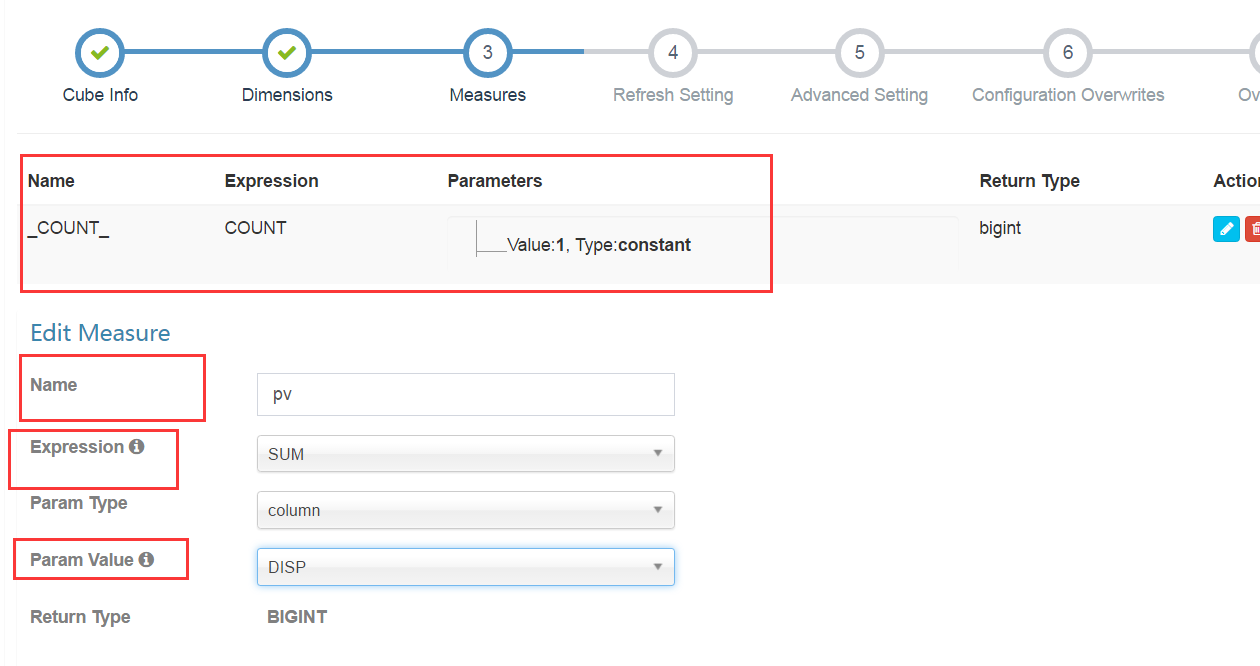
count(1)是系統預設自帶的,不要刪除。
點選+號新增需要的指標,需要填入名稱,選擇表示式。這裡選擇的是sum。我們要針對disp加和求pv,在param value裡面選擇disp列。
需要注意的是kylin中hive表中每一列欄位的型別要求比較嚴格。dimession欄位需要為String,用來加和的指標欄位須為bigint或者decimal
添加了所有需要的指標後,點選next
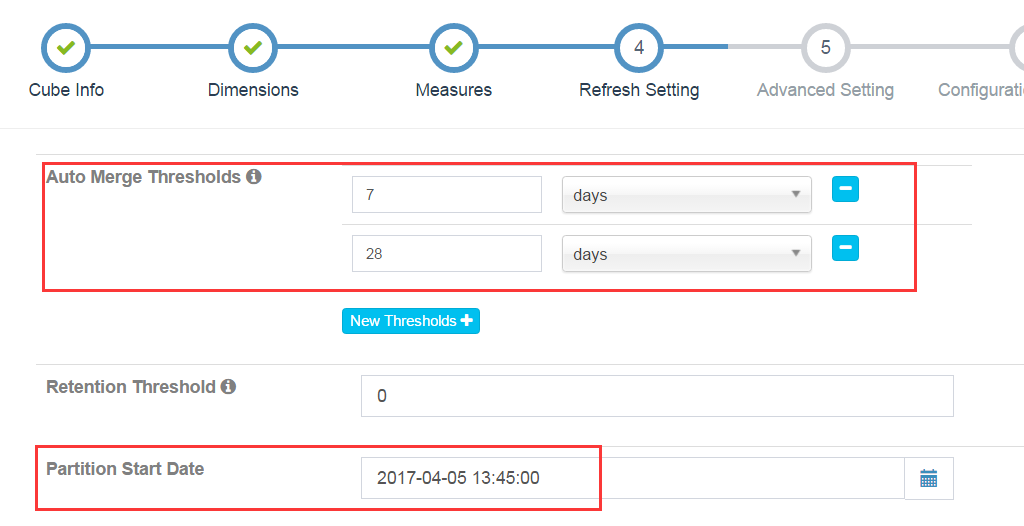
設定merge時間。Kylin每次build會生成一張hbase表,merge操作會把多天資料合併成一張新的hbase表。可加快查詢。
設定partition Start Date,即資料來源開始時間,預設為1970-01-01.點選Next.
