
kylin入門到實戰:cube詳述
阿新 • • 發佈:2018-12-31
1.什麼是cube?
cube是所有dimession的組合,每一種dimession的組合稱之為cuboid。某一有n個dimession的cube會有2^n^個cuboid,如圖: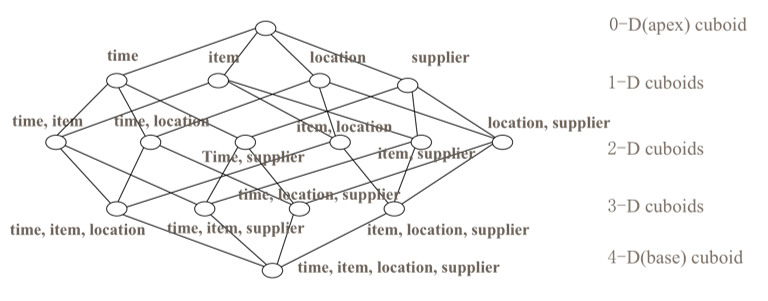
對應一張hive表,有time,item,location,supplier這四個維度,則0-D cuboid時對應的查詢語句為 select sum(money) from table;1-D cuboid對應的查詢語句有四個,分別為select sum(money) from table group by time,以及select sum(money) from table group by item,以及select sum(money) from table group by location。對應的在2-D時group
by 後面的維度會是time,item,location,supplier兩兩組合。如果不採取優化措施,理論上kylin在預計算過程中會對上述每一種組合進行預計算,隨著維度的增加,計算量將會呈幾何倍數的增長。為了解決這種問題,kylin對dimession做了分類,見下文。
### 2.dimession
為了減少cuboid的數量,kylin對dimession做了如下分類
normal
mandatory:每次查詢均會使用到的dimession,在下圖中A為Mandatory dimension,則與B、C總共構成了4個cuboid,相較於normal dimension的cuboid(2^3^=8)減少了一半。
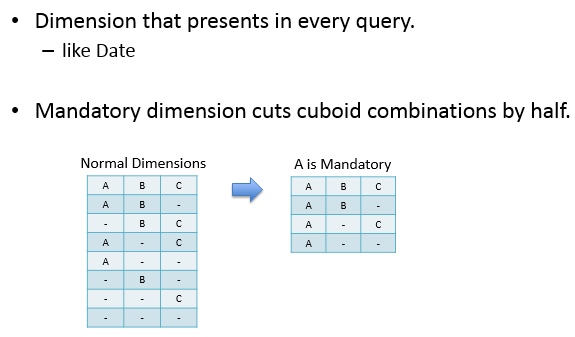
在實際生產應用中,比如對於日報表的分析,可能日期就是一個mandatory dimession。
hierarchy:帶層級的dimession,如:年->月->日,要求子級的父級必須存在。如下的例子中cuboid由2^n^降為了n+1。
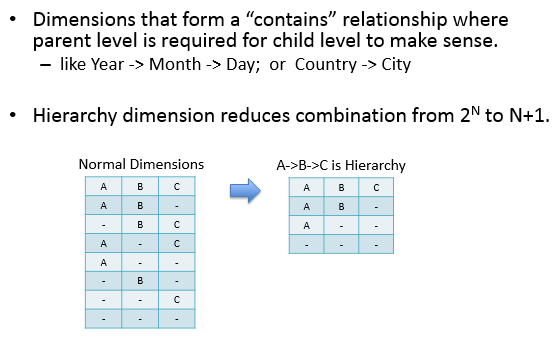
然而,Kylin的Hierarchy dimensions並沒有做集合包含約束,比如:kylin_sales_cube定義Hierarchy dimension為META_CATEG_NAME->CATEG_LVL2_NAME->CATEG_LVL3_NAME,但是同一個CATEG_LVL2_NAME可以對應不同META_CATEG_NAME。因此,hierarchy 顯得非常雞肋,以至於在Kylin後臺處理時被廢棄了。
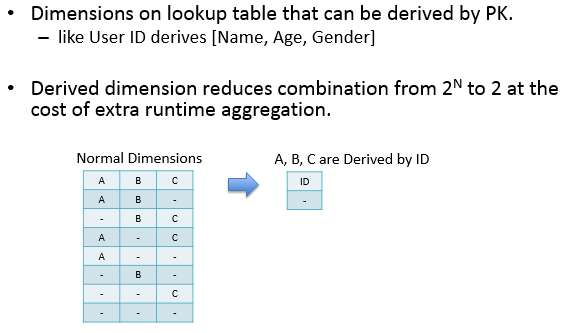
derived
### 3.measure
measure為事實表的度量值,kylin提供了下面幾個函式:
sum,count,max,min,avarage,count_distinct
其中count_distinct有兩種實現方式:
(1)近似Count Distinct。Apache Kylin使用HyperLogLog演算法實現了近似Count Distinct,提供了錯誤率從9.75%到1.22%幾種精度供選擇;
演算法計算後的Count Distinct指標,理論上,結果最大隻有64KB,最低的錯誤率是1.22%;這種實現方式用在需要快速計算、節省儲存空間,並且能接受錯誤率的Count Distinct指標計算。
(2)準Count Distinct。從1.5.3版本開始,Kylin中實現了基於bitmap的精確Count Distinct計算方式。當資料型別為tiny int(byte)、small int(short)以及int,
會直接將資料值對映到bitmap中;當資料型別為long,string或者其他,則需要將資料值以字串形式編碼成dict(字典),再將字典ID對映到bitmap;
指標計算後的結果,並不是計數後的值,而是包含了序列化值的bitmap.這樣,才能確保在任意維度上的Count Distinct結果是正確的。
這種實現方式提供了精確的無錯誤的Count Distinct結果,但是需要更多的儲存資源,如果資料中的不重複值超過百萬,結果所佔的儲存應該會達到幾百MB。