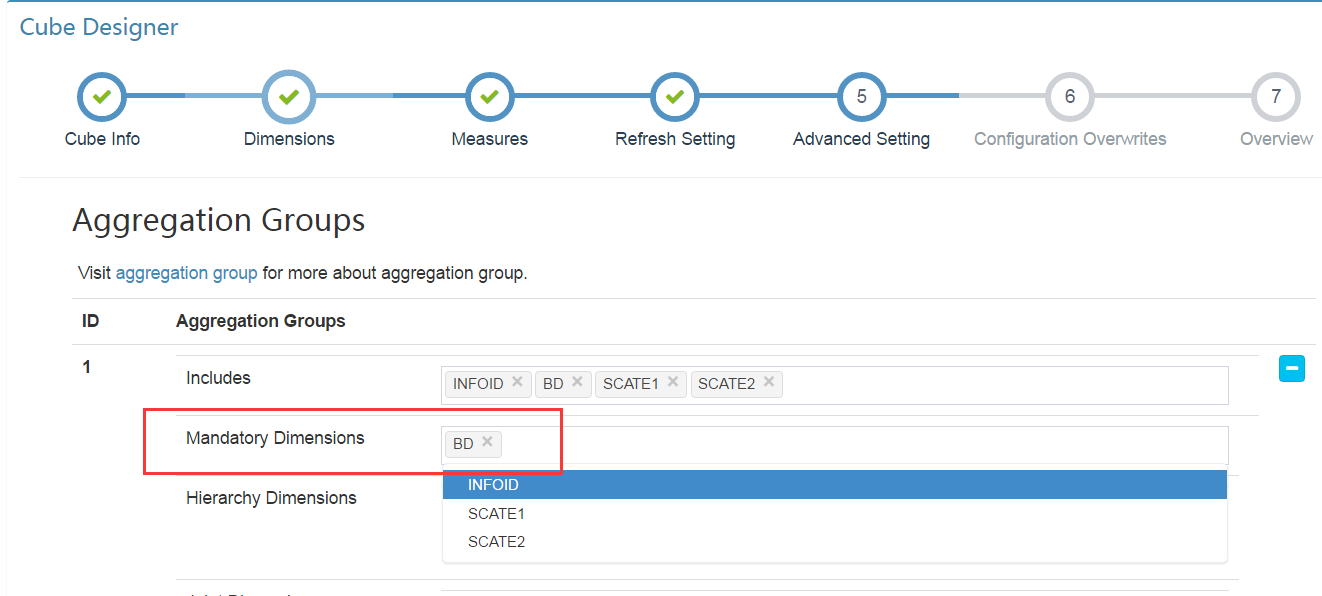
Mandatory Dimensions:每次查詢均會使用的維度可新增在此。比如某些情況下的partition column.
Hierarchy Dimensions:維度列中彼此間存在層級關係的列,比如“國家-省份-市-縣”
Joint Dimensions:每次查詢會同時使用或不使用的維度組合。
Aggregation Group:在不同的查詢中,兩組維度組合之間不會產生交叉,可選擇此選項,比如所有的cube維度有 [ a,b,c,d,e,f ] 6個,每次查詢中只會同時查與 [ a,b,c ] 相關的資訊(比如[a],[a,c]等)而不會查詢 [ d,e,f ],或者相反,則可選擇此選項。
以上選擇均可減少build過程中的資料量,是加快build與query速度的優化點之一。
接下來基本上就是next,然後儲存,如果沒有報錯,則證明cube建立成功,如下圖
5.cube其他操作
最常用的就是build操作,它會根據我們建立的cube進行資料的預計算。
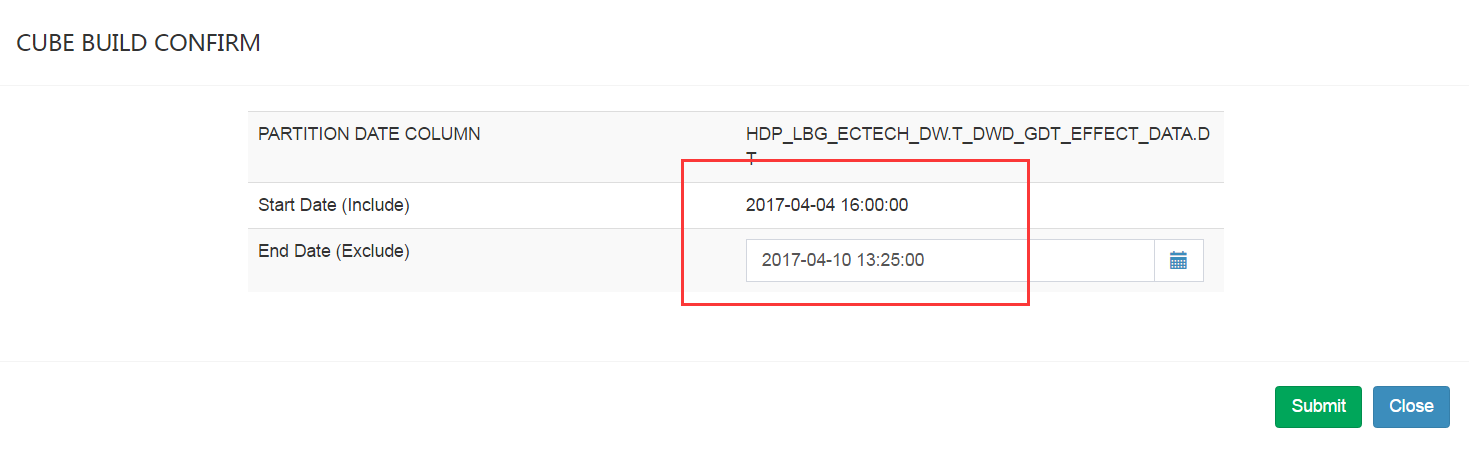
選擇構建的終止時間,然後提交,之後可以在monitor中看到cube構建的狀態。
其他操作說明:
Drop:丟棄現有cube,條件:無Pending, Running, Error 狀態的job.
Edit:編輯現有cube,條件:cube需處於disable狀態。
Refresh:重建某已有時間段資料,針對於已build時間段的源資料發生了改變的情況。
Merge:手動觸發merge操作。
Enable:使擁有至少一個有效segment的cube從disable變為enable狀態。
Purge:清空所有該cube的資料。
Clone:克隆一個新的cube,可設定新的名字,其他相關配置與原cube相同。
Disable:使一個處於ready狀態的cube變為Disable狀態,查詢不會從disable的cube中獲取資料。
6.查詢操作
資料預計算完成後就可以進行查詢了,查詢過程中也可以驗證cube建立的是否有問題。有兩種查詢方式:一種是通過kylin的web介面,一種是使用kylin提供的rest api。下面分別介紹。
(1)web查詢。進入insight,輸入sql語句,等待查詢結果,和一般的資料庫客戶端類似。
(2)rest api。舉例如下:
假如需要查詢的sql語句為:“select sum(disp) as pv from t_table group by td,bd”
kylin賬戶的賬號密碼為:“kylinid:passwd”,對其進行base64加密。secret=echo -n “kylin_id:password” | base64
使用的project為:my_kylin_project
介面地址為:http://localhost:7070/kylin/api/query
則請求為:
bash 2行
curl -X POST -H "Authorization:Basic ${secret}" -H "Content-Type:application/json" -d '{ "sql" : "select sum(disp) as pv from t_table group by td,bd", "project" : "my_kylin_project" }' http://localhost:7070/kylin/api/query